推荐算法-聚类-K-MEANS
对于大型的推荐系统,直接上协同过滤或者矩阵分解的话可能存在计算复杂度过高的问题,这个时候可以考虑用聚类做处理,其实聚类本身在机器学习中也常用,属于是非监督学习的应用,我们有的只是一组组数据,最终我们要把它们分组,但是前期没有任何的先验知识告诉我们那个点是属于那个组的。
当我们有足够的数据的时候可以考虑先用聚类做第一步处理,来缩减协同过滤的选择范围,从而降低复杂度。
对了还想起来机器学习里面也经常用聚类的方式进行降维。这个在机器学习笔记部分后期我会整理。
最终,每个聚类中的用户,都会收到为这个聚类计算出的推荐内容。聚类的话也有很多种方法时间,今天是整理最简单的那个姿势:K-MEANS
K-MEANS聚类算法是非常常用的聚类算法。它出现在很多介绍性的数据科学和机器学习课程中。在代码中很容易理解和实现!
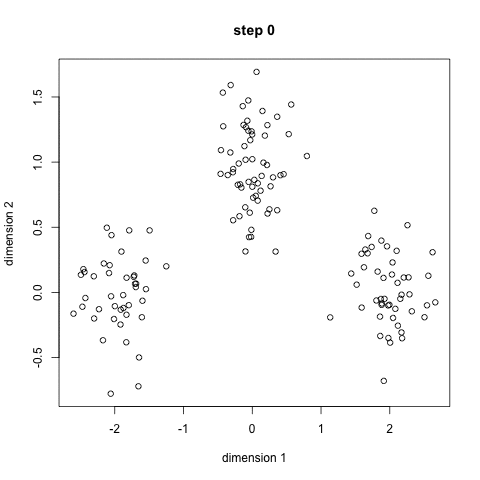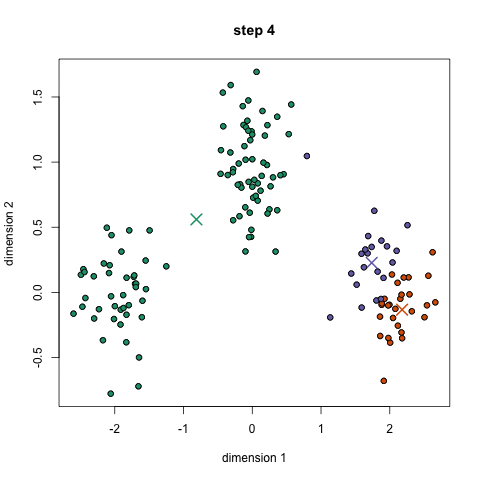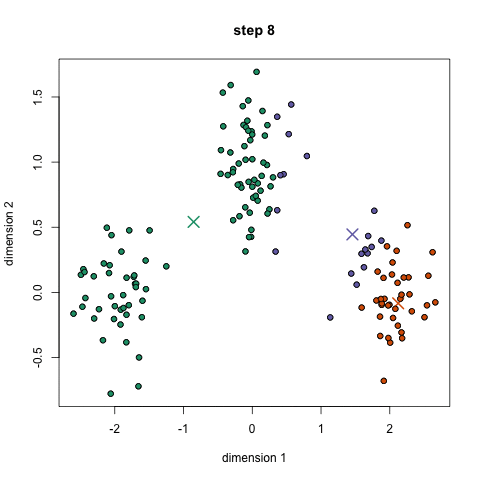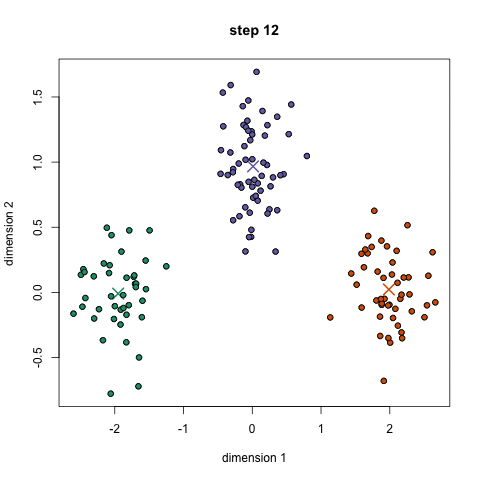
- 首先,选择一些类/组来使用并随机地初始化它们各自的中心点。要想知道要使用的类的数量,最好快速地查看一下数据,并尝试识别任何不同的分组。中心点是与每个数据点向量相同长度的向量,在上面的图形中是“X”。
- 每个数据点通过计算点可每个组中心之间的距离进行分类,然后将这个点分类为最接近它的组。
- 基于这些分类点,我们通过去组中所有向量的均值来重新计算中心。
- 对一组迭代重复这些步骤。你还可以选择随机初始化组中心几次,然后选择那些看起来对他提供好结果的来运行。
K-MEANS聚类算法的优势在于它的速度非常快,因为我们所有的只是计算点和集群中心之间的距离,它有一个线性复杂度O(n)[注意不是整体的时间复杂度]。
另一方面,K-MEANS也有几个缺点。首先,你必须选择有多少组/类。这并不是不重要的事,理想情况下,我们希望它能帮我门解决这些问题,因为他的关键在于从数据中国的一些启示,K-MEANS也从随机的聚类中心开始,因此在不同的算法运行中可能产生不同的聚类结果。因此,结果可能是不可重复的,并且缺乏一致性。其他聚类方法更加一致。
K-Medians是另一种与K-MEANS有关的聚类算法,除了使用均值的中间值来重新计算数组中心点以外,这种方法对于离散值的民高度较低(因为使用中值),但对于较大的数据集来说,它要慢得多,因为在计算中值向量时,每次迭代都需要进行排序。
推荐算法-聚类-K-MEANS的更多相关文章
- 推荐算法-聚类-DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,类似于均值转移聚类算法,但 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法
聚类算法 概述 无监督问题 手中无标签 聚类 将相似的东西分到一组 难点 如何 评估, 如何 调参 基本概念 要得到的簇的个数 - 需要指定 K 值 质心 - 均值, 即向量各维度取平均 距离的度量 ...
- apriori推荐算法
大数据时代开始流行推荐算法,所以作者写了一篇教程来介绍apriori推荐算法. 推荐算法大致分为: 基于物品和用户本身 基于关联规则 基于模型的推荐 基于物品和用户本身 基于物品和用户本身的,这种推荐 ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- 推荐算法相关总结表(包括DM)
推荐算法总结表 表1 推荐算法分类 个性化推荐算法分类 启发式算法 基于模型 基于内容 TF-IDF 聚类 最大熵 相似度度量 贝叶斯分类 决策树 神经网络 专家系统 知识推理 协同过滤 K近邻 聚类 ...
- 推荐算法之用矩阵分解做协调过滤——LFM模型
隐语义模型(Latent factor model,以下简称LFM),是推荐系统领域上广泛使用的算法.它将矩阵分解应用于推荐算法推到了新的高度,在推荐算法历史上留下了光辉灿烂的一笔.本文将对 LFM ...
随机推荐
- strick-footer 粘边布局
当网页缩小, 缩放到一定高度时(这个高度就是页面内容高度)footer的页尾自动消失,这个就叫做粘边布局 strick-footer 粘边布局基本思路: 主体{ height:100%; } 内容体{ ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 漏洞复现-CVE-2017-4971-Spring Web Flow 远程代码执行
0x00 实验环境 攻击机:Win 10 靶机也可作为攻击机:Ubuntu18 (docker搭建的vulhub靶场)(兼顾反弹shell的攻击机) 0x01 影响版本 Spring ...
- mysql数据库的数据备份,以及开启日志
导出数据: location代表需要保存的数据文件的位置,默认保存在 C:\ProgramData\MySQL\MySQL Server 5.7\Data(Windows10系统位置,其他系统位置自行 ...
- .NET 6 Preview 2 发布
前言 在 2021 年 3 月 11 日, .NET 6 Preview 2 发布,这次的改进主要涉及到 MAUI.新的基础库和运行时.JIT 改进. .NET 6 正式版将会在 2021 年 11 ...
- POJ1979_Red and Black(JAVA语言)
思路:bfs裸题. 对这种迷宫问题的bfs,我们把坐标点用一个class来存储,并放入队列进行求解. //一直接收不了输入,找了一个多小时的问题,居然是行和列搞反了ORZ Red and Black ...
- java例题_35 找到最大值和最小值并交换位置
1 /*35 [程序 35 最大最小交换] 2 题目:输入数组,最大的与第一个元素交换,最小的与最后一个元素交换,输出数组. 3 */ 4 5 /*分析 6 * 1.先初始化一个数组,然后从键盘获得值 ...
- java例题_24 逆向输入数字
1 /*24 [程序 24 根据输入求输出] 2 题目:给一个不多于 5 位的正整数,要求:一.求它是几位数,二.逆序打印出各位数字. 3 */ 4 5 /*分析 6 * 首先从键盘得到一个正整数,不 ...
- c++一些概念
面向对象语言三大特征: 封装,多态,继承 封装: 1.将函数定义到结构体内部,就是封装. 2.编译器会自动传递结构体的指针给函数. 类: 带有函数的结构体,称为类. 成员函数: 结构体里面的函数,称为 ...
- [树状数组]数星星 Stars
数 星 星 S t a r s 数星星 Stars 数星星Stars 题目描述 天空中有一些星星,这些星星都在不同的位置,每个星星有个坐标.如果一个星星的左下方(包含正左和正下)有 k k k 颗星星 ...