《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门、概念、原理、实战、性能调优、系统案例的讲解。
专栏介绍
扫码下面专栏二维码可以订阅该专栏

首发地址:http://www.54tianzhisheng.cn/2019/11/15/flink-in-action/
专栏地址:https://gitbook.cn/gitchat/column/5dad4a20669f843a1a37cb4f
专栏亮点
全网首个使用最新版本 Flink 1.9 进行内容讲解(该版本更新很大,架构功能都有更新),领跑于目前市面上常见的 Flink 1.7 版本的教学课程。
包含大量的实战案例和代码去讲解原理,有助于读者一边学习一边敲代码,达到更快,更深刻的学习境界。目前市面上的书籍没有任何实战的内容,还只是讲解纯概念和翻译官网。
在专栏高级篇中,根据 Flink 常见的项目问题提供了排查和解决的思维方法,并通过这些问题探究了为什么会出现这类问题。
在实战和案例篇,围绕大厂公司的经典需求进行分析,包括架构设计、每个环节的操作、代码实现都有一一讲解。
为什么要学习 Flink?
随着大数据的不断发展,对数据的及时性要求越来越高,实时场景需求也变得越来越多,主要分下面几大类:
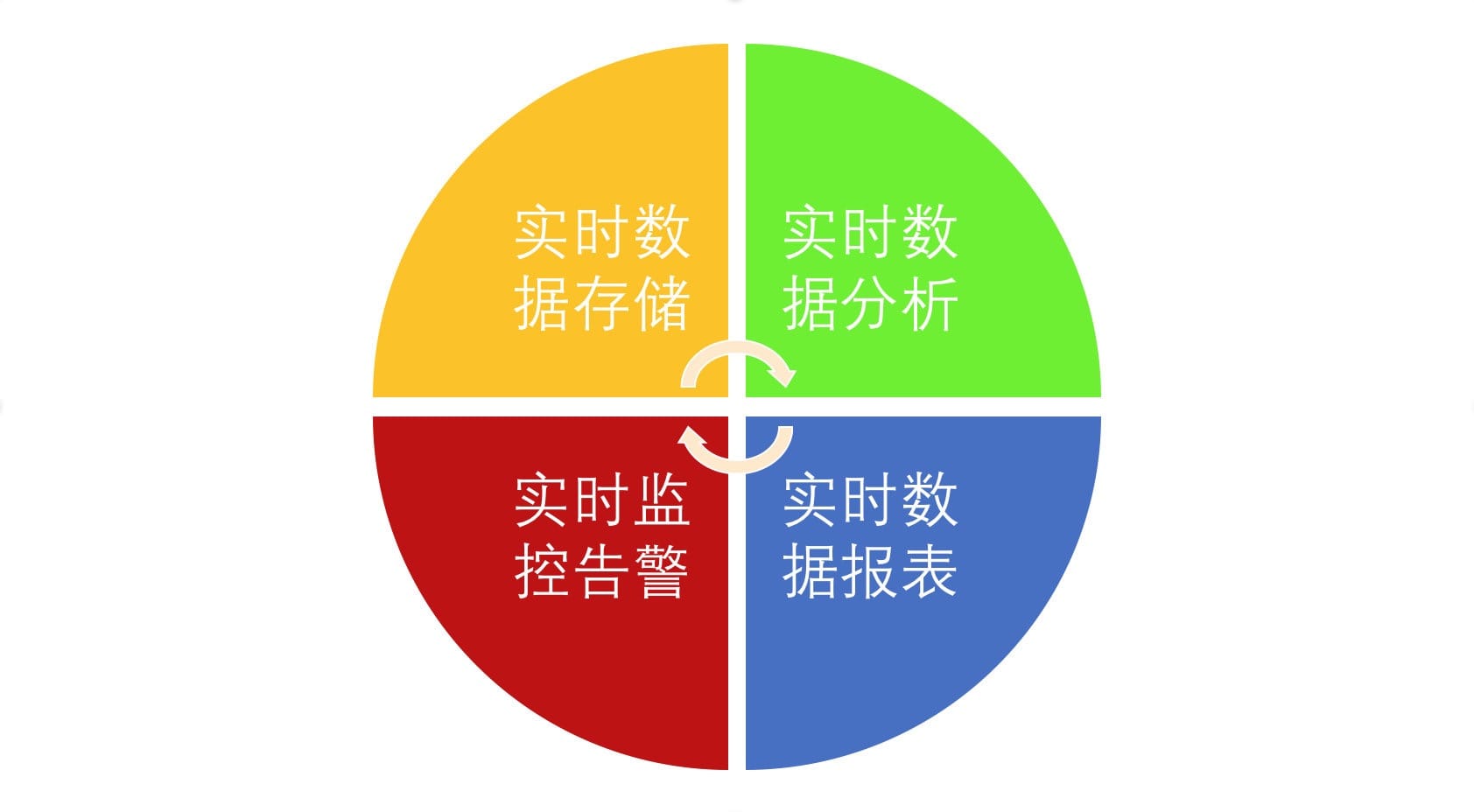
为了满足这些实时场景的需求,衍生出不少计算引擎框架。现有市面上的大数据计算引擎的对比如下图所示:
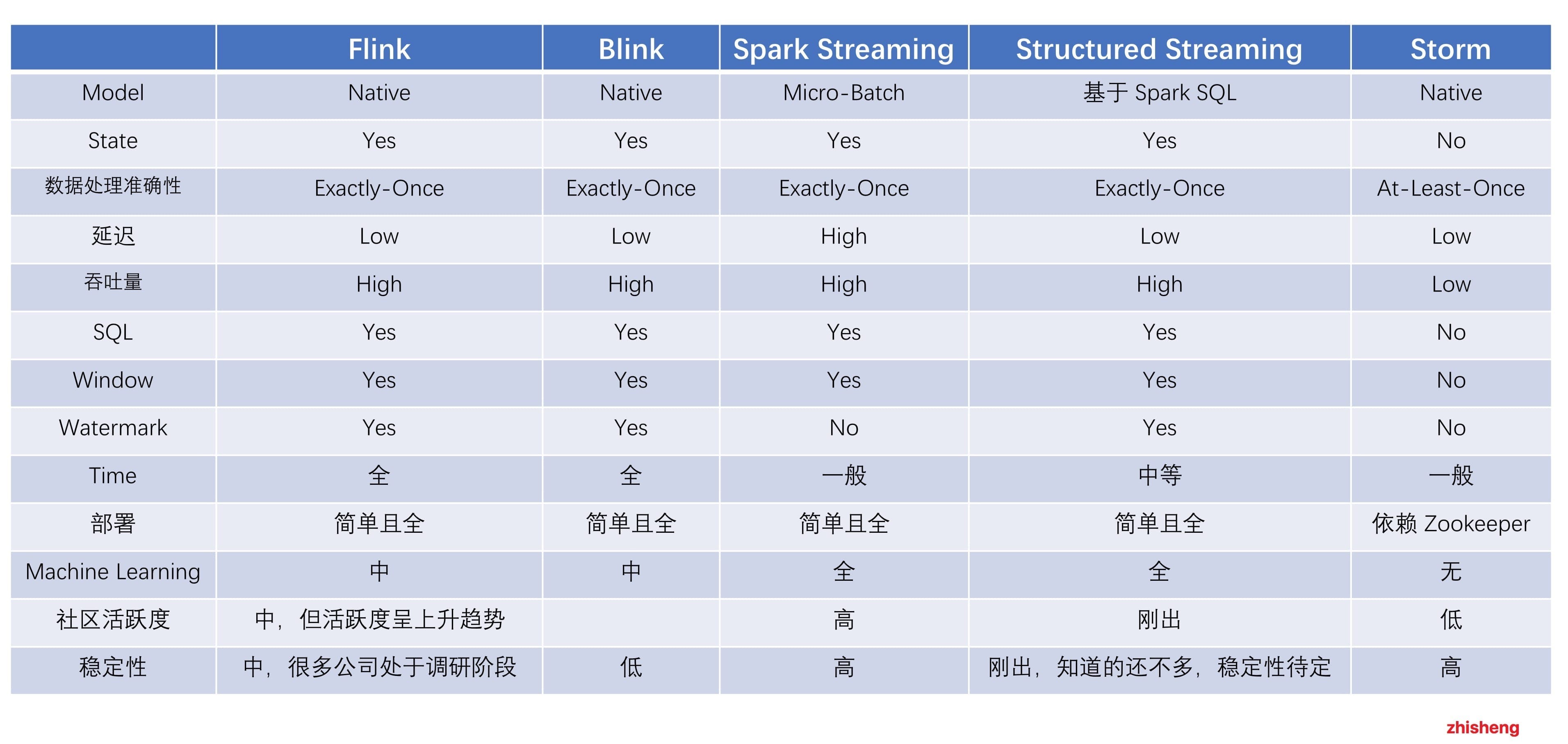
可以发现无论从 Flink 的架构设计上,还是从其功能完整性和易用性来讲都是领先的,再加上 Flink 是阿里巴巴主推的计算引擎框架,所以从去年开始就越来越火了!
目前,阿里巴巴、腾讯、美团、华为、滴滴出行、携程、饿了么、爱奇艺、有赞、唯品会等大厂都已经将 Flink 实践于公司大型项目中,带起了一波 Flink 风潮,势必也会让 Flink 人才市场产生供不应求的招聘现象。
专栏内容

预备篇
介绍实时计算常见的使用场景,讲解 Flink 的特性,并且对比了 Spark Streaming、Structured Streaming 和 Storm 等大数据处理引擎,然后准备环境并通过两个 Flink 应用程序带大家上手 Flink。
基础篇
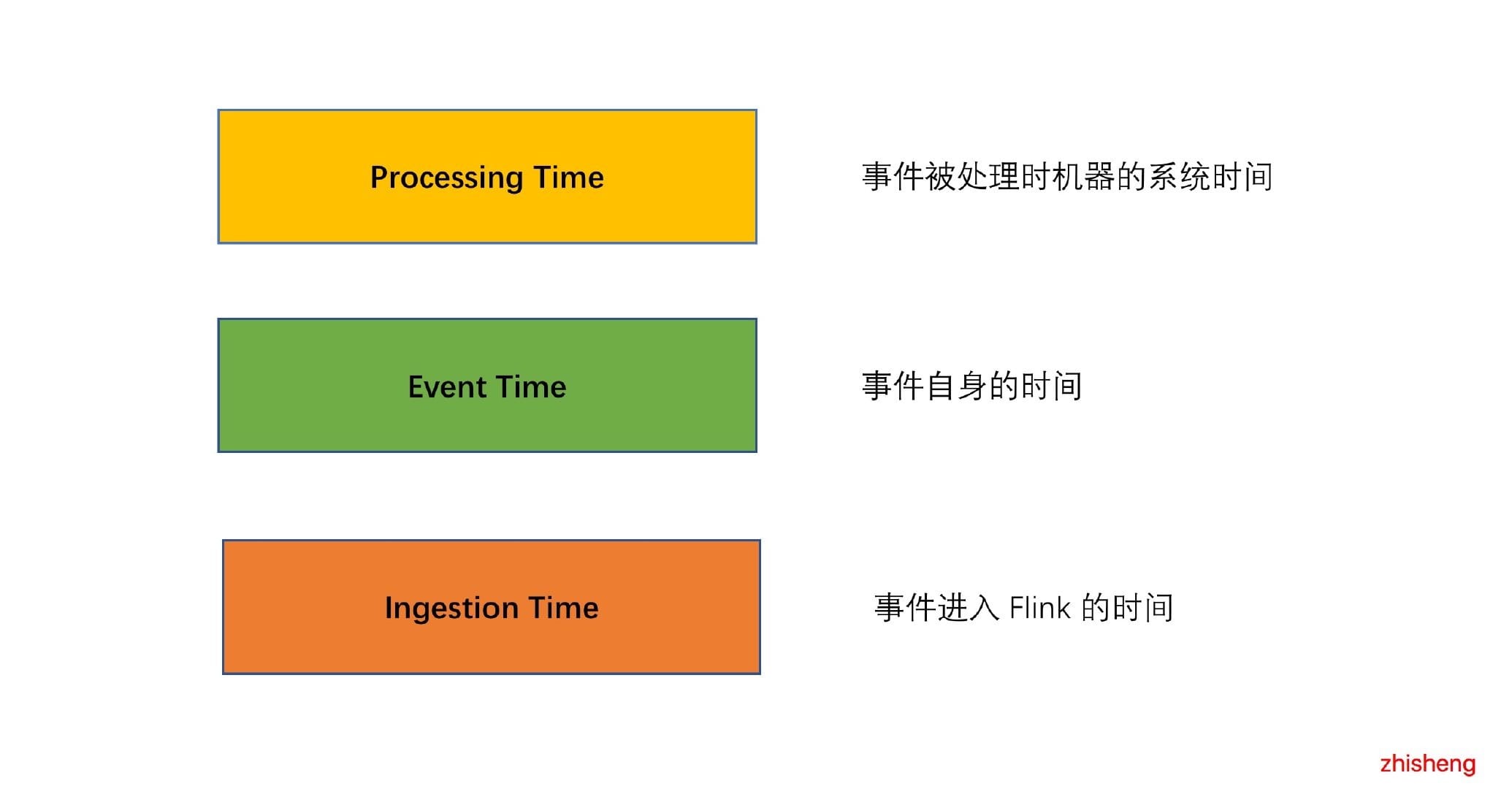
深入讲解 Flink 中 Time、Window、Watermark、Connector 原理,并有大量文章篇幅(含详细代码)讲解如何去使用这些 Connector(比如 Kafka、ElasticSearch、HBase、Redis、MySQL 等),并且会讲解使用过程中可能会遇到的坑,还教大家如何去自定义 Connector。
进阶篇
讲解 Flink 中 State、Checkpoint、Savepoint、内存管理机制、CEP、Table/SQL API、Machine Learning 、Gelly。在这篇中不仅只讲概念,还会讲解如何去使用 State、如何配置 Checkpoint、Checkpoint 的流程和如何利用 CEP 处理复杂事件。
高级篇
重点介绍 Flink 作业上线后的监控运维:如何保证高可用、如何定位和排查反压问题、如何合理的设置作业的并行度、如何保证 Exactly Once、如何处理数据倾斜问题、如何调优整个作业的执行效率、如何监控 Flink 及其作业?
实战篇
教大家如何分析实时计算场景的需求,并使用 Flink 里面的技术去实现这些需求,比如实时统计 PV/UV、实时统计商品销售额 TopK、应用 Error 日志实时告警、机器宕机告警。这些需求如何使用 Flink 实现的都会提供完整的代码供大家参考,通过这些需求你可以学到 ProcessFunction、Async I/O、广播变量等知识的使用方式。
系统案例篇
讲解大型流量下的真实案例:如何去实时处理海量日志(错误日志实时告警/日志实时 ETL/日志实时展示/日志实时搜索)、基于 Flink 的百亿数据实时去重实践(从去重的通用解决方案 --> 使用 BloomFilter 来实现去重 --> 使用 Flink 的 KeyedState 实现去重)。
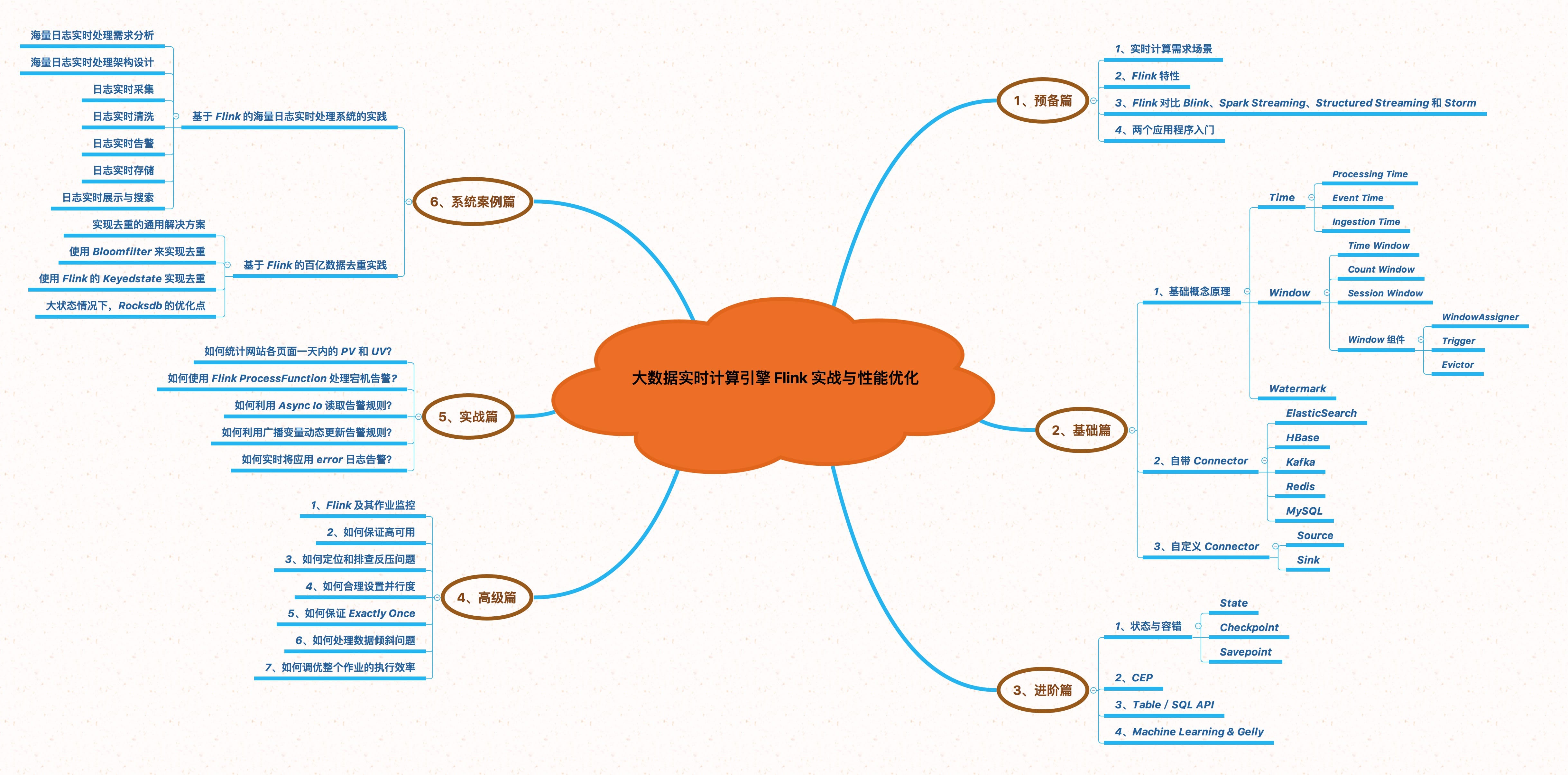
多图讲解 Flink 知识点
你将获得什么
- 掌握 Flink 与其他计算框架的区别
- 掌握 Flink Time/Window/Watermark/Connectors 概念和实现原理
- 掌握 Flink State/Checkpoint/Savepoint 状态与容错
- 熟练使用 DataStream/DataSet/Table/SQL API 开发 Flink 作业
- 掌握 Flink 作业部署/运维/监控/性能调优
- 学会如何分析并完成实时计算需求
- 获得大型高并发流量系统案例实战项目经验
适宜人群
- Flink 爱好者
- 实时计算开发工程师
- 大数据开发工程师
- 计算机专业研究生
- 有实时计算场景场景的 Java 开发工程师
原文出处:zhisheng的博客,欢迎关注我的公众号:zhisheng
《大数据实时计算引擎 Flink 实战与性能优化》新专栏的更多相关文章
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- Storm 实战:构建大数据实时计算
Storm 实战:构建大数据实时计算(阿里巴巴集团技术丛书,大数据丛书.大型互联网公司大数据实时处理干货分享!来自淘宝一线技术团队的丰富实践,快速掌握Storm技术精髓!) 阿里巴巴集团数据平台事业部 ...
- 阿里云DataWorks正式推出Stream Studio:为用户提供大数据实时计算的数据中台
5月15日 阿里云DataWorks正式推出Stream Studio,正式为用户提供大数据的实时计算能力,同时标志着DataWorks成为离线.实时双计算领域的数据中台. 据介绍,Stream St ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
- 《storm实战-构建大数据实时计算读书笔记》
自己的思考: 1.接收任务到任务的分发和协调 nimbus.supervisor.zookeeper 2.高容错性 各个组件都是无状态的,状态 ...
- Storm大数据实时计算
大数据也是构建各类系统的时候一种全新的思维,以及架构理念,比如Storm,Hive,Spark,ZooKeeper,HBase,Elasticsearch,等等 storm,在做热数据这块,如果要做复 ...
- 大数据笔记(二十二)——大数据实时计算框架Storm
一. 1.对比:离线计算和实时计算 离线计算:MapReduce,批量处理(Sqoop-->HDFS--> MR ---> HDFS) 实时计算:Storm和Spark Sparki ...
- 入门大数据---Hive计算引擎Tez简介和使用
一.前言 Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎.至于为什么提高了计算速度,可以参考下图: 用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Re ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
随机推荐
- map转换成com.google.gson.JsonObject
String json =new Gson().toJson(map); JsonObject jsonObject =new JsonParser().parse(json).getAsJsonOb ...
- 【爬虫小程序:爬取斗鱼所有房间信息】Xpath(协程池版)
# 本程序亲测有效,用于理解爬虫相关的基础知识,不足之处希望大家批评指正 from gevent import monkey monkey.patch_all() from gevent.pool i ...
- maven私服 nexus 的安装与使用
简介 私服不是Maven的核心概念,它仅仅是一种衍生出来的特殊的Maven仓库.通过建立自己的私服,就可以降低中央仓库负荷.节省外网带宽.加速Maven构建.自己部署构建等,从而高效地使用Maven. ...
- java基础之循环遍历List和Map
List和Map是在编程中使用的最频繁的集合类型了,每天都不知道要见它们多少面.在这里介绍下这两种类型的循环遍历,以供学习参考和使用. 一.List 遍历List一般有三种方法,如下: List< ...
- SpringBootSecurity学习(17)前后端分离版之 OAuth2.0 数据库(JDBC)存储客户端
自动批准授权码 前面我们授权的流程中,第一步获取授权码的时候,都会经历一个授权是否同意页面: 这个流程就像第三方登录成功后,提问是否允许获取昵称和头像信息的页面一样,这个过程其实是可以自动同意的,需要 ...
- 快学Scala 第二课 (apply, if表达式,循环,函数的带名参数,可变长参数,异常)
apply方法是Scala中十分常见的方法,你可以把这种用法当做是()操作符的重载形式. 像以上这样伴生对象的apply方法是Scala中构建对象的常用手法,不再需要使用new. if 条件表达式的值 ...
- MongoDB 学习笔记之 索引选项和重建索引
索引选项: {background:true}在后台创建索引,索引在构建过程中,其他客户端仍然可以查询数据,不会阻塞. db.comments.createIndex({anonymous: 1},{ ...
- 用OllyDbg爆破一个小程序
用OllyDbg爆破一个小程序 一.TraceMe小程序 TraceMe是对用户名.序列号判断是否合法的一个小程序.我们任意输入一组用户名.序列号进行check判断,结果如下: 二.用OllyDbg对 ...
- mybatis的环境搭建以及问题
1.mybatis中3个重要的类或者接口 1)SqlSessionFactoryBuilder类 用它来创建工厂对象,它重载了9次build()方法,我们常用build(inputstream)来创建 ...
- Java并发编程总结(一)Syncronized解析
Syncronized解析 作用: )确保线程互斥的访问同步代码 )保证共享变量的修改能够及时可见 )有效解决重排序问题. 用法: )修饰普通方法(锁是当前实例对象) )修饰静态方法(锁是当前对象的C ...