使用 PyTorch Lightning 将深度学习管道速度提高 10 倍
前言
本文介绍了如何使用 PyTorch Lightning 构建高效且快速的深度学习管道,主要包括有为什么优化深度学习管道很重要、使用 PyTorch Lightning 加快实验周期的六种方法、以及实验总结。
当 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年设计 AlexNet 时,训练 6000 万参数模型需要五到六天的时间。八年后的 2020 年,微软 DeepSpeed 团队在不到 44 分钟的时间内成功训练了一个 3.5 亿参数的 Large-Bert 模型!
九年后,我们现在看到,AlexNet 只是机器学习革命的冰山一角。今天,我们知道许多尚未开发的潜在训练技术和深度学习模型架构都在我们的掌握之中!
不幸的是,由于数据的规模和新的深度学习模型架构的规模,其中许多进步对于普通研究人员来说就像多汁苹果对于没有梯子的水果采摘者一样难以获得。有这么多卓有成效的模型架构挂在深度学习潜力之树上,我们应该问自己,“我们如何才能达到它们?”


答案很简单:要达到这些富有成效的架构,我们需要梯子!Alex Krizhevsky 构建了他自己的梯子来逐块到达 AlexNet,但是今天,像 PyTorch Lightning 这样的解决方案为您提供了自己的现成梯子——甚至是自动扶梯!
本文介绍了如何使用 PyTorch Lightning 构建高效且快速的深度学习管道,还解释了这些优化如何通过显着加快研发实验周期来快速尝试各种研究想法!
为什么优化深度学习管道很重要
使用 PyTorch Lightning 加快实验周期的六种方法
结果总结
为什么优化深度学习管道很重要
无论是在学术界还是在工业界从事研究,研发探索和尝试新想法的时间和资源总是有限的。随着数据集的规模和深度学习模型的复杂性不断增加,对最新机器学习模型和技术的实验日益复杂和耗时。如何应对这些挑战(并使研发周期更有效率)对项目的整体成功起着至关重要的作用。

如今,存在各种解决方案来克服这些障碍,例如 Grid.ai、WandB 和 PyTorch Lightning。本文将重点介绍 PyTorch Lightning,并解释如何使用它使深度学习管道更快,并在需要最少代码更改的情况下在幕后提高内存效率。使用这些解决方案,可以使实验更具可扩展性和迭代速度更快,同时最大限度地减少潜在的错误。进行这些更改将减少实验所需的时间,节省的时间可以用来尝试更多的想法。
使用 PyTorch Lightning 加快实验周期的六种方法
优化深度学习管道的六种方法:
并行数据加载
多GPU训练
混合精度训练(Mixed precision training)
分片训练(Sharded training)
提前停止(Early stopping)
模型评估和推理期间的优化
对于每一种方法,我们都会简要解释它的工作原理,如何实现它,最后,分享我们是否发现它对我们的项目有帮助!
并行数据加载
数据加载和增强步骤成为训练管道中的瓶颈是很常见的。
典型的数据管道包含以下步骤:
从磁盘加载数据
即时创建随机增强
将每个样本整理成批
数据加载和增强过程非常容易并行,可以通过使用多个 CPU 进程并行加载数据来优化。这样一来,昂贵的 GPU 资源就不会在训练和推理过程中受到 CPU 的阻碍。
为了尽快加载数据以训练深度学习模型,可以执行以下操作:
将 DataLoader 中的 `num_workers` 参数设置为 CPU 的数量。
使用 GPU 时,将 DataLoader 中的 `pin_memory` 参数设置为 True。这会将数据分配到页面锁定内存中,从而加快向 GPU 传输数据的速度。
补充说明:
如果处理流数据(即`IterableDataset`),还需要配置每个worker以独立处理传入的数据。
种子初始化错误困扰着许多开源深度学习项目。为避免该错误,请在 `worker_init_fn` 中定义工作进程的进程种子。从 PyTorch Lightning 1.3 开始,这会使用 `seed_everything(123, workers=True)` 自动处理。
从 PyTorch 1.8 开始,可以使用可选的 `prefetch_factor` 参数更好地控制加载性能行为。将此设置为更高的整数以提前加载更多批次,但会占用更大的内存。
使用分布式数据并行进行多 GPU 训练

GPU 为 CPU 的训练和推理时间提供了巨大的加速。什么比 GPU 更好?多个GPU!
PyTorch 中有一些范例可用于训练具有多个 GPU 的模型。两个更常见的范例是“DataParallel”和“DistributedDataParallel”,其中“DistributedDataParallel”是一种更具可扩展性的方法。
在 PyTorch(和其他平台)中修改训练管道并非易事。人们必须考虑诸如以分布式方式加载数据以及权重、梯度和指标的同步等问题。
使用 PyTorch Lightning,能够非常轻松地在多个 GPU 上训练 PyTorch 模型,几乎无需更改代码!

混合精度
默认情况下,输入张量以及模型权重以单精度 (float32) 定义。但是,某些数学运算可以半精度 (float16) 执行。这会显着提高速度并降低模型内存带宽,而不会牺牲模型性能。
通过在 PyTorch Lightning 中设置混合精度标志,框架会在可能的情况下自动使用半精度,同时在其他地方保留单精度。通过最少的代码修改,能够将模型训练时间提高 1.5 到 2 倍。

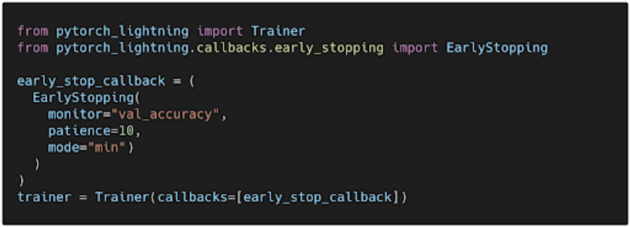
提前停止
模型需要训练大量的 epoch,但实际上模型在训练过程的早期就很可能过度拟合了训练数据。因此,需要在训练管道中实施提前停止。提前停止被配置为在预定义的评估次数后验证损失停止减少时结束训练。通过这样做,不仅可以防止过度拟合,而且还可以节省时间,在数十个而不是数百个 epoch 内找到最佳模型。
分片训练
分片训练基于微软的 ZeRO 研究和 DeepSpeed 库,这使得训练大型模型具有可扩展性和简单性。这是通过使用各种内存和资源间通信优化来实现的。实际上,分片训练可以训练大型模型,否则这些模型将不适合单个 GPU 或在训练和推理期间使用更大的批次大小。
PyTorch Lightning 在其 1.2 版本中引入了对分片训练的支持。在我们的用例中,我们没有观察到训练时间或内存占用的任何显着改进。但是,我们的见解可能无法推广到其他问题和设置,可能值得一试,尤其是当处理不使用单个 GPU 的大型模型时。
模型评估和推理期间的优化
在模型评估和推理期间,模型的前向传递不需要梯度。因此,可以将评估代码包装在一个 `torch.no_grad` 上下文管理器中。这可以防止在前向传递期间存储梯度,从而减少内存占用。因此,可以将更大的批次输入模型中,从而实现更快的评估和推理。
默认情况下,PyTorch Lightning 在幕后管理这些优化。
结果总结
在我们的实验中,我们发现所有优化都独立地减少了训练深度学习模型的时间,除了分片训练,我们没有观察到任何速度或内存改进。
下表是改进深度学习管道所做的每项优化,以及观察到的性能提升。
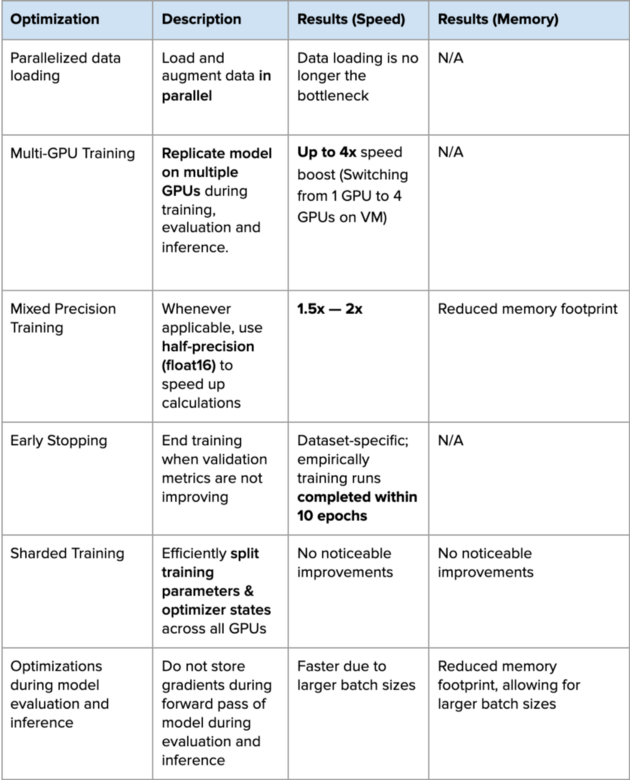
通过这些优化,我们把深度学习管道提高了10倍的速度,从两周节省到只要10小时。
作者:Georgian
编译:CV技术指南
原文链接:https://devblog.pytorchlightning.ai/how-we-used-pytorch-lightning-to-make-our-deep-learning-pipeline-10x-faster-731bd7ad318a
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结”可获取公众号原创技术总结文章的汇总pdf。

其它文章
资源分享 | SAHI:超大图片中对小目标检测的切片辅助超推理库
使用 Ray 将 PyTorch 模型加载速度提高 340 倍
使用 PyTorch Lightning 将深度学习管道速度提高 10 倍的更多相关文章
- PyTorch如何构建深度学习模型?
简介 每过一段时间,就会有一个深度学习库被开发,这些深度学习库往往可以改变深度学习领域的景观.Pytorch就是这样一个库. 在过去的一段时间里,我研究了Pytorch,我惊叹于它的操作简易.Pyto ...
- 深度学习与CV教程(10) | 轻量化CNN架构 (SqueezeNet,ShuffleNet,MobileNet等)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- 多伦多大学&NVIDIA最新成果:图像标注速度提升10倍!
图像标注速度提升10倍! 这是多伦多大学与英伟达联合公布的一项最新研究:Curve-GCN的应用结果. Curve-GCN是一种高效交互式图像标注方法,其性能优于Polygon-RNN++.在自动模式 ...
- 王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上
王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上 http://edu.51cto.com/lesson/id-30815.html Spark实战高手之路 系列书籍 ...
- PyTorch中使用深度学习(CNN和LSTM)的自动图像标题
介绍 深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现.深入了解深度学习的最佳方法是亲自动手.尽可能多地参与项目,并尝试自己完成.这将帮助您更深入地掌握主题,并帮助您成为更好的深 ...
- pytorch入门--土堆深度学习快速入门教程
工具函数 dir函数,让我们直到工具箱,以及工具箱中的分隔区有什么东西 help函数,让我们直到每个工具是如何使用的,工具的使用方法 示例:在pycharm的console环境,输入 import t ...
- 【原】KMeans与深度学习模型结合提高聚类效果
这几天在做用户画像,特征是用户的消费商品的消费金额,原始数据(部分)是这样的: id goods_name goods_amount 男士手袋 1882.0 淑女装 2491.0 女士手袋 345.0 ...
- 吴裕雄 python深度学习与实践(10)
import tensorflow as tf input1 = tf.constant(1) print(input1) input2 = tf.Variable(2,tf.int32) print ...
随机推荐
- vue3.0入门(五):vite构建vue项目
使用vite构建项目步骤 安装node,cmd输入:node -v验证是否安装成功:一般node安装后会自动安装npm,cmd输入:npm -v验证是否安装成功 选择一个文件夹作为项目文件夹,搜索框输 ...
- 在已有Win7/10系统电脑中加装Ubuntu18.04(安装双系统)
准备一台有Win7/10的电脑. 为Ubuntu预留硬盘空间.最好在硬盘最后保留一个空闲分区.(Ubuntu会自动安装到后面的空闲分区) 用Universal USB Installer制作安装盘(U ...
- android kotlin 子线程中调用界面UI组件崩溃
UI 只能在主线程内更新,子线程需要更新UI组件时可以这样: fun fuck(){ Executors.newSingleThreadExecutor().execute{ // url reque ...
- spring boot 系列之七:SpringBoot整合Mybatis
springboot已经很流行,但是它仍需要搭配一款ORM框架来实现数据的CRUD,之前已经分享过JdbcTemplete和JPA的整合,本次分享下Mybatis的整合. 对于mybatis的使用,需 ...
- 前端路由原理之 hash 模式和 history 模式
什么是路由? 个人理解路由就是浏览器 URL 和页面内容的一种映射关系. 比如你看到我这篇博客,博客的链接是一个 URL,而 URL 对应的就是我这篇博客的网页内容,这二者之间的映射关系就是路由. 其 ...
- Gitlab(2)- centos7.x 下安装社区版 Gitlab 以及它的配置管理
前置准备:虚拟机安装以及配置相关 包含安装 centos7.8 虚拟机.设置静态 ip 等 https://www.cnblogs.com/poloyy/category/1703784.html 注 ...
- Go并发编程--正确使用goroutine
目录 1. 对创建的gorouting负载 1.1 不要创建一个你不知道何时退出的 goroutine 1.1.1 不要帮别人做选择 1.1.2 不要作为一个旁观者 1.1.3 不要创建不知道什么时候 ...
- 【第十四篇】- Maven 自动化构建之Spring Cloud直播商城 b2b2c电子商务技术总结
Maven 自动化构建 自动化构建定义了这样一种场景: 在一个项目成功构建完成后,其相关的依赖工程即开始构建,这样可以保证其依赖项目的稳定. 比如一个团队正在开发一个项目 bus-core-api, ...
- 小Z的袜子 & 莫队
莫队学习 & 小Z的袜子 引入 莫队 由莫涛巨佬提出,是一种离线算法 运用广泛 可以解决广大的离线区间询问题 莫队的历史 早在mt巨佬提出莫队之前 类似莫队的算法和莫队的思想已在Codefor ...
- Linux内核中断顶半部和底半部的理解
文章目录 中断上半部.下半部的概念 实现中断下半部的三种方法 软中断 软中断模版 tasklet tasklet函数模版 工作队列 工作队列函数模版 进程上下文和中断上下文 软中断和硬中断的区别 硬中 ...