手动解析Excel获取文件元数据
工作中有遇到需要获取上传的Excel文件的列明、最大行数、大小等元数据信息。通常做法是通过Apache的POI工具加载文件然后再读取行列进行处理。这种方法很大的弊端就是需要把excel文件加载到内存,如果遇到大的文件,内存暴增,很容易出现OOM。为了解决这个问题,我研究了excel文件的格式,写了一工具类来自己解析和获取这些信息。
一、excel文件格式解析
其实xls、xlsx格式的文件其实就是一个压缩包,我们找一个excel文件,把后缀改成.rar,然后解压,你会发现文件夹里面大概是这样的:
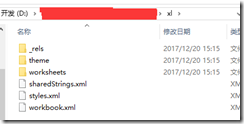
其中关键的是xl这个文件夹,看第二张图:
1、workbook.xml 里面包含了sheet的信息,比如有几个sheet,每一个的名称是什么
2、sharedString.xml 老重要了,里面就是包含了整个excel文件中单元格中的内容,excel是通过索引来引用内容的。
3、worksheets 文件夹里面包含了sheet内容的定义
看第三张图,sheet1.xml表示第一个sheet的定义,其内容是这样的:
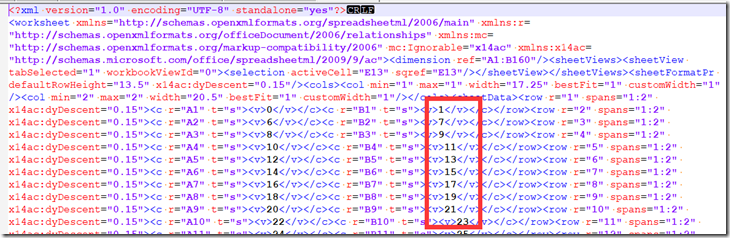
看到那些数字了吗,其实表示这个单元格的内容在sharedString.xml中的索引。
二、示例代码实现
接下来我将展示一个获取excel文件中列名称、行数、sheet名称的java代码。
import java.io.File;
import java.io.RandomAccessFile;
import java.io.UnsupportedEncodingException;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* excel文件元数据读取工具
*
* @author yuananyun
* @date 2017/11/16 14:20
**/
public class ExcelXmlUtil {
//获取第一个sheet的名称的表达式
private static Pattern firstSheetPattern = Pattern.compile("sheet name=\"(.*?)\" sheetId=\"1\"");
//抽取一行的表达式,如
//<row r="200001" spans="1:2" s="1" customFormat="1" x14ac:dyDescent="0.15">/row>
private static Pattern rowPattern = Pattern.compile("<row(.*?)></row>");
//求解一行行号的表达式
private static Pattern rowNumPattern = Pattern.compile("r=\"(\\d+)\"");
//求解标题列个数的表达式
private static Pattern columnCountPattern = Pattern.compile("</v>");
//求解列标题索引的表达式
private static Pattern columnIndexPattern = Pattern.compile("<v>(\\d*)</v>");
//求解列标题名称的表达式
private static Pattern titleValuePattern = Pattern.compile("(?:(?:<t>)|(?:<t xml:space=\".*\">))([\\s\\S]*?)</t>"); static class ExcelRowColumnInfo {
private long maxRowNum;
private int coluntCount;
private List<String> titleList;
private String firstSheetName; public ExcelRowColumnInfo(String firstSheetName, int maxRowNum, int coluntCount, List<String> titleList) {
this.firstSheetName = firstSheetName;
this.maxRowNum = maxRowNum;
this.coluntCount = coluntCount;
this.titleList = titleList;
} public long getMaxRowNum() {
return maxRowNum;
} public void setMaxRowNum(int maxRowNum) {
this.maxRowNum = maxRowNum;
} public int getColuntCount() {
return coluntCount;
} public void setColuntCount(int coluntCount) {
this.coluntCount = coluntCount;
} public List<String> getTitleList() {
return titleList == null ? new ArrayList<>() : titleList;
} public void setTitleList(List<String> titleList) {
this.titleList = titleList;
} public String getFirstSheetName() {
return firstSheetName;
} public void setFirstSheetName(String firstSheetName) {
this.firstSheetName = firstSheetName;
} @Override
public String toString() {
return "ExcelRowColumnInfo{" +
"maxRowNum=" + maxRowNum +
", coluntCount=" + coluntCount +
", titleList=" + titleList.toString() +
'}';
}
} /**
* 获取excel文件的行列个数
*
* @param excelFilePath
* @param isOverwrite 是否覆盖源excel文件
* @return ExcelRowColumnInfo
*/
public static ExcelRowColumnInfo getRowAndColumnInfo(String excelFilePath, boolean isOverwrite) {
try {
File excelFile = new File(excelFilePath);
if (!excelFile.exists()) return null;
String zipFilePath = excelFilePath.replace(".xlsx", ".zip").replace(".xls", ".zip");
File zipFile = new File(zipFilePath);
if (zipFile.exists()) zipFile.delete();
if (isOverwrite) {
//直接重命名
excelFile.renameTo(zipFile);
} else {
// 复制文件
FileUtil.copyFile(excelFilePath, zipFilePath);
}
//解压的临时目录
String tmpDir = zipFilePath.replace(".zip", "");
List<File> fileList = ZipUtils.upzipFile(zipFile, tmpDir);
File sheet1File = null;
File sharedStringsFile = null;
File workbookFile = null;
for (File file : fileList) {
if (file.getPath().contains("sheet1.xml"))
sheet1File = file;
if (file.getPath().contains("sharedStrings.xml"))
sharedStringsFile = file;
if (file.getPath().contains("workbook.xml"))
workbookFile = file;
}
if (sheet1File == null || sharedStringsFile == null) return null; //抽取sheet名称
String sheetName = parseFirstSheetName(workbookFile); int[] rcArray = parseMaxRowNumAndColCount(sheet1File);
int maxRowNum = rcArray[0];
// int columCount = rcArray[1]; int[] titleIndexArray = parseTitleIndexArray(sheet1File);
List<String> titleList = parseTitleList(sharedStringsFile, titleIndexArray); deleteFileRecursively(zipFile);
deleteFileRecursively(new File(tmpDir)); if (titleList == null || titleList.size() == 0 || maxRowNum == 0) return null; return new ExcelRowColumnInfo(sheetName, maxRowNum, titleList.size(), titleList);
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
} /**
* 解析第一个sheet的名称
*
* @param workbookFile
* @return
*/
private static String parseFirstSheetName(File workbookFile) {
String content = getFileSegment(workbookFile, 0, Integer.MAX_VALUE);
Matcher matcher = firstSheetPattern.matcher(content);
if (matcher.find())
return matcher.group(1);
return null;
} /**
* 求解标题列关键字所在的索引
*
* @param sheet1File
* @return
*/
private static int[] parseTitleIndexArray(File sheet1File) {
int realColCount = 0;
String startSegment = getFileSegment(sheet1File, 2000);
if (startSegment != null) {
//求解真实的列数
Matcher matcher = rowPattern.matcher(startSegment);
if (matcher.find()) {
String firstRow = matcher.group(1);
if (firstRow != null) {
matcher = columnCountPattern.matcher(firstRow);
while (matcher.find())
realColCount++;
}
}
if (realColCount > 0) {
//求解标题
int[] titleIndexArray = new int[realColCount];
matcher = columnIndexPattern.matcher(startSegment);
int i = 0;
while (matcher.find() && i < realColCount) {
titleIndexArray[i++] = Integer.parseInt(matcher.group(1));
}
return titleIndexArray;
}
}
return null;
} /**
* 解析excel文件的标题列名称
*
* @param sharedStringsFile
* @param titleIndexArray
* @return
*/
private static List<String> parseTitleList(File sharedStringsFile, int[] titleIndexArray) {
List<String> titleList = new ArrayList<>();
int count = titleIndexArray.length;
if (count > 0) {
int minIndex = Integer.MAX_VALUE;
int maxIndex = Integer.MIN_VALUE;
for (int i = 0; i < count; i++) {
int index = titleIndexArray[i];
if (index > maxIndex) maxIndex = index;
if (index < minIndex) minIndex = index;
}
//885是头部的长度,限制每个row长度为200字符
// int length = (885 + (maxIndex - minIndex + 1) * 200);
//标题真的是到处都在,
String[] titleArray = new String[count];
// if (minIndex > 10000) {
// //这是一个大文档,整篇加载
// length = Integer.MAX_VALUE;
// }
String segment = getFileSegment(sharedStringsFile, 0, Integer.MAX_VALUE);
Matcher matcher = titleValuePattern.matcher(segment);
int i = 0;
while (matcher.find() && count > 0) {
String value = matcher.group(1);
// System.out.println(i + " ------> " + value);
for (int j = 0; j < titleIndexArray.length; j++) {
if (i == titleIndexArray[j]) {
titleArray[j] = value;
count--;
break;
}
}
i++;
}
if (titleArray.length > 0) {
Collections.addAll(titleList, titleArray);
//去掉空格单元格
Collections.reverse(titleList);
for (int i1 = 0; i1 < titleList.size(); i1++) {
String title = String.valueOf(titleList.get(i1));
if ("".equals(title.trim()))
titleList.remove(i1);
}
Collections.reverse(titleList);
}
}
return titleList;
} /**
* 解析文件的最大行号和列数
*
* @param sheet1File
* @return
*/
private static int[] parseMaxRowNumAndColCount(File sheet1File) {
int rowNum = 0, colCount = 0;
String endSegment = getFileSegment(sheet1File, -1000);
if (endSegment != null) {
Matcher matcher = rowPattern.matcher(endSegment);
String lastRow = "";
while (matcher.find()) {
lastRow = matcher.group(1);
}
if (lastRow.length() > 0) {
matcher = rowNumPattern.matcher(lastRow);
if (matcher.find())
rowNum = Integer.parseInt(matcher.group(1));
matcher = columnCountPattern.matcher(lastRow);
while (matcher.find())
colCount++;
}
}
return new int[]{rowNum, colCount};
} /**
* 递归删除文件及文件夹
*
* @param file
*/
private static void deleteFileRecursively(File file) {
if (file.exists()) {
if (file.isFile()) {
file.delete();
} else if (file.isDirectory()) {
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
deleteFileRecursively(files[i]);
}
file.delete();
}
}
} private static String getFileSegment(File file, int length) {
return getFileSegment(file, 0, length);
} /**
* 从一个文件中截取一段字符串
*
* @param file
* @param offset
* @param length length<0时,offset将失效
* @return
*/
private static String getFileSegment(File file, long offset, int length) {
if (file == null || !file.exists()) return null;
try {
Charset charset = Charset.forName("UTF-8");
CharsetDecoder decoder = charset.newDecoder(); StringBuilder builder = new StringBuilder();
RandomAccessFile aFile = new RandomAccessFile(file, "r");
FileChannel inChannel = aFile.getChannel();
if (inChannel != null) {
if (Integer.MAX_VALUE == length)
length = (int) inChannel.size();
ByteBuffer buf = ByteBuffer.allocate(Math.abs(length));
if (length < 0)
offset = inChannel.size() + length;
int size = Math.abs(length);
inChannel.position(offset < 0 ? 0 : offset);
int bytesRead = inChannel.read(buf);
while (bytesRead != -1 && size > 0) {
buf.flip();
CharBuffer charBuffer = decoder.decode(buf);
builder.append(charBuffer);
buf.clear();
bytesRead = inChannel.read(buf);
size = size - bytesRead;
}
inChannel.close();
}
aFile.close();
return builder.toString();
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
} /**
* 测试
* @param args
* @throws UnsupportedEncodingException
*/
public static void main(String[] args) throws UnsupportedEncodingException {
ExcelRowColumnInfo result;
result = getRowAndColumnInfo("D:\\元数据求解.xls", false);
System.out.println(result);
} }
用到的几个工具类:
/**
* 文件复制
* @param srcFilePath
* @param destFilePath
* @return
*/
public static String copyFile(String srcFilePath, String destFilePath){ if (StringUtils.isEmpty(srcFilePath) || StringUtils.isEmpty(destFilePath)){
return null;
}
File srcFile = new File(srcFilePath);
File destFile = new File(destFilePath);
if (!srcFile.exists() || srcFile.isDirectory()){
return null;
}
try {
if (!destFile.exists()) {
destFile.createNewFile();
}
FileUtils.copyFile(srcFile, destFile);
return destFilePath;
} catch (IOException e){
e.printStackTrace();
}
return null;
} /**
* 对.zip文件进行解压缩
*
* @param zipFile 解压缩文件
* @param descDir 解压缩的目标地址,如:D:\\测试 或 /mnt/d/测试
* @return
*/
@SuppressWarnings("rawtypes")
public static List<File> upzipFile(File zipFile, String descDir) {
List<File> _list = new ArrayList<File>();
try {
ZipFile _zipFile = new ZipFile(zipFile, "GBK");
for (Enumeration entries = _zipFile.getEntries(); entries.hasMoreElements(); ) {
ZipEntry entry = (ZipEntry) entries.nextElement();
File _file = new File(descDir + File.separator + entry.getName());
if (entry.isDirectory()) {
_file.mkdirs();
} else {
File _parent = _file.getParentFile();
if (!_parent.exists()) {
_parent.mkdirs();
}
InputStream _in = _zipFile.getInputStream(entry);
OutputStream _out = new FileOutputStream(_file);
int len = 0;
while ((len = _in.read(_byte)) > 0) {
_out.write(_byte, 0, len);
}
_in.close();
_out.flush();
_out.close();
_list.add(_file);
}
}
_zipFile.close();
} catch (IOException e) {
}
return _list;
}
其中zip用的是
org.apache.tools.zip.ZipEntry;
手动解析Excel获取文件元数据的更多相关文章
- 如何手动解析vue单文件并预览?
开头 笔者之前的文章里介绍过一个代码在线编辑预览工具的实现(传送门:快速搭建一个代码在线编辑预览工具),实现了css.html.js的编辑,但是对于demo场景来说,vue单文件也是一个比较好的代码组 ...
- Bash Shell 解析路径获取文件名称和文件夹名
前言 还是今天再写一个自己主动化打包脚本.用到了从路径名中获取最后的文件名称.这里记录一下实现过程. 当然,最后我也会给出官方的做法.(ps:非常囧,实现完了才发现原来Bash Shell有现成的函数 ...
- SpringBoot基于EasyExcel解析Excel实现文件导出导入、读取写入
1. 简介 Java解析.生成Excel比较有名的框架有Apache poi.jxl.但他们都存在一个严重的问题就是非常的耗内存,poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题 ...
- java 使用 poi 解析excel
背景: web应用经常需要上传文件,有时候需要解析出excel中的数据,如果excel的格式没有问题,那就可以直接解析数据入库. 工具选择: 目前jxl和poi可以解析excel,jxl很早就停止维护 ...
- linux系统编程之文件与IO(五):stat()系统调用获取文件信息
一.stat()获取文件元数据 stat系统调用原型: #include <sys/stat.h> int stat(const char *path, struct stat *buf) ...
- java读写excel文件( POI解析Excel)
package com.zhx.base.utils; import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi ...
- Java:JXL解析Excel文件
项目中,有需求要使用JXL解析Excel文件. 解析Excel文件 我们先要将文件转化为数据流inputStream. 当inputStream很大的时候 会造成Java虚拟器内存不够 抛出内存溢出 ...
- 解析Excel文件并把数据存入数据库
前段时间做一个小项目,为了同时存储多条数据,其中有一个功能是解析Excel并把其中的数据存入对应数据库中.花了两天时间,不过一天多是因为用了"upload"关键字作为URL从而导致 ...
- Java通过jxl解析Excel文件入库,及日期格式处理方式 (附源代码)
JAVA可以利用jxl简单快速的读取文件的内容,但是由于版本限制,只能读取97-03 xls格式的Excel. 本文是项目中用到的一个实例,先通过上传xls文件(包含日期),再通过jxl进行读取上传 ...
随机推荐
- spark练习——影评案例
第一次写博客,新人上路,欢迎大家多多指教!!! ---------------------------------------------------------------------分割线---- ...
- 关于Modelsim SE软件Fatal License Error的解决方法
操作环境:Win7 32位系统 软件版本:Modelsim SE 10.1a Modelsim SE软件有时会弹出如图1所示“Fatal License Error”的提示信息,原因可能是软件破解不彻 ...
- 用uliweb 创建项目
创建项目 ***@Android:~# uliweb makeproject ablog ***@Android:~# cd ablog/ ***@Android:~/ablog# ls apps f ...
- 单调性优化DP
单调性优化DP Tags:动态规划 作业部落链接 一.概述 裸的DP过不了,怎么办? 通常会想到单调性优化 单调队列优化 斜率优化 决策单调性 二.题目 [x] 洛谷 P2120 [ZJOI2007] ...
- 微信小程序:设置页面计时自动跳转
一.功能描述 当出发某一事件后,希望在规定的时间后自动执行另一事件,比如页面跳转功能. 二.代码实现 使用setTimeout函数,单位为毫秒ms setTimeout(function(){ wx. ...
- Codeforces 909 D. Colorful Points (模拟)
题目链接: Colorful Points 题意: 给出一段字符串(长度最大为1e6),每次操作可以删除字符串中所有相邻字符与其不同的字符.例如:aabcaa 删除一次就变成了aa,就无法再删除了.题 ...
- python中偏函数的应用
一.什么是偏函数? (1)在Python的functools模块众多的功能中,其中有一个就是偏函数,我们称之为 partial function 模块的概念我们下一篇在细讲. (2)我们都听过偏将军吧 ...
- CI/CD系列
一.CI/CD系列 什么是CI/CD(译) Docker与CI/CD(转) Docker和CI/CD实战 二.Git 三.GitLab
- 经典笔试题:用C写一个函数测试当前机器大小端模式
“用C语言写一个函数测试当前机器的大小端模式”是一个经典的笔试题,如下使用两种方式进行解答: 1. 用union来测试机器的大小端 #include <stdio.h> union tes ...
- Unity3D — —存读档【转载】
详细可参考此篇博文: Unity序列化之XML,JSON--------合成与解析 简单例子(SiKi学院教程): using System.Collections; using System.Col ...