python爬虫采集
python爬虫采集
最近有个项目需要采集一些网站网页,以前都是用php来做,但现在十分流行用python做采集,研究了一些做一下记录。
采集数据的根本是要获取一个网页的内容,再根据内容筛选出需要的数据,
python的好处是速度快,支持多线程,高并发,可以用来大量采集数据,缺点就是和php相比,python的轮子和代码库貌似没有php全,而且python的安装稍微麻烦了点,折腾了好久。
python3的安装见连接:
https://www.cnblogs.com/mengzhilva/p/11059329.html
工具编辑器:
PyCharm :一款很好用的python专用编辑器,可以编译和运行,支持windows
python采集用到的库:
requests:用来获取网页的内容,支持https,用户登录信息等,很强大
lxml:用来解析采集的html内容,十分好用,比较灵活,但很多用法不好找,api文档不好找。
pymysql:连接操作mysql,这个就不用说了,将采集到的信息存到数据库。
基本上这三个就可以支持采集网页
安装代码:
用pip安装调用代码:
pip install pymysql
pip install requests
pip install lxml
采集数据:
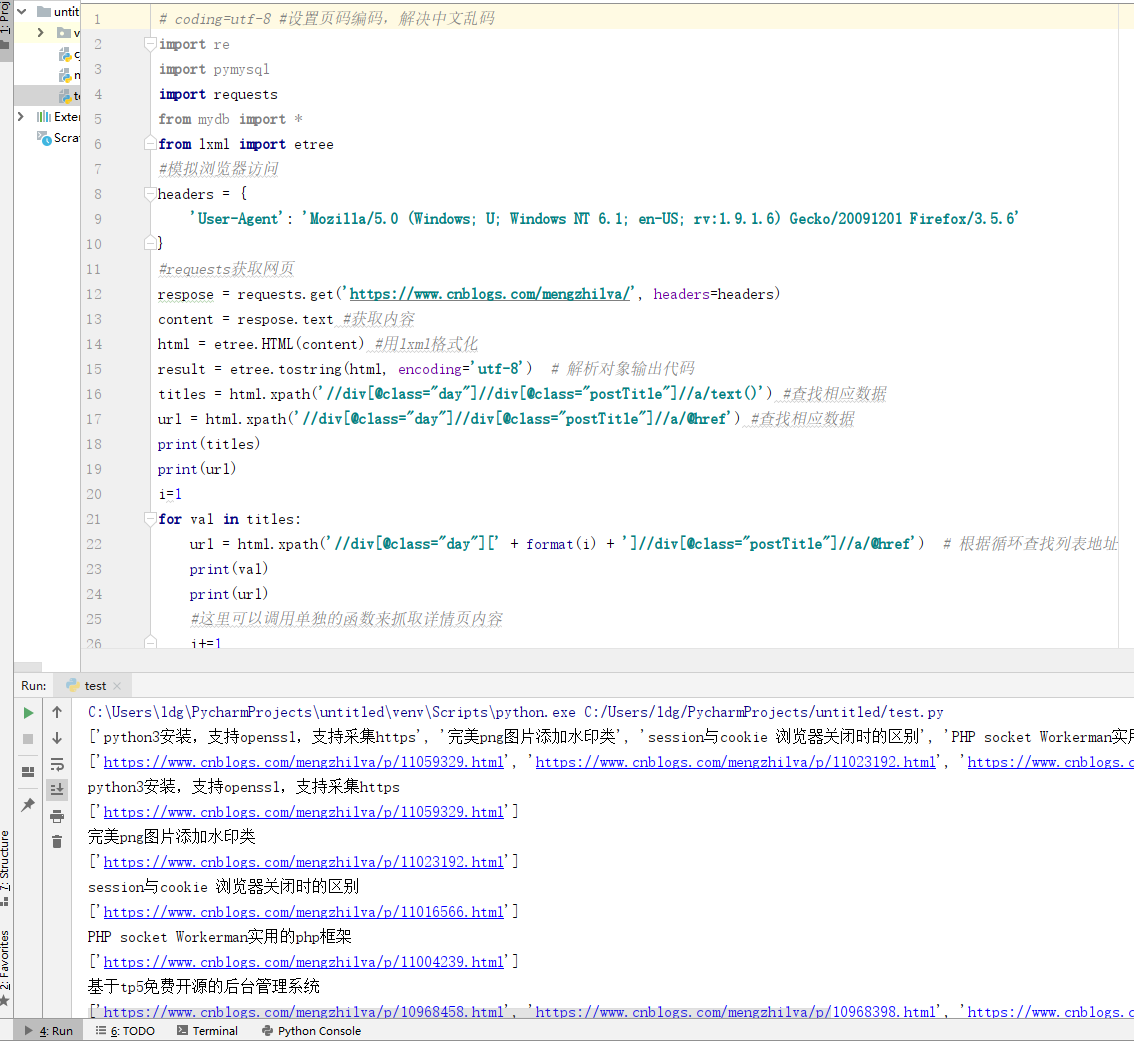
采集的代码和打印的结果:
# coding=utf-8 #设置页码编码,解决中文乱码
import re
import pymysql
import requests
from mydb import *
from lxml import etree
#模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
#requests获取网页
respose = requests.get('https://www.cnblogs.com/mengzhilva/', headers=headers)
content = respose.text #获取内容
html = etree.HTML(content) #用lxml格式化
result = etree.tostring(html, encoding='utf-8') # 解析对象输出代码
titles = html.xpath('//div[@class="day"]//div[@class="postTitle"]//a/text()') #查找相应数据
url = html.xpath('//div[@class="day"]//div[@class="postTitle"]//a/@href') #查找相应数据
print(titles)
print(url)
i=1
for val in titles:
url = html.xpath('//div[@class="day"][' + format(i) + ']//div[@class="postTitle"]//a/@href') # 根据循环查找列表地址
print(val)
print(url)
#这里可以调用单独的函数来抓取详情页内容
i+=1
python爬虫采集的更多相关文章
- 基于Python爬虫采集天气网实时信息
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10- ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- python爬虫采集网站数据
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- python爬虫-采集英语翻译
http://fanyi.baidu.com/?aldtype=85#en/zh/drughttp://fanyi.baidu.com/?aldtype=85#en/zh/cathttp://fa ...
- 编写python爬虫采集彩票网站数据,将数据写入mongodb数据库
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- Python爬虫——城市公交、地铁站点和线路数据采集
本篇博文为博主原创,转载请注明. 城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
随机推荐
- OO第四次博客作业--第四单元总结及课程总结
一.总结第四单元两次作业的架构设计 1.1 第一次作业 类图如下: 为了突出类.接口.方法.属性.和参数之间的层次结构关系,我为 Class 和 Interface 和 Operation 分别建立了 ...
- elasticsearch的索引重建
我们知道es在字段的mapping建立后就不可再次修改mapping的值.在我们实际的情况下有些时候就是需要修改mapping的值,解决方案就是重新构建索引数据. 方式一 : 使用索引别名,创建另外一 ...
- 热身训练2 GCD
题目描述 简要题意: n个数字,a1,a2,...,an m次询问(l,r),每次询问需回答 1.gcd(al,al+1,al+2,...,ar);2.gcd(ax,ax+1,ax+2,...,ay ...
- BZOJ4919[Lydsy1706月赛]大根堆-------------线段树进阶
是不是每做道线段树进阶都要写个题解..根本不会写 Description 给定一棵n个节点的有根树,编号依次为1到n,其中1号点为根节点.每个点有一个权值v_i. 你需要将这棵树转化成一个大根堆.确切 ...
- 【完美解决】IDEA 中 Maven 报错 Cannot resolve xxx 和 Maven 中 Dependencies 报红/报错。
目录 前提 场景 解决办法 1.首先,清除缓存,点击之后重启IDEA. 2.关闭IDEA,打开项目文件夹 3.重新打开 IDEA,找到右边的 Maven 4.解决 Maven 中 Dependenci ...
- .NET Core资料精选:架构篇
.NET 6.0 马上就要发布,高性能云原生开发框架.希望有更多的小伙伴加入大.NET阵营.这是本系列的第三篇文章:架构篇,喜欢的园友速度学起来啊. 本系列文章,主要分享一些.NET Core比较优秀 ...
- 【Java】 List和Array转换
List转Array toArray 首先展示初学者容易犯的错误示例 List<String> strList = new ArrayList<>(); strList.add ...
- 2021 羊城杯WriteUP
比赛感受 题目质量挺不错的,不知道题目会不会上buu有机会复现一下,躺了个三等奖,发下队伍的wp Team BinX from GZHU web Checkin_Go 源码下载下来发现是go语言写的 ...
- 津门杯WriteUP
最近很浮躁,好好学习 WEB power_cut 扫目录 index.php <?php class logger{ public $logFile; public $initMsg; publ ...
- VUE的MVVM框架解析
这篇文章主要介绍了MVVM模式中ViewModel和View.Model有什么区别?本文分别解释了它们的功能和作用,然后总结了它之间的区别,需要的朋友可以参考下 Model:很简单,就是业务逻辑相关的 ...