ScienceDirect内容爬虫
爬虫违法,本贴方法只限于个人对数据的分析使用,其爬虫程序已作相关设置,以减小服务器压力。不适宜长期使用。
一、前期准备
1、使用chrome打开ScienceDirect网站(https://www.sciencedirect.com),在搜索框输入想要查询的关键词再点击放镜按钮搜索,比如:extreme water level
2、在新跳转搜索结果列表页面打开浏览器的开发者工具(右键点击-查看网页源代码),搜索我们想要的内容,比如文章标题,看看是否能搜到。如果能搜索到表明我们需要的内容在html中,如果没有,那么这个网站很可能采用前后端分离的技术,我们所需要的数据很可能在json中,这种情况则需要找接口来获取。
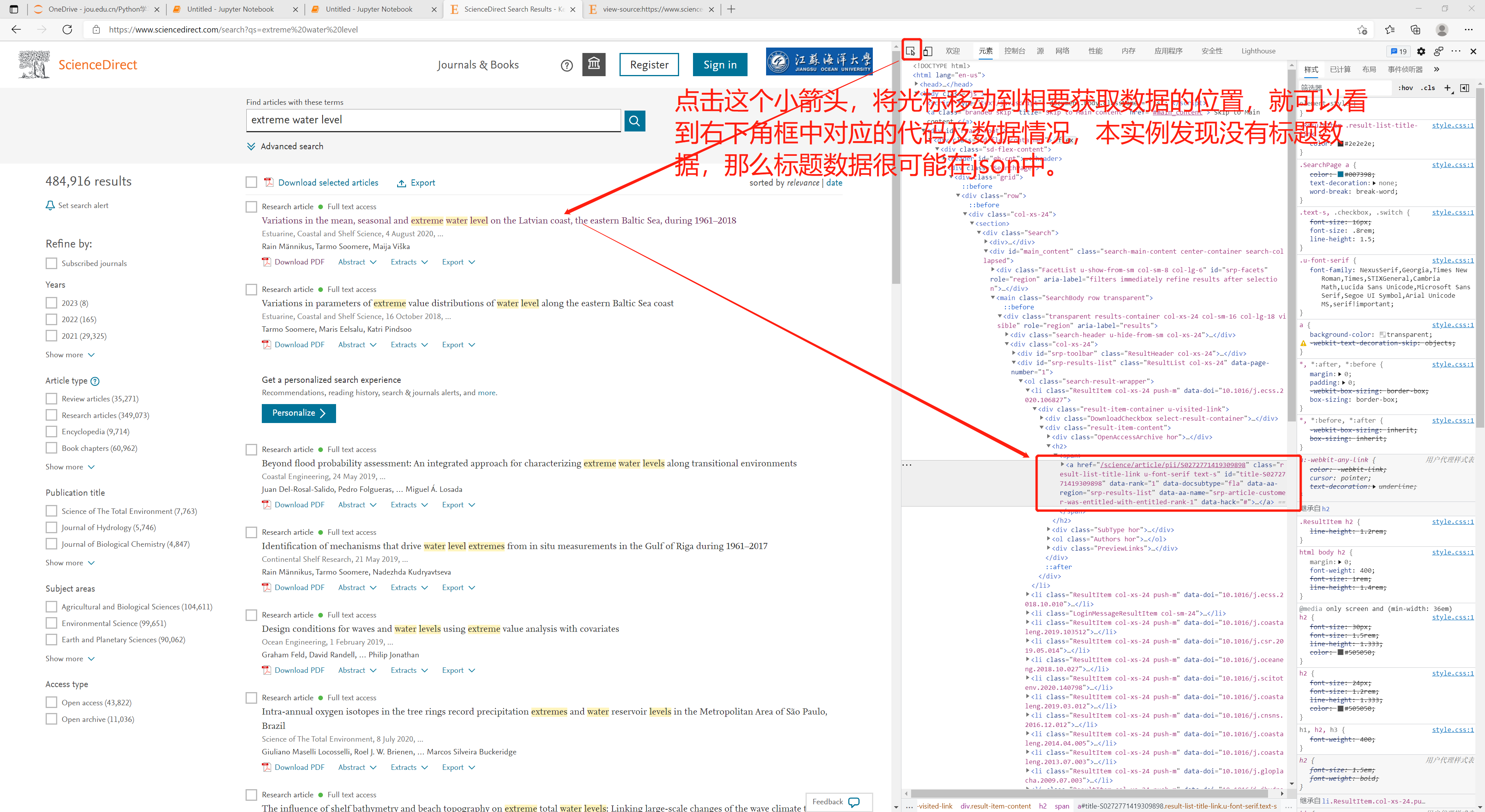
3、通过查看源代码发现没有我们想要的数据。那么再试试看是否在json中,方法是在搜索列表页面右键-检查-网络-刷新浏览器以抓包-找出可能的数据包(查看preview标签)
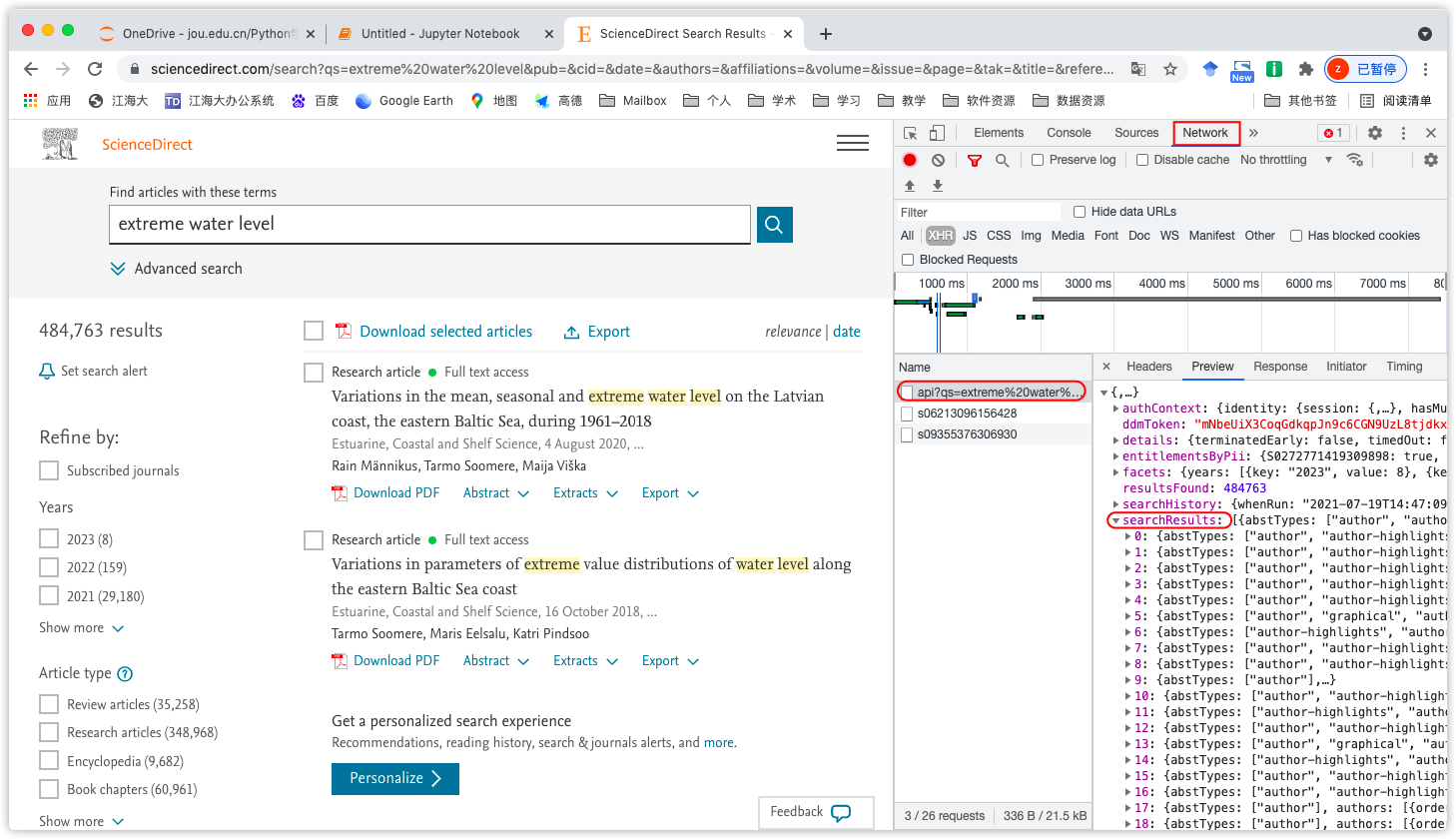
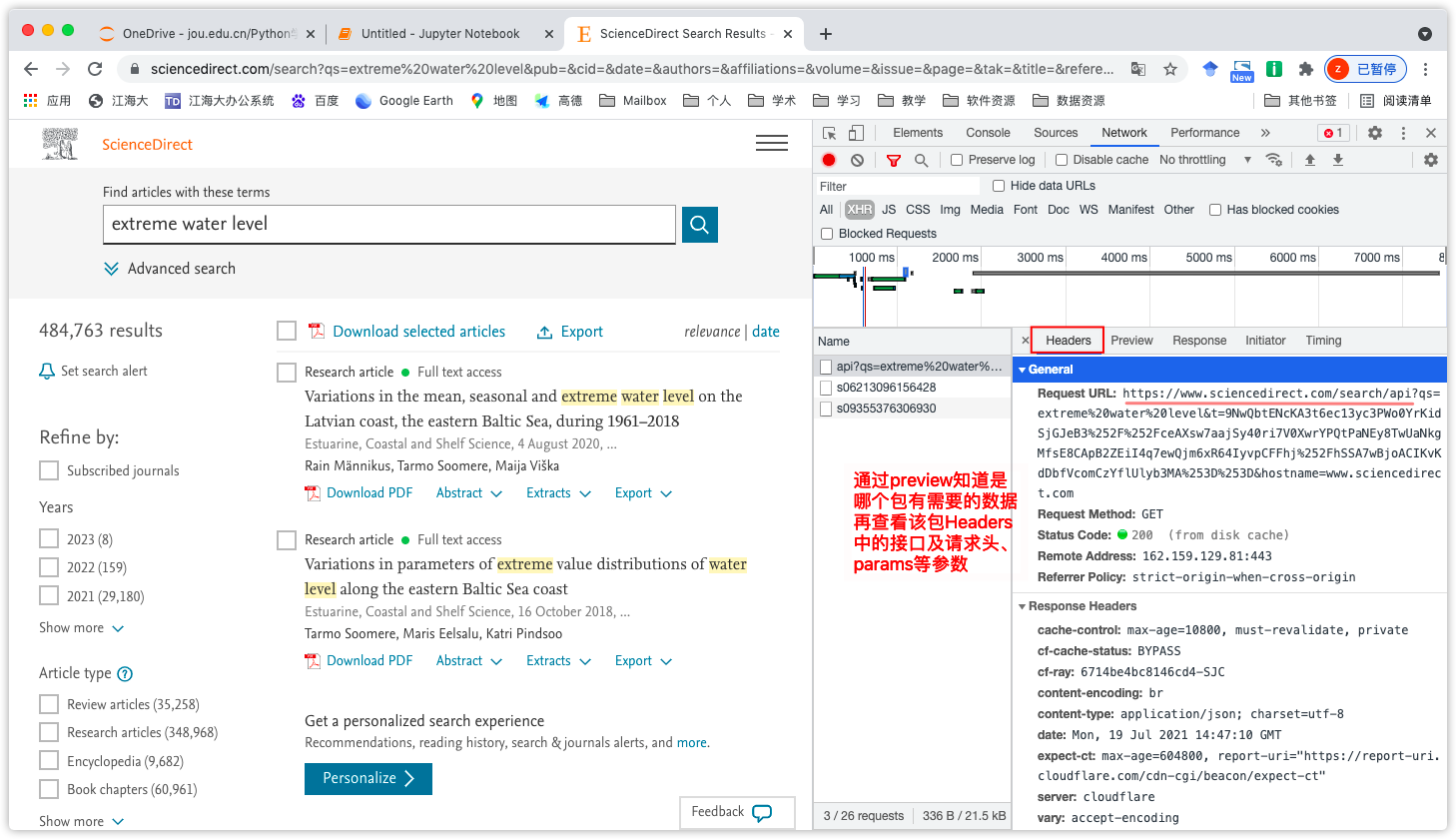
得到接口为:https://www.sciencedirect.com/search/api
二、开始程序获取
1、首先导入必要库(有的库在本次实例中不一定用上)
1 import requests
2 import json,re,os
3 from bs4 import BeautifulSoup
4 from urllib.parse import quote
2、实际上这里还可以通过html的方式,尝试看看能否获取到数据
第1行:我们查询的关键词
第2行:前半部分的网址是搜索列表页面的地址,其中的quote(key)是将其转为浏览器中的编码格式。
第3行:是为了防止反爬虫而设置的
第7行:获取html数据
第8行:防止因为编码问题出现乱码情况
第9行:用BeautifulSoup解析html,方便对数据切片,因为html为字符串类型数据,不太方便定位数据位置
第10行:定位标题内容的类位置,(通过上面的元素标签中定位的方法,找出标题内容对应的类位置)
第11行:打印查看是否有内容,结果为一个空的列表,表明没有数据
1 key = 'extreme water level'
2 url = 'https://www.sciencedirect.com/search?qs='+quote(key)
3 headers = {
4 'cookie': 'search_ab=%7B%221%22%3A23%7D; sd_search=eyJhdXRoSGlzdG9yeSI6eyJwcmV2aW91c0N1c3RvbWVyIjp0cnVlLCJwcmV2aW91c0xvZ0luIjpmYWxzZX19.uRn%2Fj4TgvLEmApohDX%2FmiA2G8WsVm1yImoH3Mot2ZxY; EUID=5a74edc0-f0c2-4918-a17a-66731930dc86; id_ab=AEG; sd_session_id=012e12f879e18845c30b0a9170ac4912ea42gxrqa; acw=012e12f879e18845c30b0a9170ac4912ea42gxrqa%7C%24%7C7655A62AC882D5B269BB32EC1CC1FA66BFB036F913742AB6843F53CFFBCDE26B054E9D90CFD61FB88103979492FFB4EA4ACF86F54EABC9A63FBA44D1BD4E4F2EAFE9C31A29ED2080B6DA1F7CB1786ABB; ANONRA_COOKIE=AC4FAB305B9736FF9E8F009F581F56B5B5BD34D45FE243EBB2FAC7271249E9F096D5E4A555833E115E4A5D76175BE9945F2CB26604FED07A; has_multiple_organizations=false; __cf_bm=6ee31fd3af4f560d4d5d0906c971f77575face0b-1626413997-1800-AXcVXU6yJAqWmH+hPTzES7cu4h8ITDKR9SaZsBJK1MgUadBZjqCsmSDCdmc0zHagqGT1PM9GDgr1k0mS1T76Gb6SE5IQHj24mXluDvZ+eHDK; fingerPrintToken=e1fe7953298449ebbfc118c358a167eb; AMCVS_4D6368F454EC41940A4C98A6%40AdobeOrg=1; AMCV_4D6368F454EC41940A4C98A6%40AdobeOrg=-1124106680%7CMCIDTS%7C18824%7CMCMID%7C12297380359548630414269390810591070709%7CMCAID%7CNONE%7CMCOPTOUT-1626421207s%7CNONE%7CMCAAMLH-1627018807%7C11%7CMCAAMB-1627018807%7Cj8Odv6LonN4r3an7LhD3WZrU1bUpAkFkkiY1ncBR96t2PTI%7CMCCIDH%7C-582229202%7CMCSYNCSOP%7C411-18831%7CvVersion%7C5.2.0; s_pers=%20v8%3D1626414014787%7C1721022014787%3B%20v8_s%3DLess%2520than%25201%2520day%7C1626415814787%3B%20c19%3Dsd%253Asearch%253Aresults%253Acustomer-standard%7C1626415814789%3B%20v68%3D1626414007149%7C1626415814795%3B; MIAMISESSION=deb5a6e8-4414-46d9-b806-916bfbb38018:3803866821; SD_REMOTEACCESS=eyJhY2NvdW50SWQiOiI2MjYyNiIsInRpbWVzdGFtcCI6MTYyNjQxNDAyMTI4NX0=; s_sess=%20s_cpc%3D1%3B%20s_cc%3Dtrue%3B%20s_ppvl%3D%3B%20c21%3Dqs%253Dwater%2520level%3B%20e13%3Dqs%253Dwater%2520level%253A1%3B%20c13%3Drelevance-desc%3B%20e41%3D1%3B%20s_ppv%3Dsd%25253Asearch%25253Aresults%25253Acustomer-standard%252C18%252C18%252C801%252C813%252C801%252C1368%252C912%252C2%252CP%3B',
5 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67'
6 }
7 html = requests.get(url,headers=headers)
8 html.encoding=html.apparent_encoding
9 soup = BeautifulSoup(html.text,'lxml')
10 results = soup.select('.ResultItem.col-xs-24.push-m')
11 print(results)
3、通过json方法获取
第6行:参数需要在找到的包的Header标签中获取
再打印html可以发现存在数据,那么可以成功获取数据了
1 key = 'extreme water level'
2 url = 'https://www.sciencedirect.com/search/api'
3 headers = {
4 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70'
5 }
6 params = {
7 'qs': key,
8 't': '9NwQbtENcKA3t6ec13yc3J0oVqdNg1DW8FkZ4fWmlbcNo377tsI2SJxXzbXzVwMMUWW%2BAzqQnWkVBhGgXl1YEZB2ZEiI4q7ewQjm6xR64IyvpCFFhj%2FhSSA7wBjoACIKvKdDbfVcomCzYflUlyb3MA%3D%3D',
9 'hostname': 'www.sciencedirect.com'
10 }
11 html = requests.get(url,headers=headers,params=params)
4、以下是完整代码:
为了防止给服务器造成压力,这里我们对for循环设置间隔一定的时间,首先导入相关包
import time
import random
第12行:是将json格式转化为python中的字典格式
第13行:在2-6(不包括6)之间随机生成一个整数,time.sleep(**),表示程序暂停,括号中的数值表示暂停的时间(秒)
for循环中的标题、出版日等字段都是在网页json包中的preview中查询到的。
1 key = 'extreme water level'
2 url = 'https://www.sciencedirect.com/search/api'
3 headers = {
4 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70'
5 }
6 params = {
7 'qs': key,
8 't': '9NwQbtENcKA3t6ec13yc3J0oVqdNg1DW8FkZ4fWmlbcNo377tsI2SJxXzbXzVwMMUWW%2BAzqQnWkVBhGgXl1YEZB2ZEiI4q7ewQjm6xR64IyvpCFFhj%2FhSSA7wBjoACIKvKdDbfVcomCzYflUlyb3MA%3D%3D',
9 'hostname': 'www.sciencedirect.com'
10 }
11 html = requests.get(url,headers=headers,params=params)
12 data = json.loads(html.text)['searchResults']
13 time.sleep(random.randint(2,6))
14 for d in data:
15 article_type = d['articleTypeDisplayName']
16 print('文章类型:',article_type)
17 publication_date = d['publicationDate']
18 print('出版日:',publication_date)
19 journal_name = d['sourceTitle']
20 print('期刊:',journal_name)
21 title = d['title']
22 print('标题:',title.replace("<em>",'').replace("</em>",''))
23 doi = d['doi']
24 print('doi号:',doi)
25 # 获取作者列表
26 authors = d['authors']
27 author_lists = []
28 for au in authors:
29 author_lists.append(au['name'])
30 print('作者:',author_lists)
31 url2 = d['pdf']['downloadLink']
32 print('下载地址:')
33 print('https://www.sciencedirect.com'+str(url2))
34 url3 = d['pdf']['getAccessLink']
35 innerUrl = 'https://www.sciencedirect.com'+str(url3)
36 headers = {
37 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.70'
38 }
39 html = requests.get(innerUrl,headers=headers)
40 soup = BeautifulSoup(html.text,'lxml')
41 data = soup.select('.abstract.author div p')
42 abstract = ''
43 for d in data:
44 abstract += d.text+'\n'
45 print('摘要:')
46 print(abstract)
47 print('----'*10)
48 time.sleep(random.randint(2,6))
最后是输入的结果,当然还可以写一个保存程序,将爬虫到的数据保存下来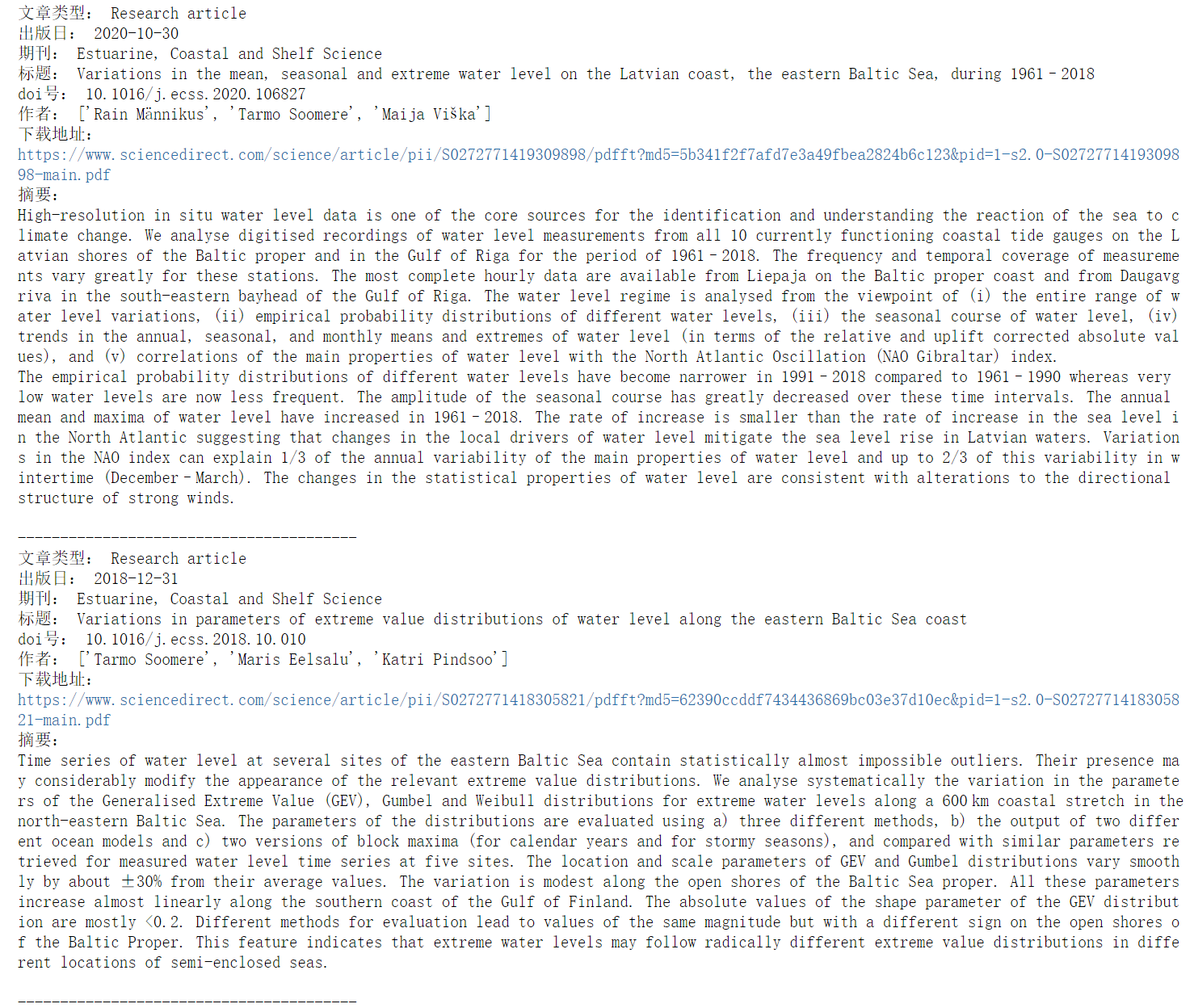
ScienceDirect内容爬虫的更多相关文章
- 【Python爬虫】入门知识
爬虫基本知识 这阵子需要用爬虫做点事情,于是系统的学习了一下python爬虫,觉得还挺有意思的,比我想象中的能干更多的事情,这里记录下学习的经历. 网上有关爬虫的资料特别多,写的都挺复杂的,我这里不打 ...
- python爬虫实例项目大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- 23个Python爬虫开源项目代码,让你一次学个够
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [1]– 微信公众号 ...
- Python爬虫开源项目代码,爬取微信、淘宝、豆瓣、知乎、新浪微博、QQ、去哪网等 代码整理
作者:SFLYQ 今天为大家整理了32个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [ ...
- 洗礼灵魂,修炼python(71)--爬虫篇—【转载】xpath/lxml模块,爬虫精髓讲解
Xpath,lxml模块用法 转载的原因和前面的一样,我写的没别人写的好,所以我也不浪费时间了,直接转载这位崔庆才大佬的 原帖链接:传送门 以下为转载内容: --------------------- ...
- node 简单的爬虫
基于express爬虫, 1,node做爬虫的优势 首先说一下node做爬虫的优势 第一个就是他的驱动语言是JavaScript.JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言, ...
- 23个Python爬虫开源项目代码
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [1]– 微信公众号 ...
- 23个Python爬虫开源项目代码,包含微信、淘宝、豆瓣、知乎、微博等
今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心,所有链接指向GitHub,微信不能直接打开,老规矩,可以用电脑打开. 关注公众号「Pyth ...
- 32个Python爬虫实战项目,满足你的项目慌
爬虫项目名称及简介 一些项目名称涉及企业名词,小编用拼写代替 1.[WechatSogou]- weixin公众号爬虫.基于weixin公众号爬虫接口,可以扩展成其他搜索引擎的爬虫,返回结果是列表,每 ...
随机推荐
- ARM NEON指令集优化理论与实践
ARM NEON指令集优化理论与实践 一.简介 NEON就是一种基于SIMD思想的ARM技术,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bi ...
- CountDownLatch原理详解
介绍 当你看到这篇文章的时候需要先了解AQS的原理,因为本文不涉及到AQS内部原理的讲解. CountDownLatch是一种同步辅助,让我们多个线程执行任务时,需要等待线程执行完成后,才能执行下面的 ...
- 【NX二次开发】Block UI 属性类型
Block UI 属性类型的读写总结: 帮助文件 NXOpen::BlockStyler::UIBlock::GetProperties() String类型 //设置值 this->块ID- ...
- Django(65)jwt认证原理
前言 带着问题学习是最有目的性的,我们先提出以下几个问题,看看通过这篇博客的讲解,能解决问题吗? 什么是JWT? 为什么要用JWT?它有什么优势? JWT的认证流程是怎样的? JWT的工作原理? 我们 ...
- NOIP模拟测试29「爬山·学数数·七十和十七」
爬山题解不想写了 学数数 离散化然后找到以每一个值为最大值的连续子段有多少个,然后开个桶维护 那么怎么找以每一个值为最大值的连续子段个数 方法1(我的极笨的方法) 考试时我的丑陋思路, 定义极左值为左 ...
- 【学习】自定义view
自定义控件其实很简单1/2 Canvas的使用 自定义控件其实很简单1/3 Shader与画布的旋转 自定义控件其实很简单2/3 view的测量 自定义控件其实很简单1/4 FontM ...
- 用VSCode终端实现重定向比较程序输出和正确输出
在刷 OJ 题目或者进行编程考试或比赛时,经常需要对编写好的程序进行测试,即运行编写好的程序,输入样例输入或者自己编写的输入数据,查看程序输出结果和样例输出或者正确输出是否一致.这种方法有很多弊端,当 ...
- JUL 日志框架
1.JUL 简介 JUL 全称 Java Util Logging,位于java.util.logging.Logger 包.它是 java 原生的日志框架,使用时无需另外引用第三方的类库,相对其他的 ...
- 温故知新Docker概念及Docker Desktop For Windows v3.1.0安装
Docker 简介 什么是Docker? Docker是一个开放源代码软件项目,项目主要代码在2013年开源于GitHub.它是云服务技术上的一次创新,让应用程序布署在软件容器下的工作可以自动化进行, ...
- 揭开Docker的面纱
开新坑了,开始挖坑Docker了,兄弟们.为什么需要Docker呢?Docker是什么?这里开始揭开Docker的面纱. 一.为什么需要Docker 可能每个开发人员都有一种困扰,软件开发完之后部署项 ...