分布式消息流平台:不要只想着Kafka,还有Pulsar
摘要:Pulsar作为一个云原生的分布式消息流平台,越来越频繁地出现在人们的视野中,大有替代Kafka江湖地位的趋势。
本文分享自华为云社区《MRS Pulsar:下一代分布式消息流平台全新发布!》,作者: Lothar。
Pulsar的前世今生
Apache Pulsar是一个发布-订阅消息系统,使用计算与存储分离的云原生架构。Pulsar 2018年9月成为ASF顶级项目,近两年,随着社区不断发展和诸多企业的应用和贡献,Pulsar作为一个云原生的分布式消息流平台,越来越频繁地出现在人们的视野中,大有替代Kafka江湖地位的趋势。
Pulsar和Kafka的对比
Pulsar和Kafka架构上最大的不同是,Kafka由Broker进行消息的收发和持久化,数据存储在本地文件系统,由Broker统一管理。这也意味着数据和消息处理是耦合的。
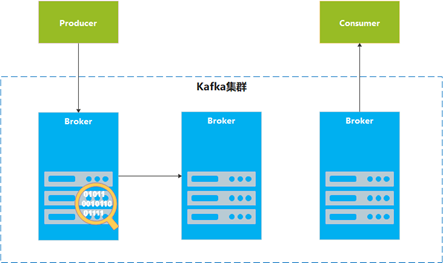
Kafka官网描述道:Kafka重度依赖文件系统,用于存储或缓存消息。当Broker接收到消息时,会将消息追加写到本地磁盘上。这一架构决定了Partition和Broker的对应关系是相对固定的,只有在partition reassign时才会发生数据迁移。Partition的Leader在数据副本分布节点上产生,用于处理生产消费请求。
而Pulsar采用了计算存储分离架构,这也是Pulsar被称作云原生平台的主要原因。Pulsar依赖Apache BookKeeper管理持久化数据,Apache BookKeeper是可扩展、可容错、低延迟的日志存储服务,能够保证在强持久性下的低延迟读写。
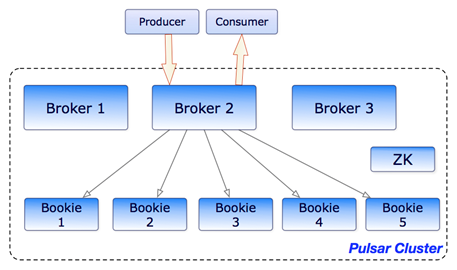
*引自Pulsar官网介绍:https://pulsar.apache.org/docs/en/concepts-architecture-overview/
Broker接收请求后,数据实际分布式存储在BookKeeper服务中。在数据的物理存储模型中某个Topic或Partition的数据并不固定存储在某个Bookie实例上。
Pulsar将分布式日志划分为多个Segment,每个Segment对应BookKeeper中的一个Ledger。与Kafka将某一Partition的数据日志保存在某一固定目录下不同,Pulsar通过划分Segment的方式,可以将同一topic或partition分布到不同的Bookie上。
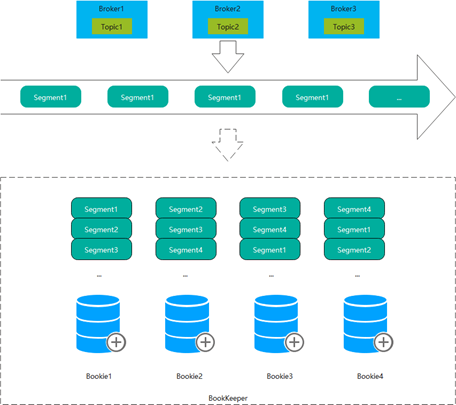
Pulsar的优势特性
灵活扩展
相信很多使用Kafka的客户都有类似的经历:
- 磁盘空间不足,只能调整数据TTL,或扩容机器后向新的Broker中迁移Partition
- Topic或Partition间数据分配不均匀,节点之间或磁盘之间使用不均衡,有的磁盘已经满了,而有的磁盘还有很多空间
- Broker机器故障,需要将数据迁移到其他节点后下电维修
Pulsar的存算分离架构天然地避免了这些问题。Pulsar Broker本身是无状态的,当某个Broker故障时,另一个Broker可以立即接管对应的Topic而不需要迁移数据。BookKeeper分布式日志保证了存储节点间的数据均衡,不会因某一个Partitoin或Topic数据过多而导致IO集中在某一节点上。
当集群需要扩容时,Broker可以立即感知到新加入集群的Bookie,并将新写入的数据存储到新添加的Bookie中。
多租户
Kafka社区在KIP-37正在讨论加入NameSpace以实现多租户特性,而Pulsar已实现这一功能。在企业中,消息队列服务通常会被多个团队使用,在使用Kafka时,有时需要为每个团队维护一个Kafka集群。Pulsar可以配置多个租户,每个租户可以有多个NameSpace,管理员可以对NameSpace进行访问控制、配额管理。
更灵活的订阅模式
Kafka对消息的划分分为两层:对于属于同一个Group的KafkaConsumer,其获取到的消息是互斥的,即某一条消息只能被Group中的一个Consumer处理;对于不同的Group,某一条消息将同时被两个Group处理,消息是共享的。
而Pulsar提供了更灵活的订阅模式:
- 独占式:
在任意时间,Topic中的数据只能被Group中的一个Consumer消费,不允许其他Consumer获取消息
- 主备式:
多个Consumer同时消费同一个Topic时,只有一个Consumer被选为主Consumer,其他Consumer则成为备Consumer。当主Consumer故障时,发生主备倒换,备Consumer中的一个将升主,并继续消息的消费。
- 共享式:
与Kafka类似,使用共享模式,消息将循环分发给不同的Consumer,当某个Consumer故障时,消息将被重新分配给其他Consumer。
分层存储
Pulsar另一个很有吸引里的特性是,流式数据可以转冷并存储在更廉价的存储介质上。通常为了保证性能,流式处理系统配备高性能的SSD。对于Kafka来说,所有需要保留的消息都必须驻留在昂贵的SSD上。有些时候,数据写入一段时间后已不在会被使用,但仍需保留一段时间存档。Pulsar支持将这种冷数据转储到离线存储系统中,BookKeeper只需要保留一部分热数据,可以节省很多存储成本。该特性无疑是很有价值的,Kafka社区同样在进行设计(KIP-405),但目前还没有实现。
Pulsar的性能指标
Kafka和Pulsar社区都针对性能进行了对比测试。综合来看,由于Pulsar数据落盘时,会进行同步fsync,持久性要比Kafka更高,Pulsar社区对此作出修改后进行对比测试,部分测试结果如下:
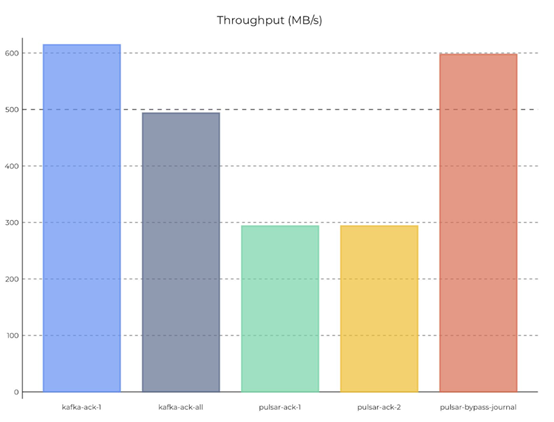
*引自Pulsar社区性能测试报告
在100 Partition时,默认配置下pulsar的吞吐量距离Kafka差距明显,但当本地持久化等级设置为与Kafka相同时,吞吐量与Kafka基本持平。
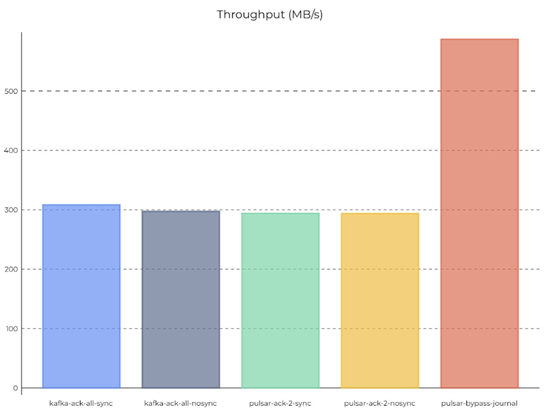
*引自Pulsar社区性能测试报告
当Partition数增加到2000个时,Pulsar默认本地持久度的吞吐量基本与Kafka持平。
更多细节请移步SreamNative的benckmarking测试报告:benchmarking pulsar kafka a more accurate perspective on pulsar performance.pdf
MRS上的Pulsar
MRS已发布Pulsar的POC版本,客户可以一键式部署Pulsar服务,包括Broker和Bookie角色。支持在Web UI上修改Pulsar配置、启停、监控。
此外MRS还默认集成了KoP。KoP是Pulsar社区开源的一个插件,运行在Pulsar上,用以兼容Kafka协议。使用时,Kafka客户端可以修改连接地址后直接切换到Pulsar集群上,而不需要修改业务对Kafka客户端的依赖。
在MRS Pulsar的商用版本正在规划中,我们将探索Pulsar在云上使用的更多可能,进一步发挥Pulsar存算分离的优势,降低成本,提升资源利用率,为客户创造更多价值,敬请期待。
分布式消息流平台:不要只想着Kafka,还有Pulsar的更多相关文章
- 大数据平台消息流系统Kafka
Kafka前世今生 随着大数据时代的到来,数据中蕴含的价值日益得到展现,仿佛一座待人挖掘的金矿,引来无数的掘金者.但随着数据量越来越大,如何实时准确地收集并分析如此大的数据成为摆在所有从业人员面前的难 ...
- 分布式消息系统:Kafka
Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务.它主要用于处理活跃的流式数据. ...
- 最牛分布式消息系统:Kafka
Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务.它主要用于处理活跃的流式数据. ...
- 高并发面试必问:分布式消息系统Kafka简介
转载:https://blog.csdn.net/caisini_vc/article/details/48007297 Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成 ...
- 分布式流平台Kafka
提到Kafka很多人的第一印象就是它是一个消息系统,但Kafka发展至今,它的定位已远不止于此,而是一个分布式流处理平台.对于一个流处理平台通常具有三个关键能力: 1. 发布和订阅消息流,在这一点上它 ...
- Pulsar云原生分布式消息和流平台v2.8.0
Pulsar云原生分布式消息和流平台 **本人博客网站 **IT小神 www.itxiaoshen.com Pulsar官方网站 Apache Pulsar是一个云原生的分布式消息和流媒体平台,最初创 ...
- kafka:一个分布式消息系统
1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布式实现的很奇怪,所以希望找一个适 ...
- KAFKA分布式消息系统
2015-01-05 大数据平台 Hadoop大数据平台 基本概念 kafka的工作方式和其他MQ基本相同,只是在一些名词命名上有些不同.为了更好的讨论,这里对这些名词做简单解释.通过这些解释应该可以 ...
- 分布式消息系统kafka
kafka:一个分布式消息系统 1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布 ...
随机推荐
- 浅析线程池 ThreadPoolExecutor 源码
首先看下类的继承关系,不多介绍: public interface Executor {void execute(Runnable);} public interface ExecutorServic ...
- Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言 MiddleWare,顾名思义,中间件.主要处理请求(例如添加代理IP.添加请求头等)和处理响应 本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件. MiddleWare分类 ...
- MyBatis使用Zookeeper保存数据库的配置,可动态刷新
核心关键点: 封装一个DataSource, 重写 getConnection 就可以实现 我们一步一步来看. 环境: Spring Cloud + MyBatis MyBatis常规方式下配置数据源 ...
- Maven-内部多个项目依赖自动升级版本的部署
需要自动升级版本的AAA项目发布 (有内部依赖时) 步骤比较复杂, 有一些需要根据实际情况调整. 考虑了以下几种可能性: 依赖模块的版本有更新 依赖模块版本没更新 依赖模块的版本号: 直接定义, 用属 ...
- 🏆(不要错过!)【CI/CD技术专题】「Jenkins实战系列」(3)Jenkinsfile+DockerFile实现自动部署
每日一句 没有人会因学问而成为智者.学问或许能由勤奋得来,而机智与智慧却有懒于天赋. 前提概要 Jenkins下用DockerFile自动部署Java项目,项目的部署放心推向容器化时代机制. 本节需要 ...
- 这个大表走索引字段查询的 SQL 怎么就成全扫描了,我TM人傻了
今天收到运营同学的一个 SQL,有点复杂,尤其是这个 SQL explain 都很长时间执行不出来,于是我们后台团队帮忙解决这个 SQL 问题,却正好发现了一个隐藏很深的线上问题. select a. ...
- CF474D Flowers 题解
题目:CF474D Flowers 传送门 DP?递推? 首先可以很快看出这是一道 DP 的题目,但与其说是 DP,还不如说是递推. 大家还记得刚学递推时教练肯定讲过的一道经典例题吗?就是爬楼梯,一个 ...
- python,ctf笔记随笔
一.在centos虚拟机中安装pyhton3环境: 安装pip3:yum install python36-pip 将pip升级到最新版本:pip3 install --upgrade pip 运行p ...
- js 原始数据类型、引用数据类型
js的数据类型划分方式为 原始数据类型和 引用数据类型 栈: 原始数据类型(Undefined,Null,Boolean,Number.String) 堆: 引用数据类型(对象.数组.函数) 两种类型 ...
- C++水仙花 (如:153 = 1*1*1 + 5*5*5 + 3*3*3)
1 #include <iostream> 2 #include <ctime> 3 using namespace std; 4 5 int main() 6 { 7 int ...