Flink State Rescale性能优化
背景
今天我们来聊一聊flink中状态rescale的性能优化。我们知道flink是一个支持带状态计算的引擎,其中的状态分为了operator state和 keyed state两类。简而言之operator state是和key无关只是到operator粒度的一些状态,而keyed state是和key绑定的状态。而Rescale,意味着某个状态节点发生了并发的缩扩。在任务不修改并发重启的情况下,我们只需要按照task,将先前job的各个并发的state handle重新分发处理下载远程的持久化的state文件即可恢复。而发生rescale时,状态的数据分布将发生变化,因此存在一个reshuffle的过程,那么我们就来看看这个rescale的实现是怎么做的,以及其问题和优化手段。
Rescale的实现
2017年社区有一篇博客就比较深入的介绍了Operator 和 keyed state的rescale的实现,感兴趣的话可以去了解下。
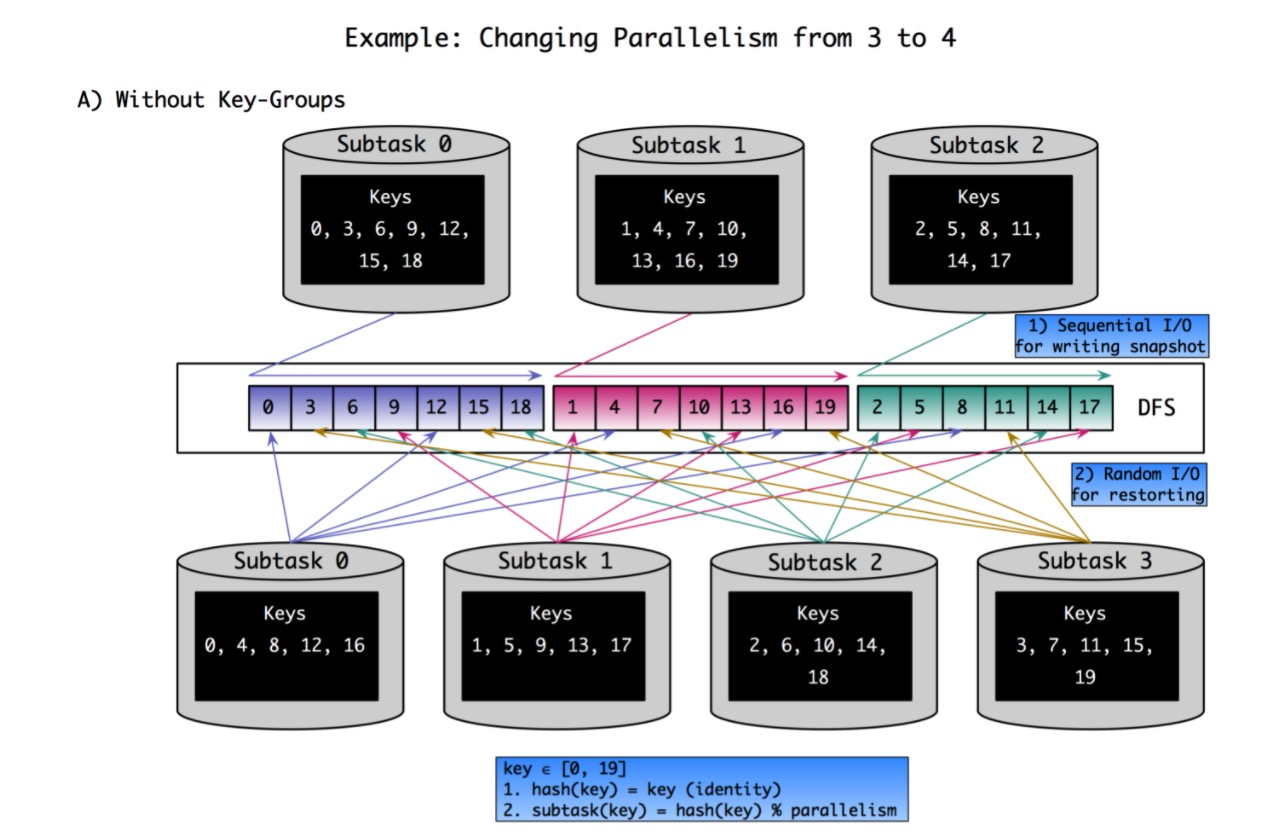
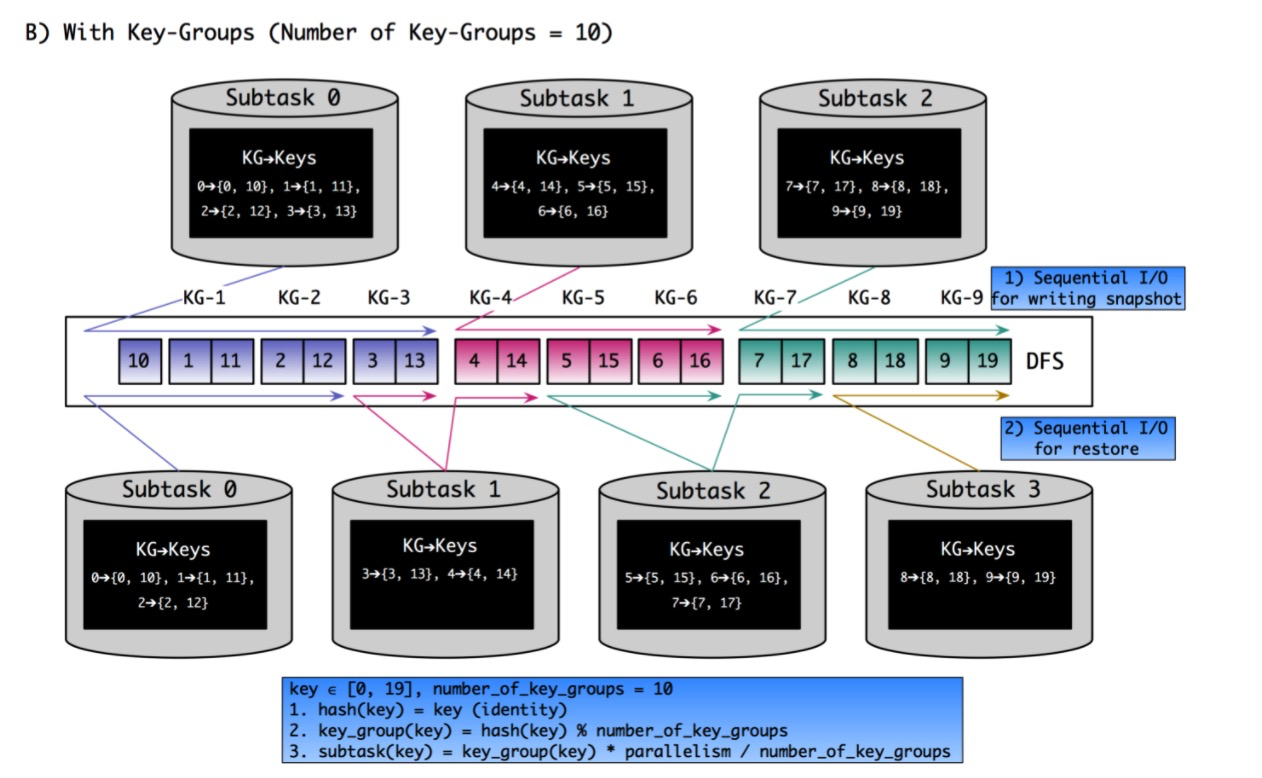
这两张图对比了是否基于keyGroup来划区的一个差别,社区中的版本使用的是基于keygroup的版本实现的,可以看到可以减少对于数据的random的访问。但是从B中我们看到,以rescale后的subtask为例:
- subtask-0: 需要将原先subtask-0的dfs文件下载后将KG-3的数据剔除掉。这里需要剔除的原因是: 虽然我们任务启动后由于keyshuffle的原因,subtask-0不会再接收到KG-3的数据,但是后续如果继续做checkpoint,会导致这部分数据重新被上传到DFS文件中,而如果继续发生rescale,就可能导致和其他subtask-1上的KG-3的数据发生冲突导致数据问题
- subtask-1: 需要download原先subtask-0和subtask-1的数据dfs文件,并将subtask-0中的KG-1和KG-2的数据删除,以及原先subtask-1中的 KG-5 和 KG-6删除,并将其导入到新的RocksDB实例中。
因此我们可以总结出rescale的大致流程中,首先会将当前task所涉及的db文件恢复到本地,并从中挑选出属于当前keygroup的数据重新构建出新的db。
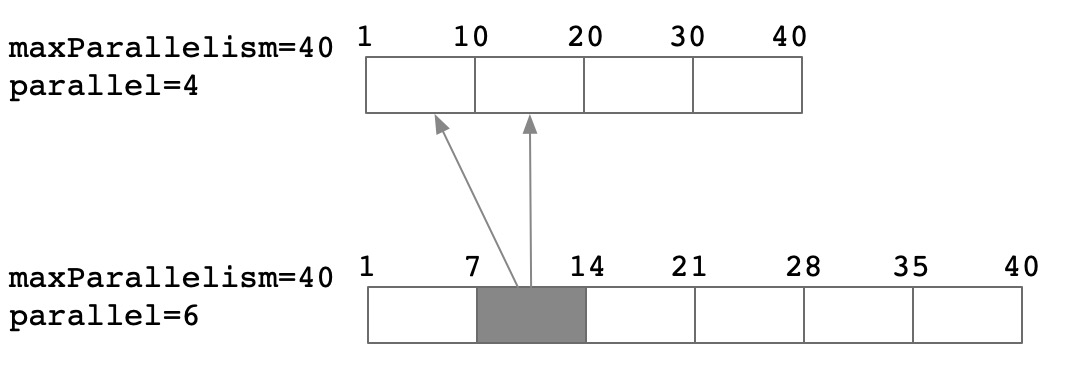
从理论上分析,在不同的并发调整场景下,其rescale的代价也不尽相同
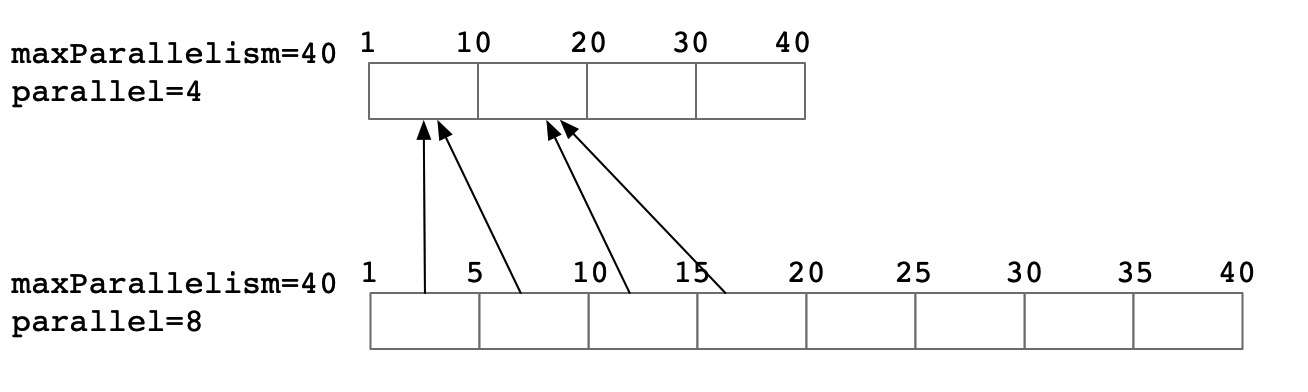
并发翻倍
1.5倍扩并发
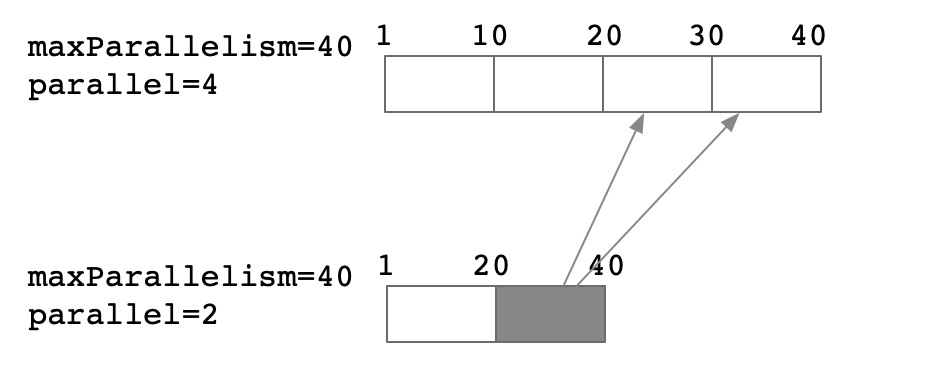
并发减半
接下来,我们在代码中确认相关的逻辑(代码基于Flink1.15版本)。
根据stateHandle元信息判断是否是rescale
我们可以看到当restoreStateHandles的数量大于1,或者stateHandle的keyGroupRange和当前task的range不一致时就是rescale的过程

在不是rescale的场景下,恢复的流程只需要将相应IncrementalRemoteKeyedStateHandle对应的文件下载到本地或者是直接使用local recovery中的 IncrementalLocalKeyedStateHandle所对应的本地文件的目录,直接执行 RocksDB.open()就可以将db数据恢复。
initialDB
首先根据keygroup的重叠比较,挑选出和当前keygroup有最大重叠范围的stateHandle作为initial state handle。这样的好处是可以尽可能利用最大重叠部分的数据,减少后续数据遍历的过程。在挑选出initial state handle 创建db之后,首先需要将db中不属于当前的task的keygroup的数据进行遍历删除。
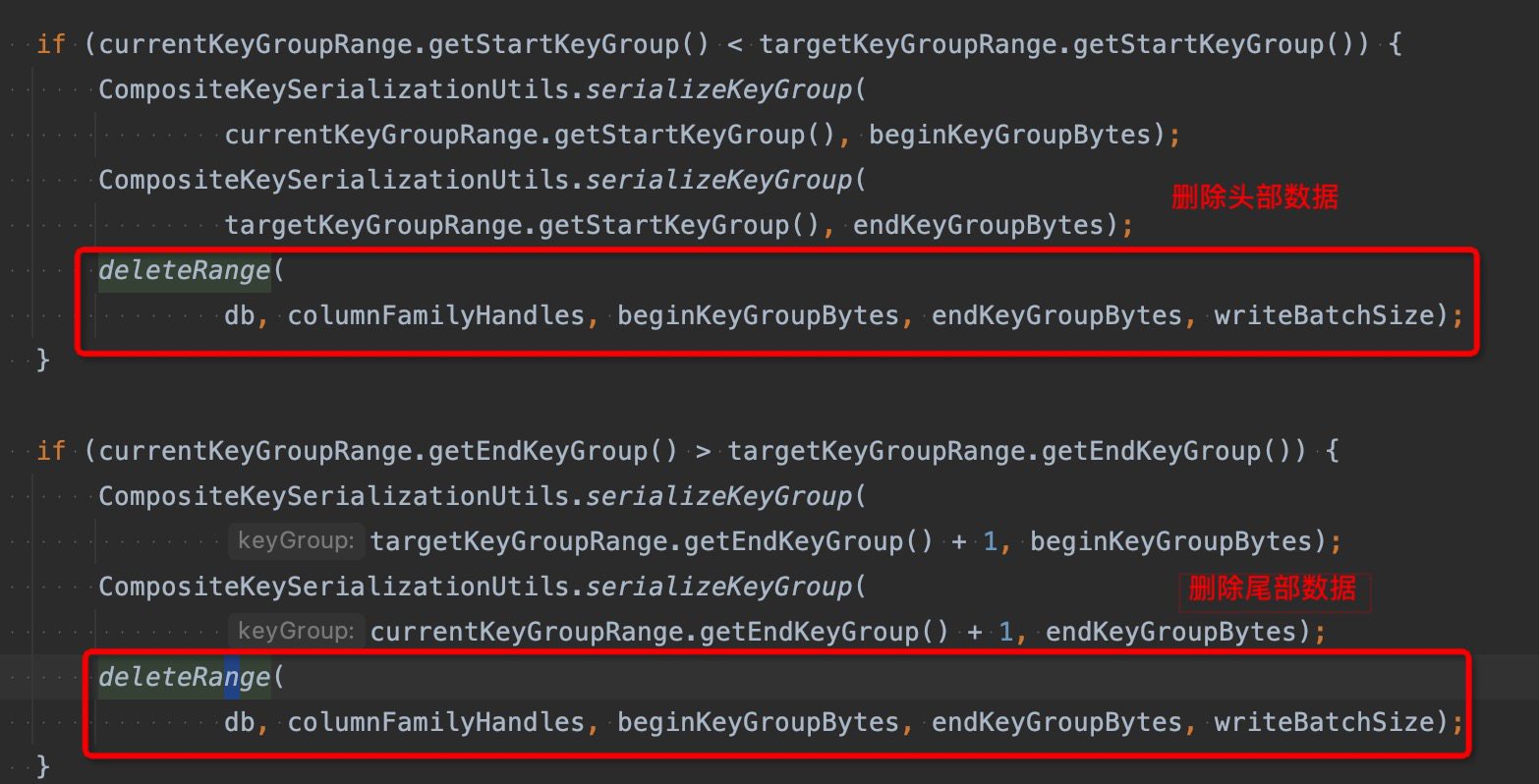
因为flink中存储的keyed state的数据已经按照keygroup作为前缀作为排序,所以只需要删除头部和尾部的数据即可,这样就不用遍历全量的数据。
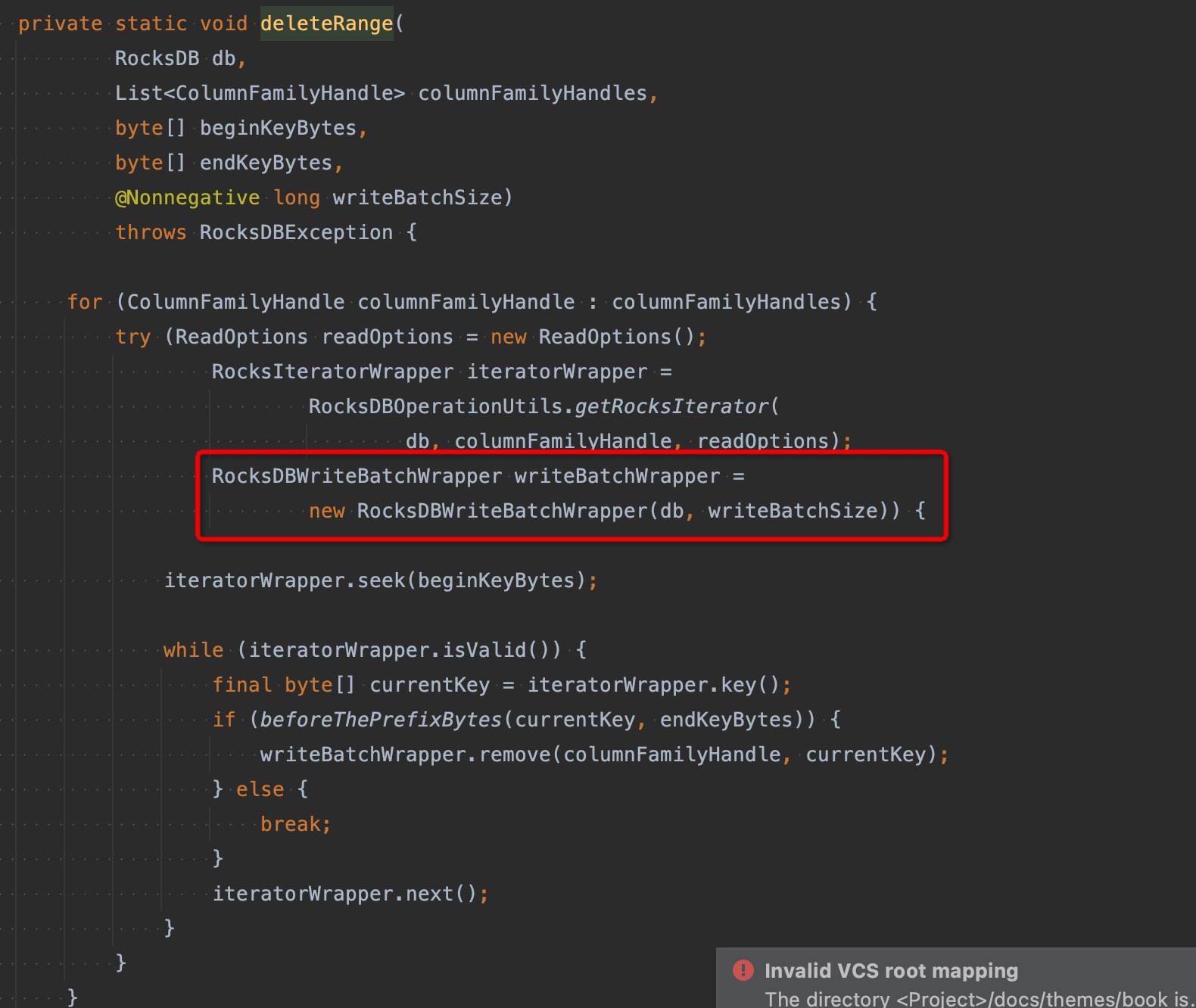
在当前的deleteRange的实现中是依赖遍历db,通过writeBatch的方式进行批量执行删除,这种方式当需要删除的key的基数较大时会比较耗时,并且都会触发io和compaction的开销,而rocksdb提供了deleteRange的接口,可以通过指定start和end key来进行快速的删除,经过测试下来基本只要ms级别就可以完成。参考 FLINK-21321
Bulk load
在完成base db裁剪之后,就需要将其他db的数据导入到base db中,目前的实现还是通过writeBatch来加速写入
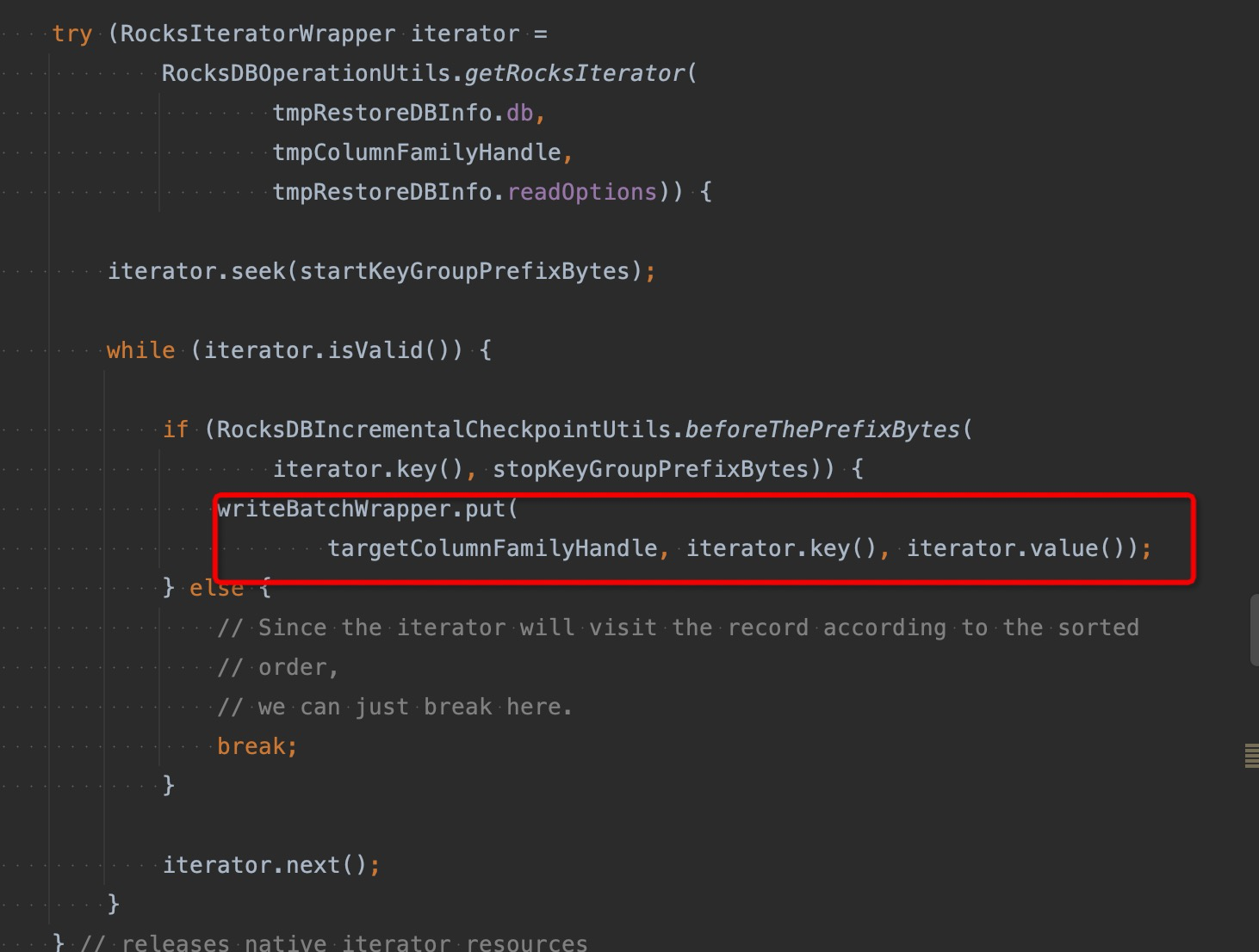
在 FLINK-17971 中作者提供了sst ingest 写入的实现,本质上是利用rocksdb 的sst writer的工具,通过sst writer能直接构建出sst 文件,避免了直接写的过程中的compaction的问题,然后通过 db.ingestExternalFile直接将其导入db中。实际测试的过程中这样的写入性能有2-3倍的提升。
Rescale的优化应该迭代优化了很多次,最开始的实现应该是将所有的statehandle的数据download下来,将其遍历写入新的db,在 FLINK-8790 中首先将其优化成 base db + delete Range + bulk load的方式,后续的两个pr又通过Rocksdb提供的deleteRange + SSTIngest 特性加速。虽然这些优化应用上只有rescale的提速很明显,但是当我们遇到key的基数非常大时,就会出现我们遍历原先的db next调用和 写入的耗时也非常的大,因此rescale的场景可能还需要继续优化。
关于RocksDB中deleteRange和SST Ingest功能笔者也做了一些研究,在后续的文章中会陆续更新出来,敬请期待
参考
https://blog.csdn.net/Z_Stand/article/details/115799605 sst ingest 原理
http://rocksdb.org/blog/2017/02/17/bulkoad-ingest-sst-file.html
https://rocksdb.org/blog/2018/11/21/delete-range.html delete range原理
Flink State Rescale性能优化的更多相关文章
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-<Fink原理.实战与性能优化>读书笔记 1.1 Apache Flink是什么? 在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如 ...
- C#中那些[举手之劳]的性能优化
隔了很久没写东西了,主要是最近比较忙,更主要的是最近比较懒...... 其实这篇很早就想写了 工作和生活中经常可以看到一些程序猿,写代码的时候只关注代码的逻辑性,而不考虑运行效率 其实这对大多数程序猿 ...
- Mysql - 性能优化之子查询
记得在做项目的时候, 听到过一句话, 尽量不要使用子查询, 那么这一篇就来看一下, 这句话是否是正确的. 那在这之前, 需要介绍一些概念性东西和mysql对语句的大致处理. 当Mysql Server ...
- MYSQL性能优化的最佳20+条经验
MYSQL性能优化的最佳20+条经验 2009年11月27日 陈皓 评论 148 条评论 131,702 人阅读 今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数 ...
- React 组件性能优化
React组件性能优化 前言 众所周知,浏览器的重绘和重排版(reflows & repaints)(DOM操作都会引起)才是导致网页性能问题的关键.而React虚拟DOM的目的就是为了减少浏 ...
- CentOS 6.5 安全加固及性能优化 (转)
通过修改CentOS 6.5 的系统默认设置,对系统进行安全加固,进行系统的性能优化. 环境: 系统硬件:vmware vsphere (CPU:2*4核,内存2G) 系统版本:Centos-6.5- ...
- Android应用性能优化(转)
人类大脑与眼睛对一个画面的连贯性感知其实是有一个界限的,譬如我们看电影会觉得画面很自然连贯(帧率为24fps),用手机当然也需要感知屏幕操作的连贯性(尤其是动画过度),所以Android索性就把达到这 ...
- EntityFramework之原始查询及性能优化(六)
前言 在EF中我们可以通过Linq来操作实体类,但是有些时候我们必须通过原始sql语句或者存储过程来进行查询数据库,所以我们可以通过EF Code First来实现,但是SQL语句和存储过程无法进行映 ...
随机推荐
- netcore XmlDocument 使用Load和Save方法
string path ="C://xxx/file" XmlDocument xmlDoc = new XmlDocument(); #if NET462 xmlDoc.Load ...
- 简单聊聊mysql的脏读、不可重复读
最近,在一次 mysql 死锁的生产事故中,我发现,关于 mysql 的锁.事务等等,我所知道的东西太碎了,所以,我试着用几个例子将它们串起来.具体做法就是通过不断地问问题.回答问题,再加上" ...
- -bash: /etc/ld.so.preload: Operation not permitted处理
执行 chattr -i /etc/ld.so.preload 执行 chattr -a /etc/ld.so.preload
- 『与善仁』Appium基础 — 28、webview的操作方式
目录 1.先了解什么是Hybrid(混合) 2.识别Webview 3.context上下文 4.Webview和原生页面之前的切换 5.综合练习 我们之前说过的所有操作,都是对原生页面的操作. 在手 ...
- html5调用摄像头截图
关于html5调用音视频等多媒体硬件的API已经很成熟,不过一直找不到机会把这些硬件转化为实际的应用场景,不过近年来随着iot和AI的浪潮,我觉得软硬结合的时机已经成熟.那我们就提前熟悉下怎么操作这些 ...
- 【九度OJ】题目1431:Sort 解题报告
[九度OJ]题目1431:Sort 解题报告 标签(空格分隔): 九度OJ [LeetCode] http://ac.jobdu.com/problem.php?pid=1431 题目描述: 给你n个 ...
- Docker 与 K8S学习笔记(八)—— 自定义容器网络
我们在上一篇中介绍了Docker中三种网络,none.host和bridge,除了这三种网络,Docker还允许我们创建自定义网络,当我们要创建自定义网络时,Docker提供了三种网络驱动供我们选择: ...
- 剖析Defi之Uinswap_0
Uniswap是什么,不需要讲了吧.YYDS(永远嘀神) 介绍几个概念: 恒定乘积算法:可以简单看作X * Y = K,这里K(乘积)保持不变,所以叫恒定乘积算法,该函数是一个反曲线. 自动流动性协议 ...
- SpringCloud创建Eureka模块
1.说明 本文详细介绍Spring Cloud创建Eureka模块的方法, 基于已经创建好的Spring Cloud父工程, 请参考SpringCloud创建项目父工程, 在里面创建Eureka模块, ...
- x86-2-保护模式(protect mode)
x86-2-保护模式(protect mode) 引入保护模式的原因: 操作系统负责计算机上的所有软件和硬件的管理,它可以百分百操作计算机的所有内容.但是,操作系统上编写的用户程序却应当有所限制,比如 ...