Hadoop入门 完全分布式运行模式-集群配置
集群配置
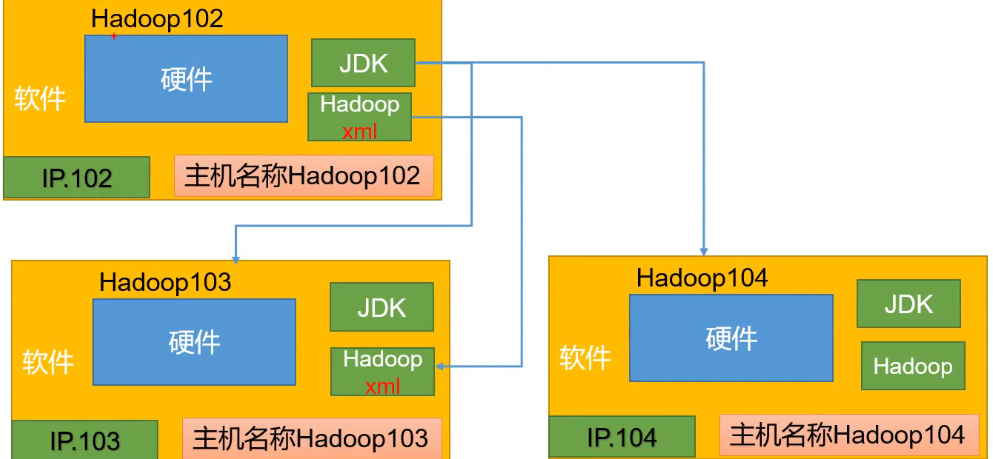
现在各个服务器的准备工作已经做好了,但是Hadoop之间是没有任何关系的
集群部署规划
1.NameNode和SecondaryNameNode不要安装在同一台服务器,因为都耗内存。
2.ResourceManager也很小号内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。

配置文件说明
默认配置文件

自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-size.xml,四个配置文件存放在$HADOOP_HOME(自己安装hadoop的路径)/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
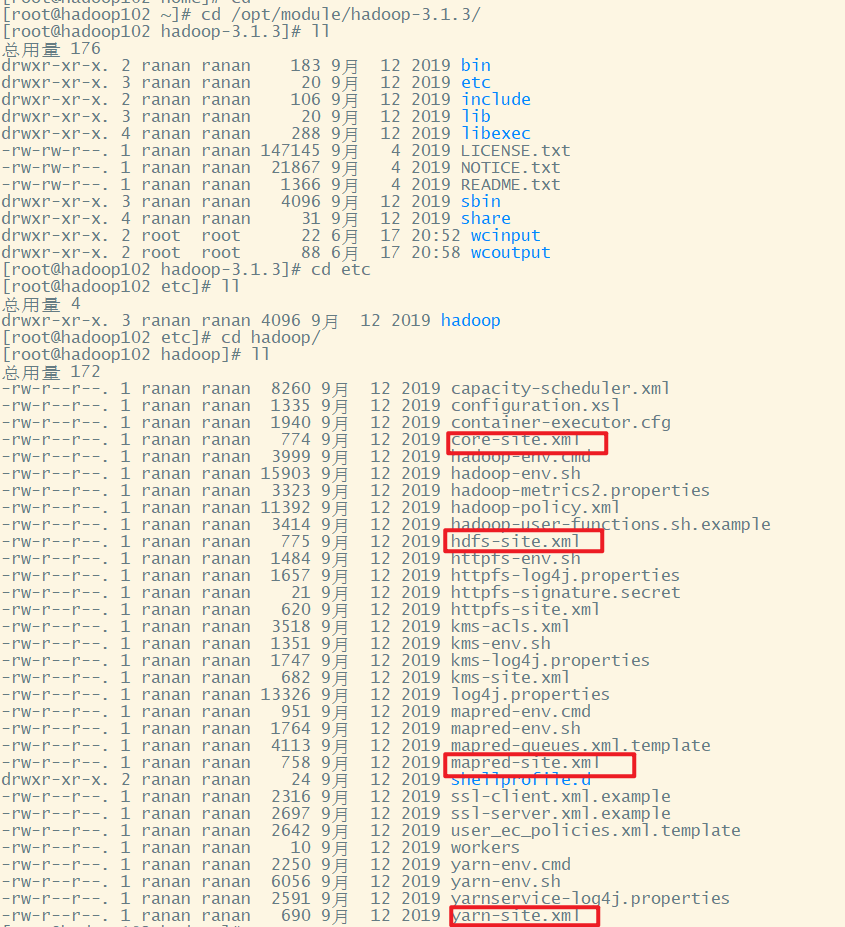
配置集群
1 核心配置文件
配置 core-site.xml
[root@hadoop102 ~]# cd /opt/module/hadoop-3.1.3/etc/hadoop
[root@hadoop102 hadoop]# vim core-size.xml
任务:
1.指定NameNode在哪个服务器上 - hadoop102上
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value> //内部通讯地址
</property>
2.hadoop数据存储在哪个目录下 - /opt/module/hadoop-3.1.3/data
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
3.配置HDFS网页登录使用的静态用户为root(可以先不配)
<!-- 配置 HDFS 网页登录使用的静态用户为 ranan -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>ranan</value>
</property>
2 HDFS配置文件
配置 hdfs-site.xml
[ranan@hadoop102 hadoop]$ vim hdfs-site.xml
任务:
1.NameNode Web端访问地址
之前核心配置文件中NameNode地址hdfs://hadoop102:8020相当于是hadoop内部通讯地址,现在NameNode是HDFS需要用户在web界面上访问,不需要操作命令行,即也需要对外暴露一个接口hadoop102:9870
<!-- NameNode web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
2.SecondaryNameNode web 端访问地址
<!-- SecondaryNameNode web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
3 YARN配置文件
配置yarn-site.xml
[ranan@hadoop102 hadoop]$ vim yarn-site.xml
任务:
1.MR走什么协议,什么方式进行资源调度
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> //shuffle方式进行资源调度
</property>
2.指定ResourceManager服务器 - hadoop103
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
3.环境变量的继承
处理原因:3.1版本的bug?
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
默认配置文件yarn_defaut.xml中是有默认值
//yarn_defaut.xml中的默认值
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ
//yarn-site.xml设置的值
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
4 MapReduce配置文件
配置mapred-site.xml
[ranan@hadoop102 hadoop]$ vim mapred-site.xml
任务:
指定MapReduce程序运行在Yarn上,由yarn负责MapReduce程序的资源调度。
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>//默认是local
</property>
5 分发集群配置
hadoop102的配置文件配置完成了,需要将配置文件分发给hadoop103、hadoop104
(之前是放在/root/bin/xsync 这里拷贝在了/home/ranan/bin下)
//ranan身份使用命令权限不够,加入sudo以root的权限进行分发
[ranan@hadoop102 bin]$ sudo ./xsync /opt/module/hadoop-3.1.3/etc/hadoop/
群起集群
刚才已经把集群都配置完毕了,现在需要启动集群
1 配置workers
集群上有几个节点就配置几个主机名称
[ranan@hadoop102 bin]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers

同步所有节点配置文件
[leokadia@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
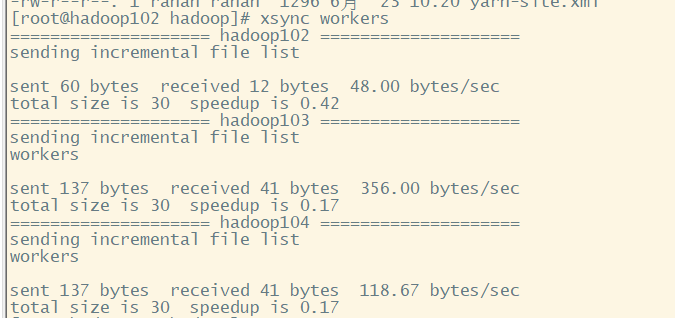
分发配置,将三台节点配置完毕,回到hadoop家目录,准备启动集群
2 启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(相当于新插入的硬盘)
注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
初始化完毕后,源路径多了两个目录data、logs
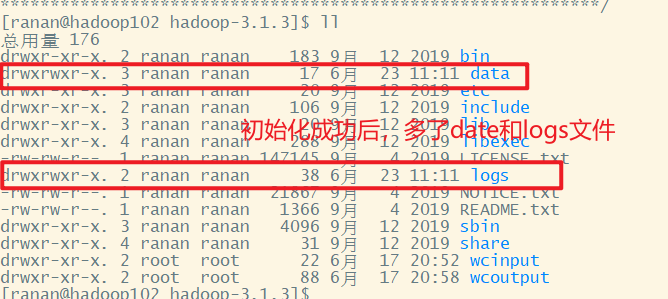
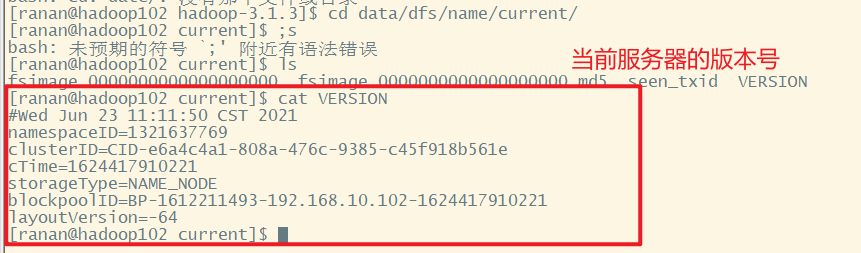
1 启动集群
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
发现hadoop103创建logs的权限不够,是root用户的,那么修改成ranan就行了。修改万完成后重新运行启动集群命令


[ranan@hadoop103 module]$ sudo chown -R ranan:ranan /opt/module/hadoop-3.1.3/

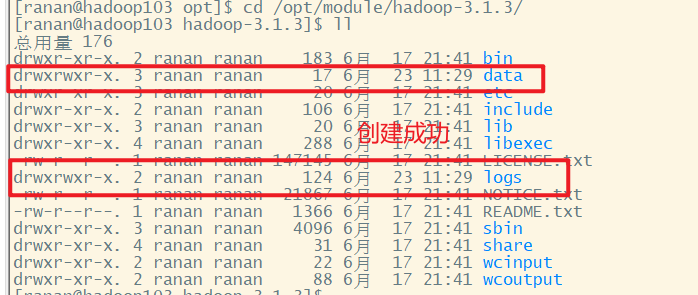
2 检查是否和规划一致
集群部署规划

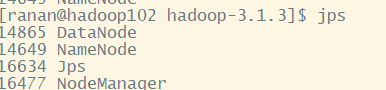
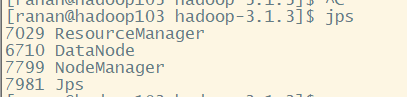
使用jps查看每台虚拟机的真实情况
hadoop102

hadoop103

hadoop104

启动完成后,HDFS还提供了Web页面:http://hadoop102:9870/
3 在配置了 ResourceManager 的节点 (hadoop103 )启动 YARN
上传数据不牵扯yarn,牵扯到MapReduce才会启动YARN
[ranan@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
启动完成后YARN也提供了Web页面,查看任务的运行情况:http://hadoop103:8088
总结
HDFS的启动[ranan@hadoop103 hadoop-3.1.3]$ sbin/start-dfs.sh
在配置了 ResourceManager 的节点 (hadoop103 )启动 YARN[ranan@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
3 集群基本测试
上传文件到集群
上传小文件
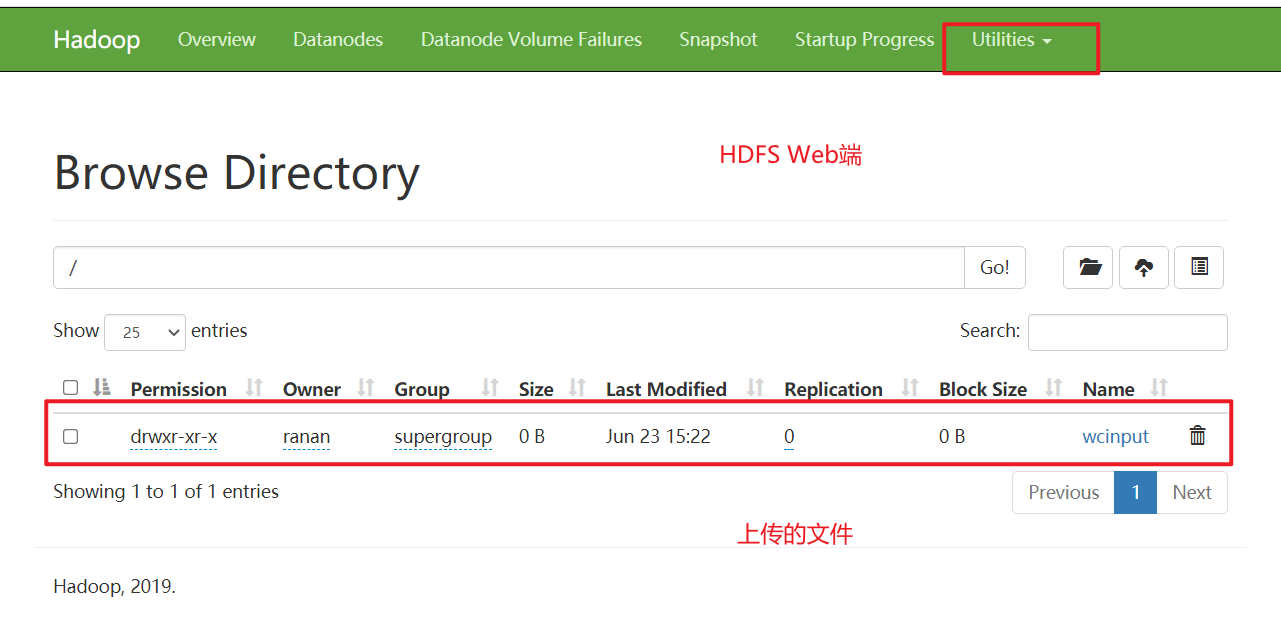
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /wcinput
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /wcinput

上传大文件
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
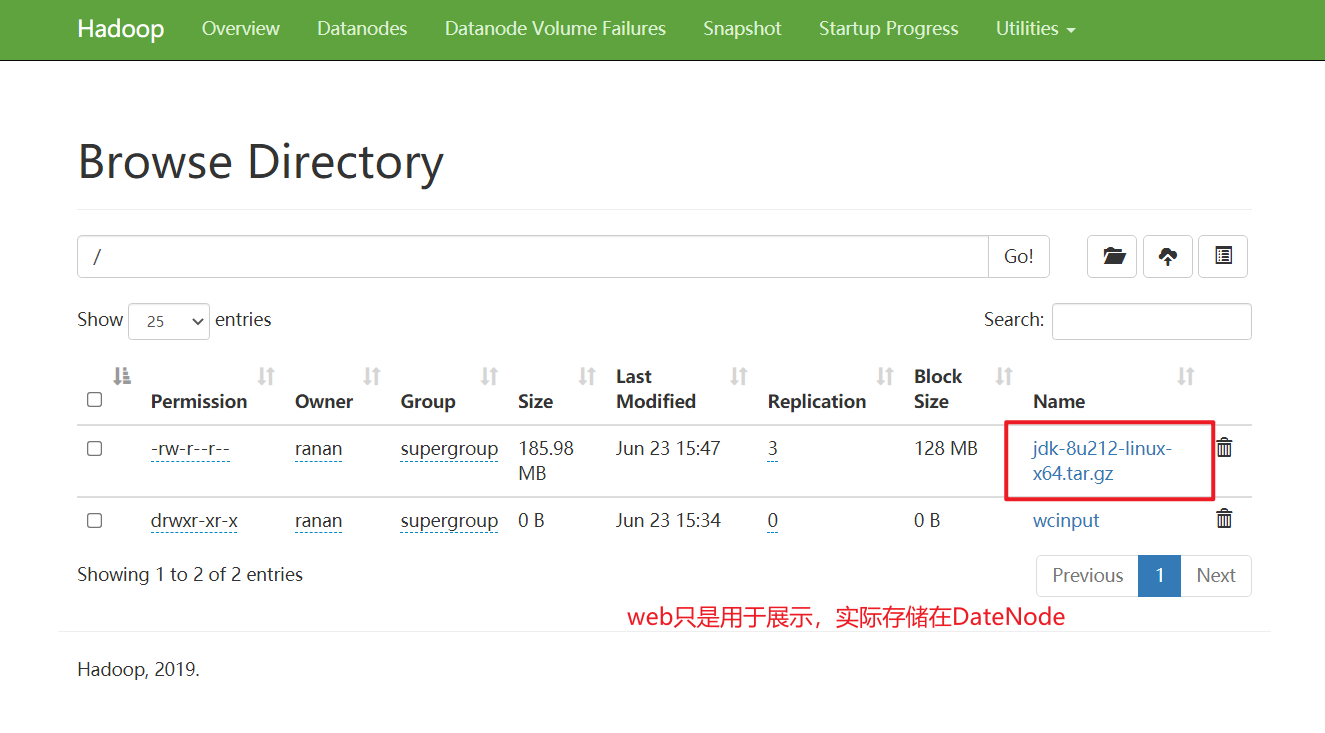
这里面实际只存储了一个链接,实际存储的数据在DataNode
查看数据真实存储路径
真实存储的路径
[ranan@hadoop102 subdir0]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-1612211493-192.168.10.102-1624417910221/current/finalized/subdir0/subdir0
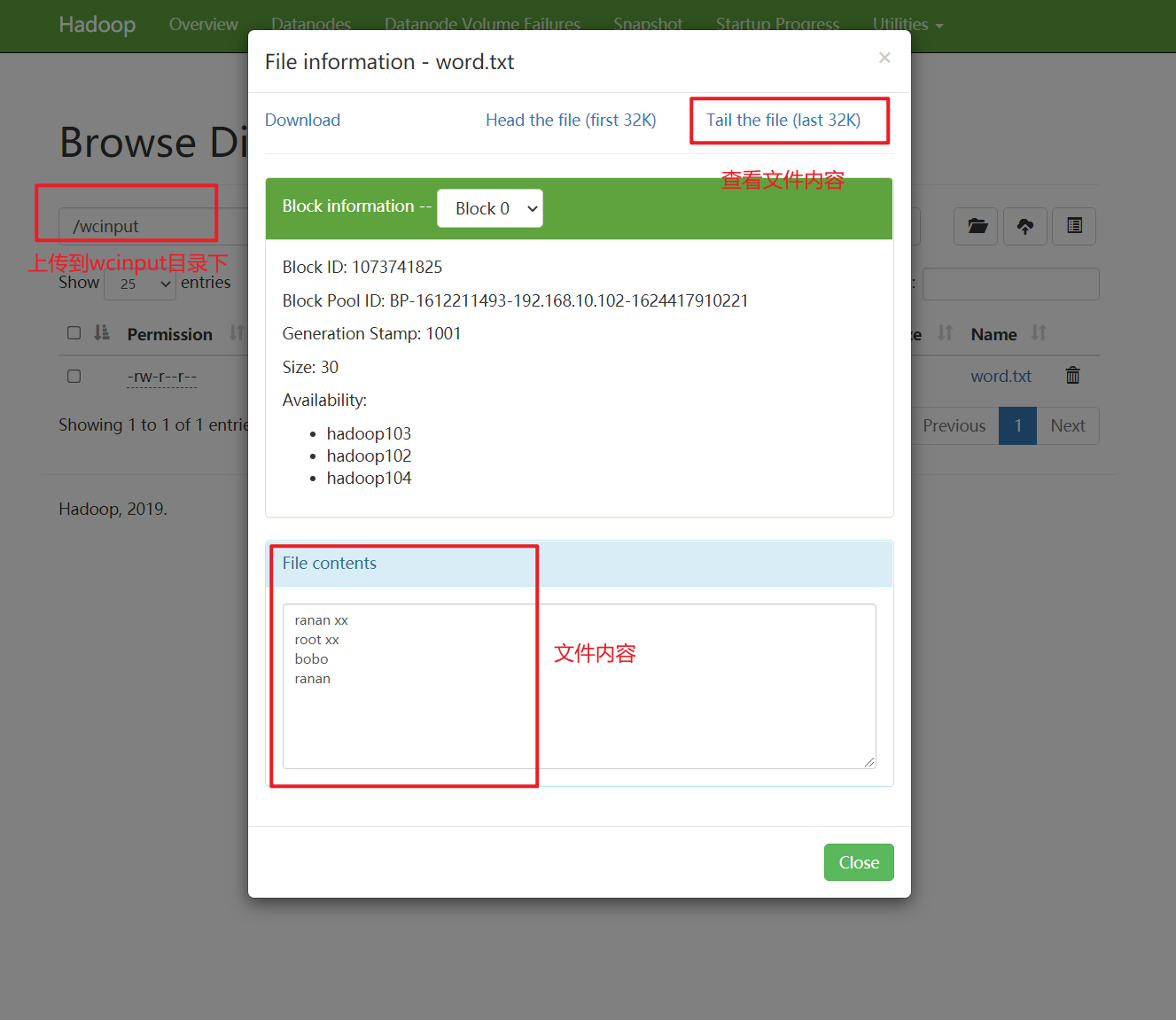
查看word.txt
cat blk_1073741825

查看jdk
把blk_1073741826、blk_1073741827文件输出到tmp.tar.gz。再把压缩包解压到当前路径。
[ranan@hadoop102 subdir0]$ cat blk_1073741826>>tmp.tar.gz
[ranan@hadoop102 subdir0]$ cat blk_1073741827>>tmp.tar.gz
[ranan@hadoop102 subdir0]$ tar -zxvf tmp.tar.gz //解压到当前路径

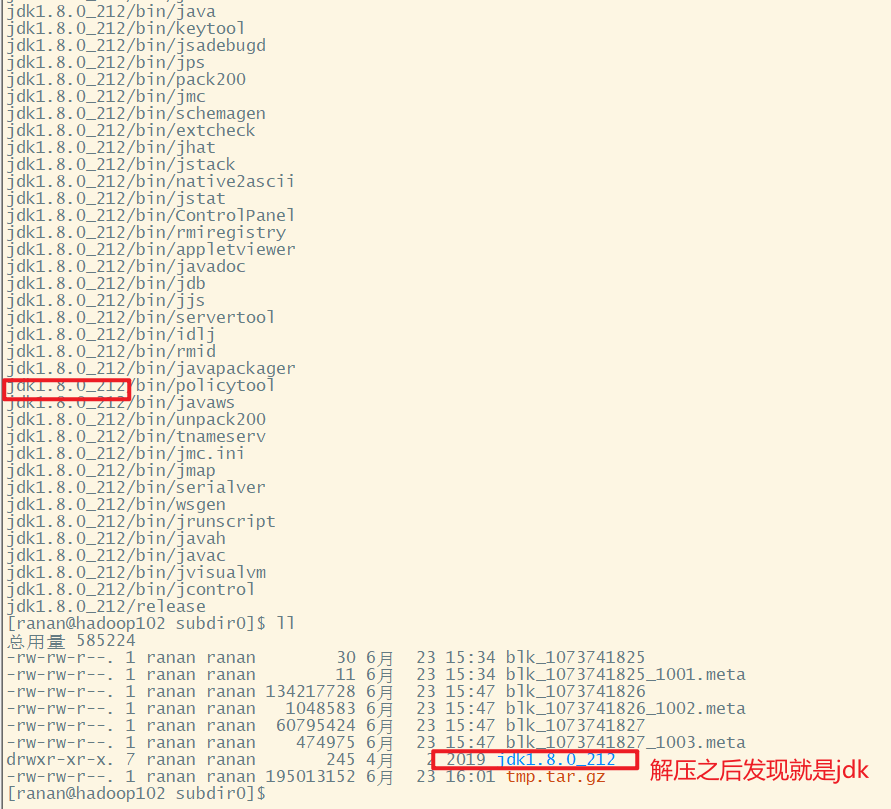
Hadoop高可用,任何一个服务器挂了还有两份副本,每台服务器都是一个NameNode



下载
[ranan@hadoop104 subdir0]# hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
执行wordcount程序
HDFS方式运行,输入输出的路径也需要是集群的路径
[ranan@hadoop102 subdir0]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput

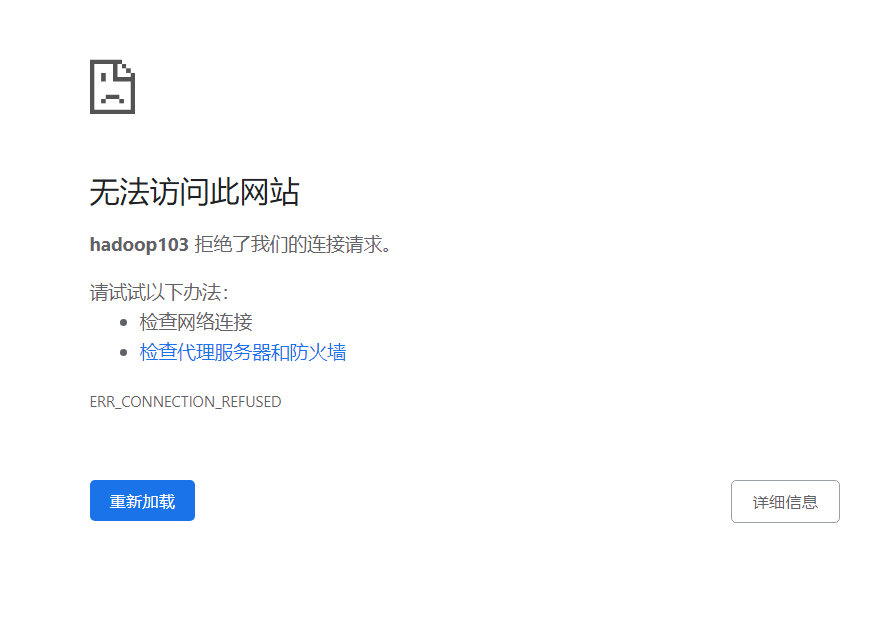
Web端查看YARN的ResourceManager发现了刚刚的任务

点击history报错,因为我们还没有配置history服务器,如果关闭页面,刚刚任务的运行情况就没了。
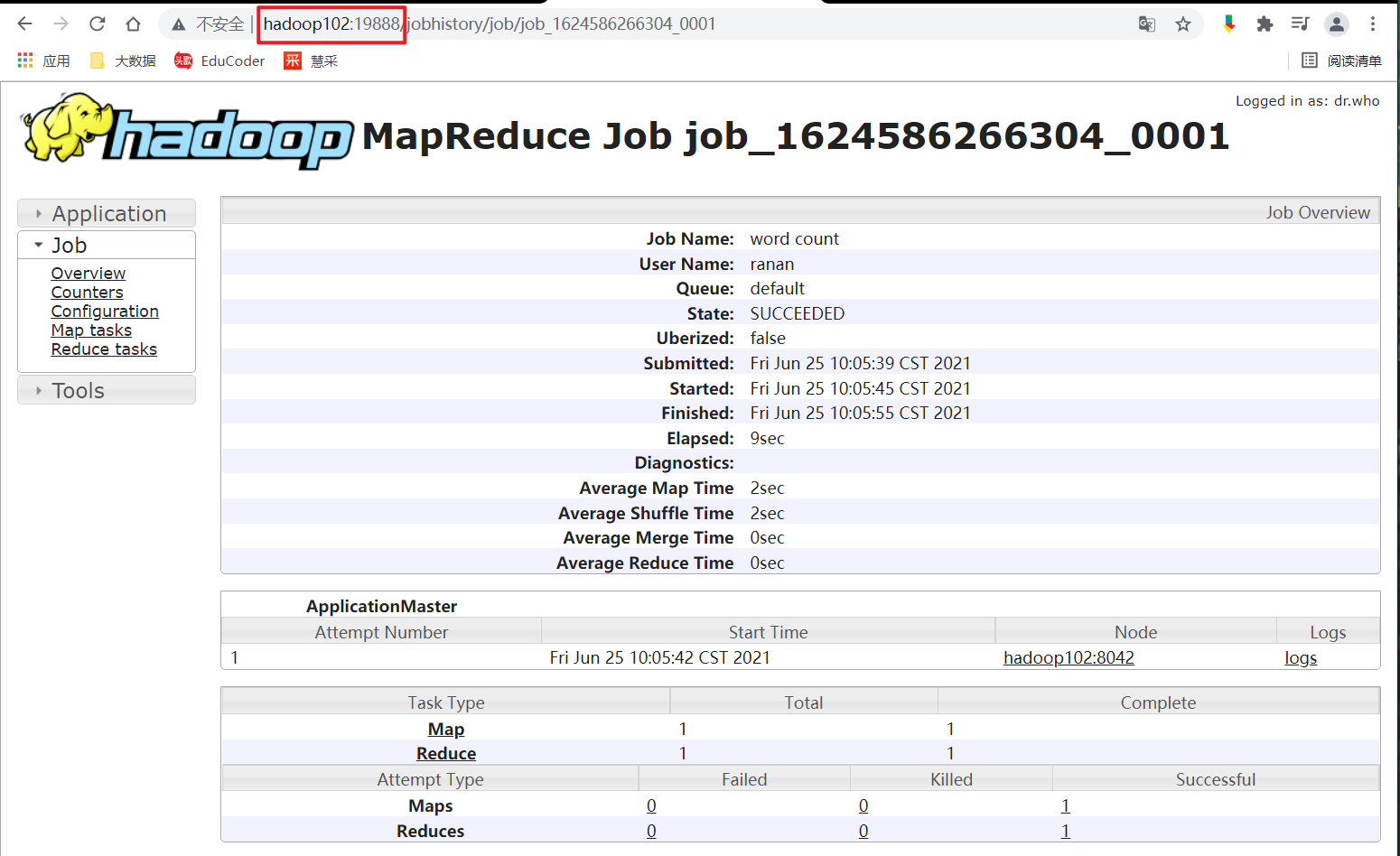
所以是需要配置history服务器的,查看任务的运行情况。
配置历史服务器
1 配置mapred-site.xml
先去配置信息存放的文件/opt/module/hadoop-3.1.3/etc/hadoop
[ranan@hadoop102 hadoop]$ vim mapred-site.xml
1.历史服务器配置在哪台服务器上? - hadoop102:10020
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value> //内部通讯端口
</property>
2.历史服务对外暴露的接口,Web页面。
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
2 分发mapred-site.xml
[ranan@hadoop102 bin]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
3 在hadoop102启动历史服务器
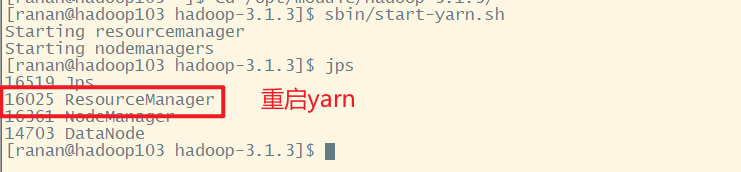
先重启yarn,再启动历史服务器
[ranan@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
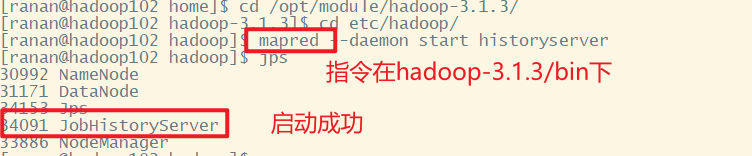
[ranan@hadoop102 hadoop]$ mapred --daemon start historyserver
4 测试
[ranan@hadoop103 hadoop-3.1.3]$ hadoop fs -mkdir /input
[ranan@hadoop103 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /input
[ranan@hadoop103 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input output
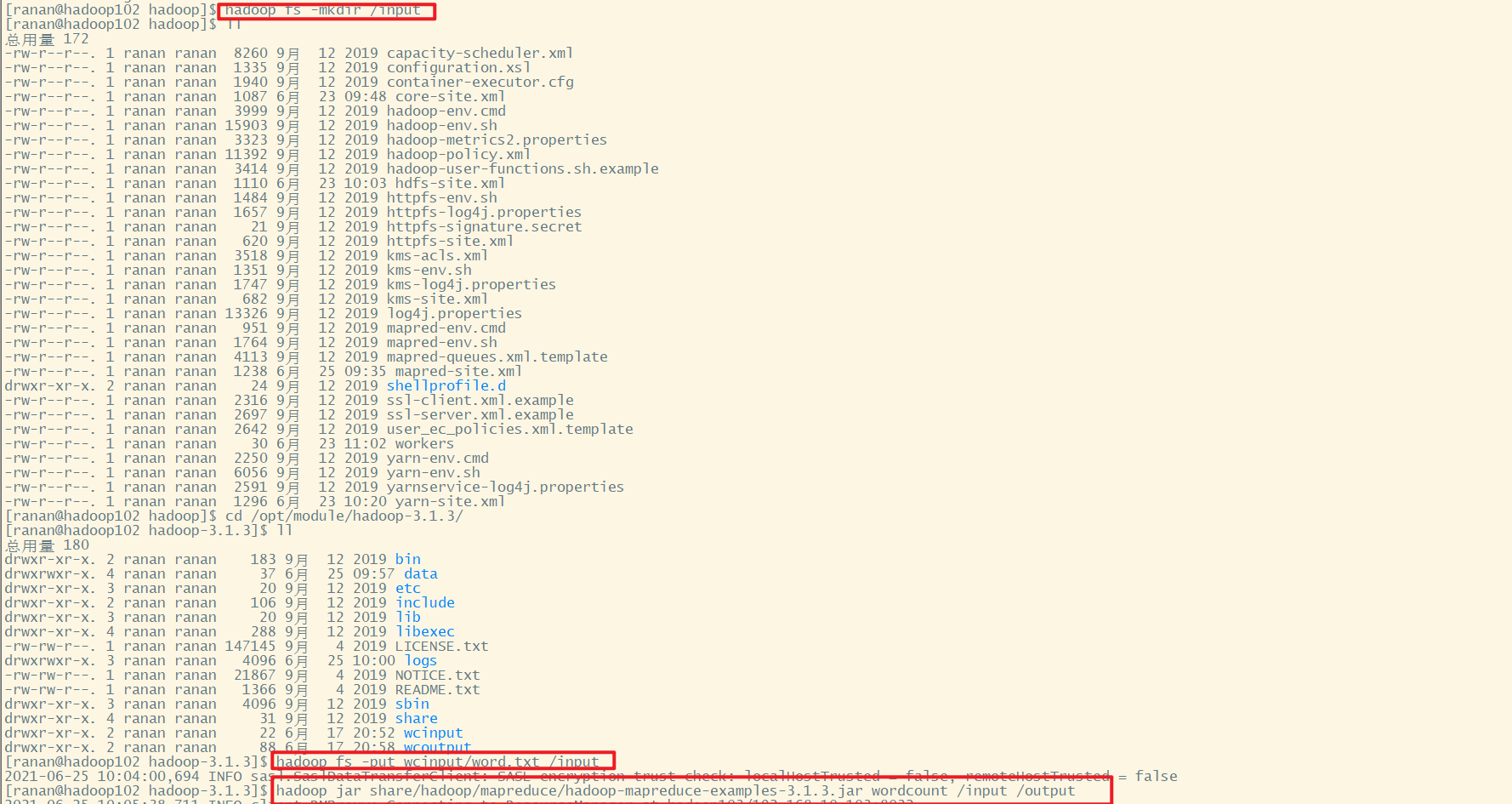
点击History
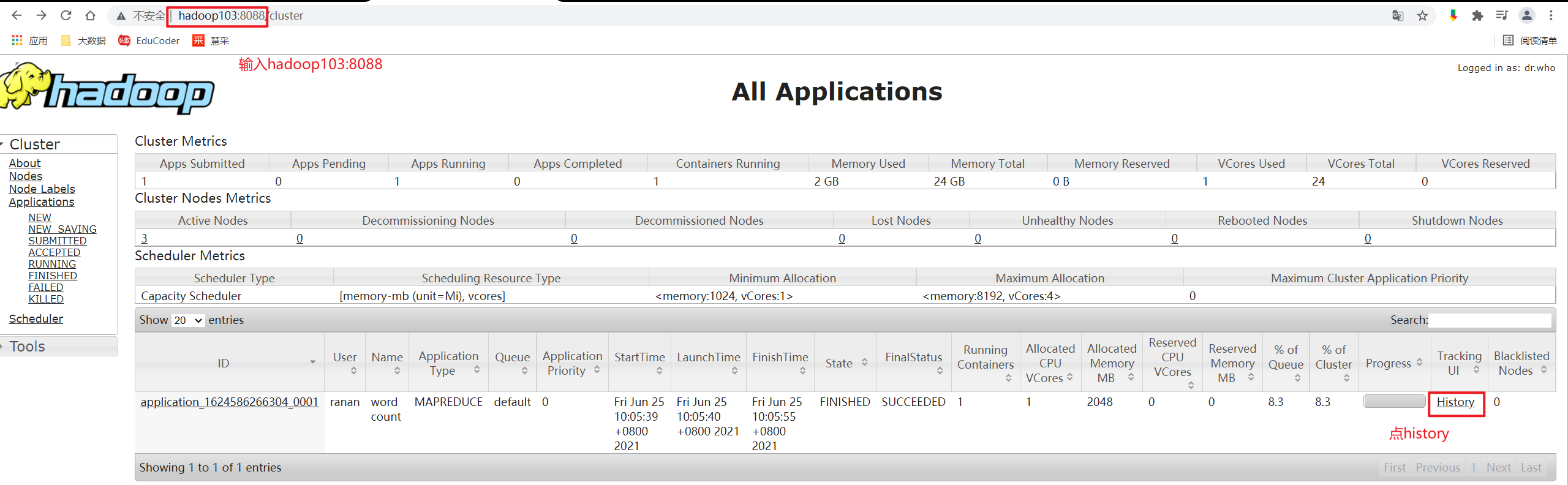
页面跳转到历史服务器暴露的web页面
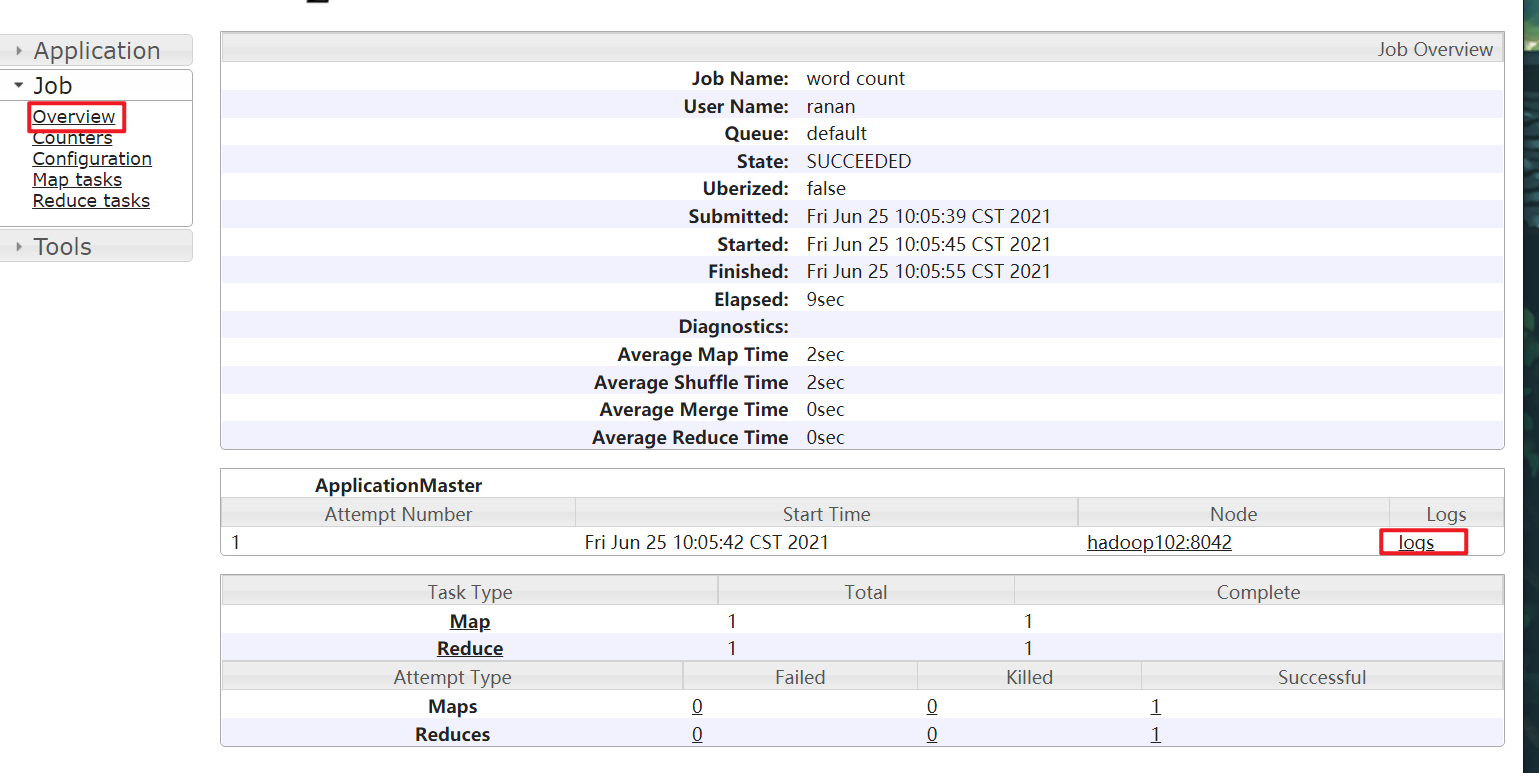
配置日志的聚集
logs点击后无法显示正常功能

日志聚集的概念
应用运行完成以后,将程序运行的日志信息上传到HDFS系统上。可以方便的查看程序运行详情,方便开发调试。
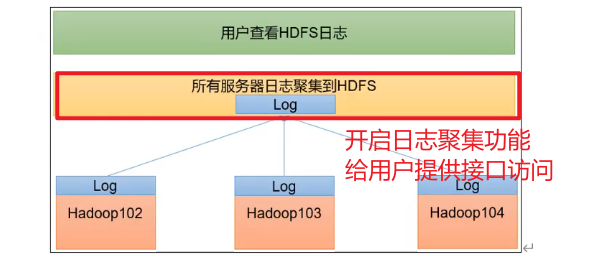
开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和HistoryServer
1 配置yarn-site.xml
[ranan@hadoop102 hadoop]$ vim yarn-site.xml
设置yarn.log开启
历史服务器是hadoop102:19888,为了方便历史服务器查看。logs聚集在hadoop102上http://hadoop102:19888/jobhistory/logs
设置日志保留时间为7天
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value> //默认值是false
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2 分发yarn-site.xml
[ranan@hadoop102 hadoop]$ xsync yarn-site.xml
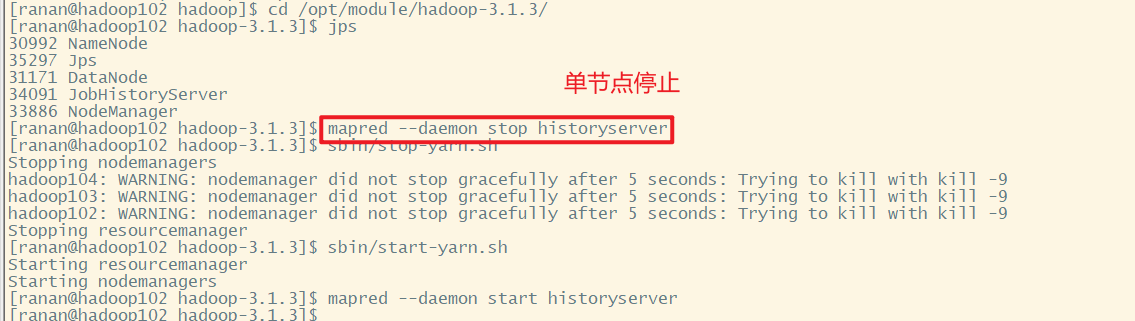
3 重启yarn对应的服务
因为修改了yarn的配置,所以需要重新启动yarn
关闭historyServer
[ranan@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
关闭NodeManager、ResourceManager
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh
重启
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-yarn.sh
[ranan@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
后面执行的任务就可以查看logs了。
4 测试
重新执行命令
[ranan@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /ourput2
Hadoop入门 完全分布式运行模式-集群配置的更多相关文章
- Hadoop入门 完全分布式运行模式-准备
目录 Hadoop运行环境 完全分布式运行模式(重点) scp secure copy 安全拷贝 1 hadoop102上的JDK文件推给103 2 hadoop103从102上拉取Hadoop文件 ...
- Hadoop 2.6.4单节点集群配置
1.安装配置步骤 # wget http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-linux-x64.rpm # rpm -i ...
- Redis 哨兵(sentinel)模式集群配置(5.0.3版本)
一.准备工作 1.系统环境:centos6.4 2.服务器六台(1主5从): 192.168.1.161(master) 192.168.1.162(slave) 192.168.1.163(slav ...
- Hadoop入门(五) Hadoop2.7.5集群分布式环境搭建
本文接上文内容继续: server01 192.168.8.118 jdk.www.fengshen157.com/ hadoop NameNode.DFSZKFailoverController(z ...
- hadoop分布式安装及其集群配置笔记
各机器及角色信息: 共10台机器,hostname与ip地址映射在此不做赘述.此为模拟开发环境安装,所以不考虑将NameNode和SecondaryNameNode安装在同一台机器. 节点 角色 na ...
- 分布式缓存Redis集群配置使用
Redis 简介 redis是一种开源的.基于内存的.可持久化的.高性能的Key-Value数据存储系统. redis能做什么? 持久化存储 高速缓存 消息中间件 ...
- hadoop入门手册2:hadoop【2.7.1】【多节点】集群配置【必知配置知识2】
问题导读 1.如何实现检测NodeManagers健康?2.配置ssh互信的作用是什么?3.启动.停止hdfs有哪些方式? 上篇: hadoop[2.7.1][多节点]集群配置[必知配置知识1]htt ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
随机推荐
- P2598 [ZJOI2009]狼和羊的故事(最小割)
P2598 [ZJOI2009]狼和羊的故事 说真的,要多练练网络流的题了,这么简单的网络流就看不出来... 题目要求我们要求将狼和羊分开,也就是最小割,(等等什么逻辑...头大....) 我们这样想 ...
- HTML基础-3
图像标签(<img>)和源属性(Src) 在 HTML 中,图像由 <img> 标签定义. <img> 是空标签,意思是说,它只包含属性,并且没有闭合标签. 要在页 ...
- ELK 脚本自动化删除索引
kibana有自带接口,可通过自带的API接口 通过传参来达到删除索引的目的. # 删除15天前的索引 curl -XDELETE "http://10.228.81.161:9201/pa ...
- DeWeb : 制作图片轮换效果
演示:http://www.web0000.com/slide.dw源代码:http://www.web0000.com/media/source/slide.zip一.新建一个DLL二.除第一行外, ...
- aardio 开发桌面应用,这几点必须要掌握!
1. 前言 大家好,我是安果! 上一篇文章写到可以通过 aardio 结合 Python 开发桌面应用,有些小伙伴后台给我留言,说 Aardio 资料太少,希望我能补充一些实用的功能 实用 | 利用 ...
- 目录扫描工具 dirsearch 使用详解
介绍 dirsearch 是一个python开发的目录扫描工具.和我们平时使用的dirb.御剑之类的工具一样,就是为了扫描网站的敏感文件和目录从而找到突破口. 特点 多线程 可保持连接 支持多种后缀( ...
- this.$set用法
this.$set()的主要功能是解决改变数据时未驱动视图的改变的问题,也就是实际数据被改变了,但我们看到的页面并没有变化,这里主要讲this.$set()的用法,如果你遇到类似问题可以尝试下,vue ...
- url的hash和HTML5的history
url的hash和HTML5的history 第一种方法是改变url的hash值. **显示当前路径 : **location.href http://localhost:8080/# 切换路径: l ...
- spring security 之自定义表单登录源码跟踪
上一节我们跟踪了security的默认登录页的源码,可以参考这里:https://www.cnblogs.com/process-h/p/15522267.html 这节我们来看看如何自定义单表认 ...
- The 'stream().forEach()' chain can be replaced with 'forEach()' (may change semantics)
对集合操作时,因不同的写法Idea经常会提示:The 'stream().forEach()' chain can be replaced with 'forEach()' (may change s ...