python爬虫采集
python爬虫采集
最近有个项目需要采集一些网站网页,以前都是用php来做,但现在十分流行用python做采集,研究了一些做一下记录。
采集数据的根本是要获取一个网页的内容,再根据内容筛选出需要的数据,
python的好处是速度快,支持多线程,高并发,可以用来大量采集数据,缺点就是和php相比,python的轮子和代码库貌似没有php全,而且python的安装稍微麻烦了点,折腾了好久。
python3的安装见连接:
https://www.cnblogs.com/mengzhilva/p/11059329.html
工具编辑器:
PyCharm :一款很好用的python专用编辑器,可以编译和运行,支持windows
python采集用到的库:
requests:用来获取网页的内容,支持https,用户登录信息等,很强大
lxml:用来解析采集的html内容,十分好用,比较灵活,但很多用法不好找,api文档不好找。
pymysql:连接操作mysql,这个就不用说了,将采集到的信息存到数据库。
基本上这三个就可以支持采集网页
安装代码:
用pip安装调用代码:
pip install pymysql
pip install requests
pip install lxml
采集数据:
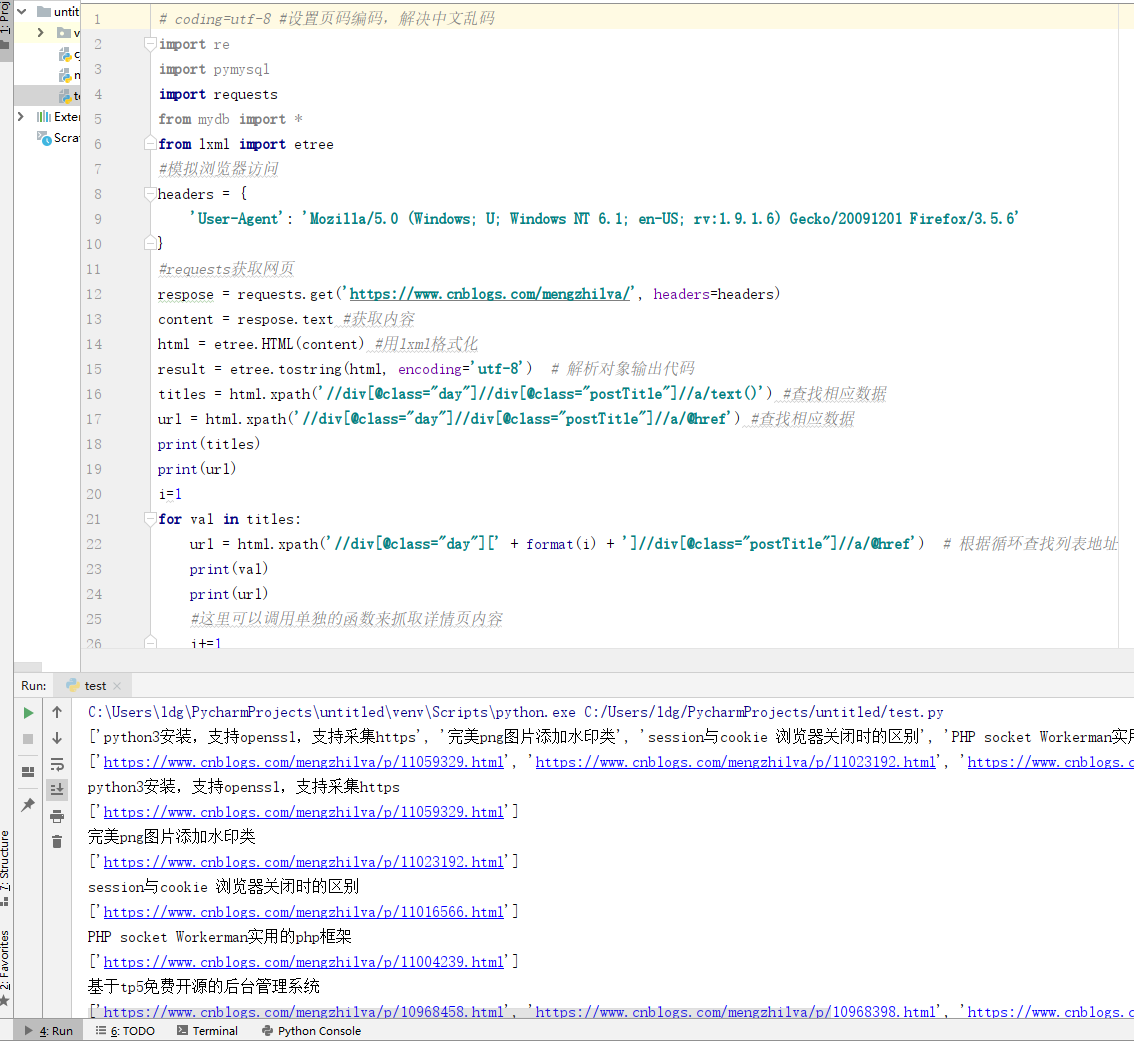
采集的代码和打印的结果:
# coding=utf-8 #设置页码编码,解决中文乱码
import re
import pymysql
import requests
from mydb import *
from lxml import etree
#模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
#requests获取网页
respose = requests.get('https://www.cnblogs.com/mengzhilva/', headers=headers)
content = respose.text #获取内容
html = etree.HTML(content) #用lxml格式化
result = etree.tostring(html, encoding='utf-8') # 解析对象输出代码
titles = html.xpath('//div[@class="day"]//div[@class="postTitle"]//a/text()') #查找相应数据
url = html.xpath('//div[@class="day"]//div[@class="postTitle"]//a/@href') #查找相应数据
print(titles)
print(url)
i=1
for val in titles:
url = html.xpath('//div[@class="day"][' + format(i) + ']//div[@class="postTitle"]//a/@href') # 根据循环查找列表地址
print(val)
print(url)
#这里可以调用单独的函数来抓取详情页内容
i+=1
python爬虫采集的更多相关文章
- 基于Python爬虫采集天气网实时信息
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10- ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- python爬虫采集网站数据
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- python爬虫-采集英语翻译
http://fanyi.baidu.com/?aldtype=85#en/zh/drughttp://fanyi.baidu.com/?aldtype=85#en/zh/cathttp://fa ...
- 编写python爬虫采集彩票网站数据,将数据写入mongodb数据库
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- Python爬虫——城市公交、地铁站点和线路数据采集
本篇博文为博主原创,转载请注明. 城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
随机推荐
- 该如何有效的提高C/C++语言编程能力
很多答案都谈到算法的重要性,我的答案主要集中在C++上,只是一些个人经验. 其实我以前也有这样的困惑,感觉完了不知道怎么用.而且我也不是学计算机的,也没有从事相关工作,所以大概有十年的时间都没写什么程 ...
- Go语言核心36讲(Go语言进阶技术十)--学习笔记
16 | go语句及其执行规则(上) 我们已经知道,通道(也就是 channel)类型的值,可以被用来以通讯的方式共享数据.更具体地说,它一般被用来在不同的 goroutine 之间传递数据.那么 g ...
- Codeforces Round #735 (Div. 2)
这次的cf依旧掉分..... A题和B题在不懈死磕下瞎搞出来了,不过还是被C题卡住了... C. Mikasa 简述题意就是给定n和m,让n^0,n^1,n^2...,n^m,求着m+1个数中没有出现 ...
- 使用jax加速Hamming Distance的计算
技术背景 一般认为Jax是谷歌为了取代TensorFlow而推出的一款全新的端到端可微的框架,但是Jax同时也集成了绝大部分的numpy函数,这就使得我们可以更加简便的从numpy的计算习惯中切换到G ...
- Spring Ioc 容器初始化过程
IOC 是如何工作的? 通过 ApplicationContext 创建 Spring 容器,容器读取配置文件 "/beans.xml" 并管理定义的 Bean 实例对象. 通 ...
- Part 15 AngularJS ng init directive
The ng-init directive allows you to evaluate an expression in the current scope. In the following e ...
- Java学习(十四)
玩云顶连跪一晚上,搞得心态有点崩了... 源计划5-4还是一星vn,吐了. 今天学习了伪元素: 语法是 :first-letter//元素的第一个字母的位置,如果:前不加元素,默认是#(即所有元素) ...
- 大爽Python入门教程 1-1 简单的数学运算
大爽Python入门公开课教案 点击查看教程总目录 1 使用pycharm建立我们的第一个项目 打开pycharm,点击菜单栏,File->New Project 在Location(项目地址) ...
- 「期末」一文带你系统回顾C 语言
超详细 c 语言回顾 前言 c 语言是一种底层语言,是一种系统底层级的语言,例如Windows.Linux.Unix等操作系统就是使用c语言编写的.所以由此看来,不论是火爆了25年的Java,还是近年 ...
- Sentry 官方 JavaScript SDK 简介与调试指南
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...