Sharding Sphere的分库分表
什么是 ShardingSphere?
|
1、数据库数据量不可控的,随着时间和业务发展,造成表里面数据越来越多,如果再去对数据库表 curd 操作时候,造成性能问题。
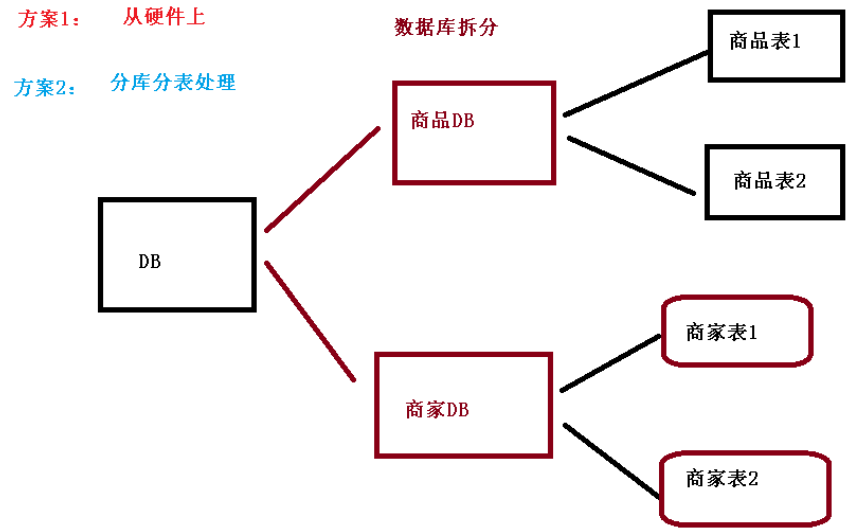
2、方案 1:从硬件上
3、方案 2:分库分表
* 为了解决由于数据量过大而造成数据库性能降低问题。
|
|
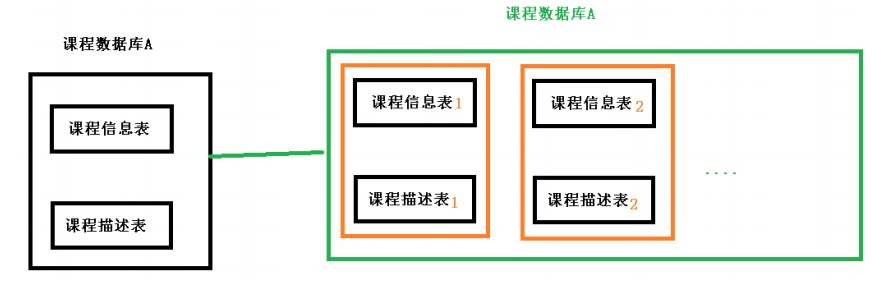
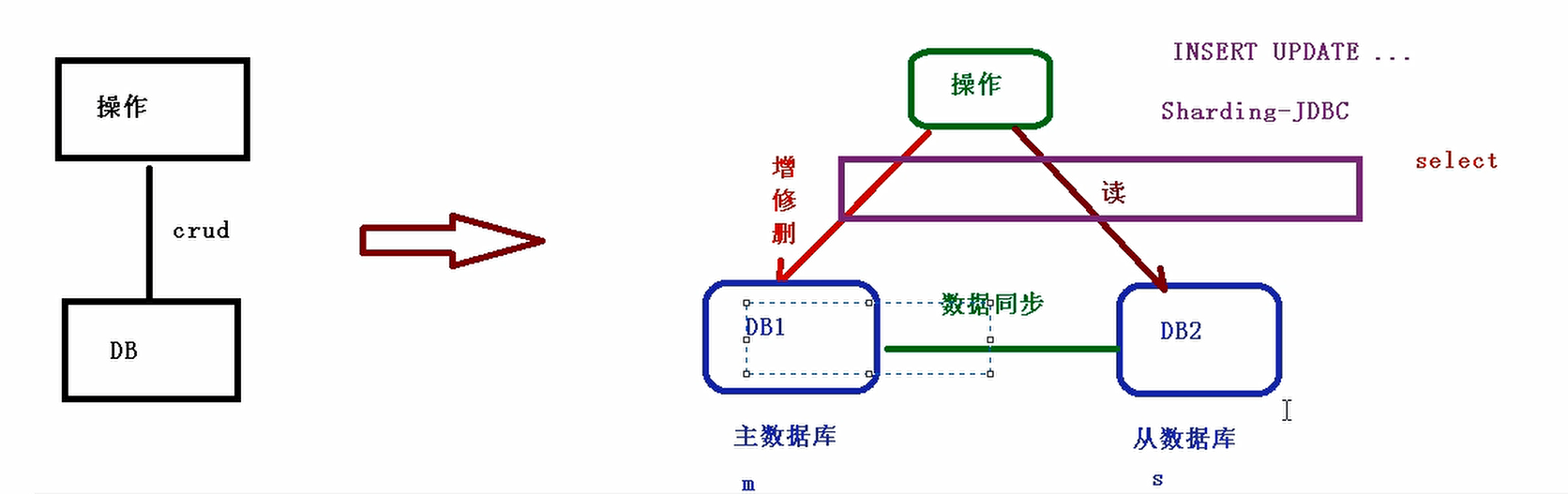
1、分库分表有两种方式:垂直切分和水平切分
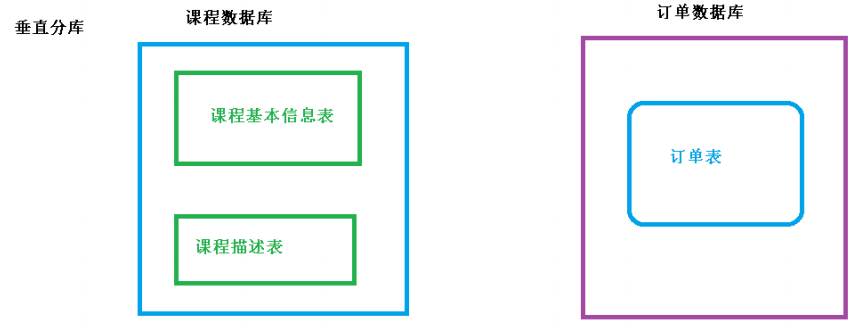
2、垂直切分:垂直分表和垂直分库
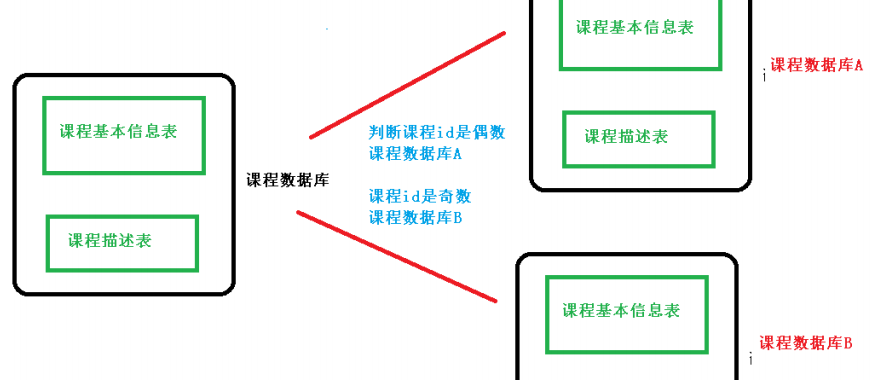
3、水平切分:水平分表和水平分库
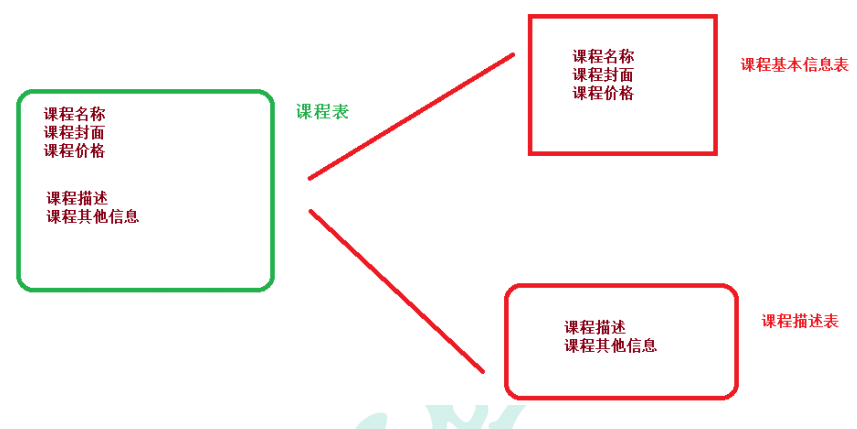
4、垂直分表
(1)操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一
部分字段数据存到另外一张表里面
|
|
1、应用
(1)在数据库设计时候考虑垂直分库和垂直分表
(2)随着数据库数据量增加,不要马上考虑做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题了,再考虑做水平分库和水平分表
2、分库分表问题
(1)跨节点连接查询问题(分页、排序)
(2)多数据源管理问题
|
|
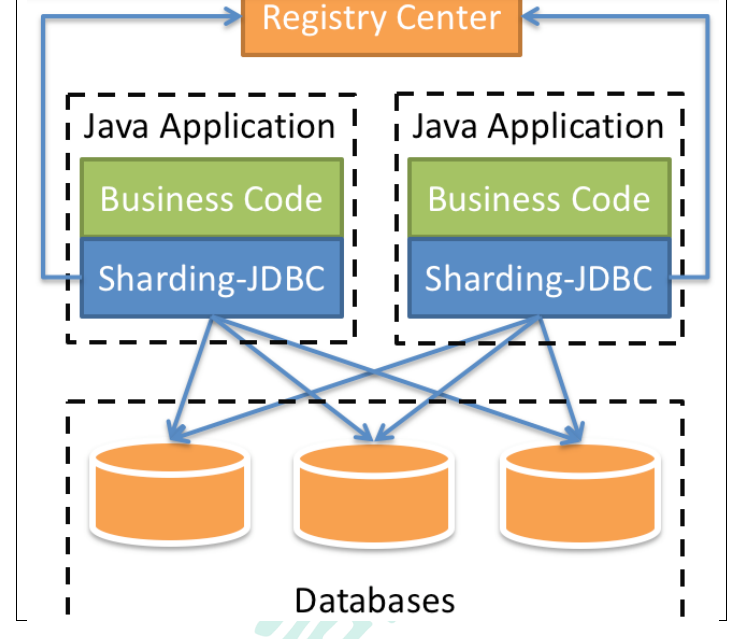
1、是轻量级的 java 框架,是增强版的 JDBC 驱动
2、Sharding-JDBC
(1)主要目的是:简化对分库分表之后数据相关操作
|
(4)引入需要的依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>

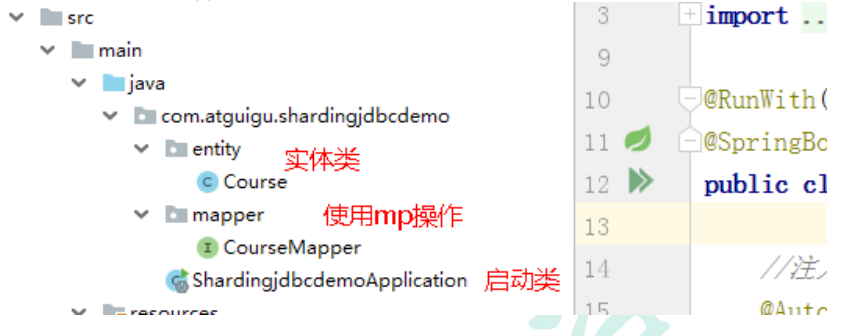

# shardingjdbc 分片策略
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true #配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingjdbcdemoApplicationTests {
//注入 mapper
@Autowired
private CourseMapper courseMapper;
//添加课程的方法
@Test
public void addCourse() {
for(int i=1;i<=10;i++) {
Course course = new Course();
course.setCname("java"+i);
course.setUserId(100L);
course.setCstatus("Normal"+i);
courseMapper.insert(course);
}
}
//查询课程的方法
@Test
public void findCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid",465114665106538497L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}

# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true

# shardingjdbc 分片策略
# 配置数据源,给数据源起名称,
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=m1,m2
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=root
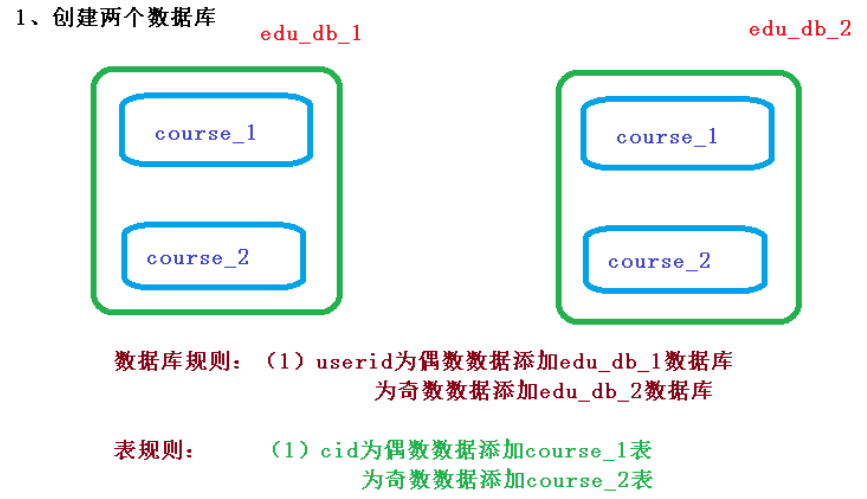
#指定数据库分布情况,数据库里面表分布情况
# m1 m2 course_1 course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# 指定 course 表里面主键 cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到course_2 表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.shardingcolumn=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithmexpression=course_$->{cid % 2 + 1}
# 指定数据库分片策略 约定 user_id 是偶数添加 m1,是奇数添加 m2
#spring.shardingsphere.sharding.default-database-strategy.inline.shardingcolumn=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm- expression=m$->{user_id % 2 + 1}
spring.shardingsphere.sharding.tables.course.databasestrategy.inline..sharding-column=user_id
spring.shardingsphere.sharding.tables.course.databasestrategy.inline.algorithm-expression=m$->{user_id % 2 + 1} # 打开 sql 输出日志
spring.shardingsphere.props.sql.show=tru
//======================测试水平分库=====================
//添加操作
@Test
public void addCourseDb() {
Course course = new Course();
course.setCname("javademo1");
//分库根据 user_id
course.setUserId(111L);
course.setCstatus("Normal1");
courseMapper.insert(course);
}
//查询操作
@Test
public void findCourseDb() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
//设置 userid 值
wrapper.eq("user_id",100L);
//设置 cid 值
wrapper.eq("cid",465162909769531393L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}

@Data
@TableName(value = "t_user") //指定对应表
public class User {
private Long userId;
private String username;
private String ustatus; }
* 在 application.properties 进行配置
# shardingjdbc 分片策略
# 配置数据源,给数据源起名称,
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=m1,m2,m0
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=root #配置第三个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
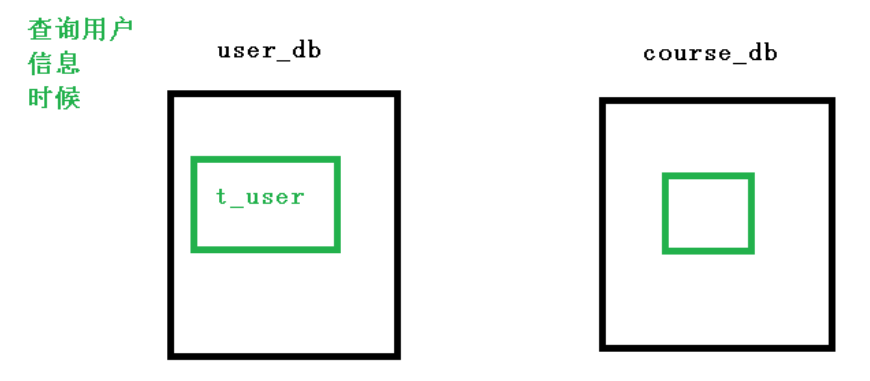
# 配置 user_db 数据库里面 t_user 专库专表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user
# 指定 course 表里面主键 cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定 cid 值偶数添加到 course_1 表,如果 cid 是奇数添加到course_2 表
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.shardingcolumn=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithmexpression=t_user
//注入 user 的 mapper
@Autowired
private UserMapper userMapper;
//======================测试垂直分库==================
//添加操作
@Test
public void addUserDb() {
User user = new User();
user.setUsername("lucy");
user.setUstatus("a");
userMapper.insert(user);
}
|
1、公共表
(1)存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
(2)在每个数据库中创建出相同结构公共表
2、在多个数据库都创建相同结构公共表
|
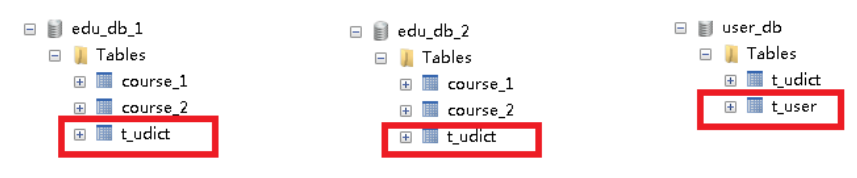
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_udict
spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid
spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE
@Data
@TableName(value = "t_udict")
public class Udict {
private Long dictid;
private String ustatus;
private String uvalue; }
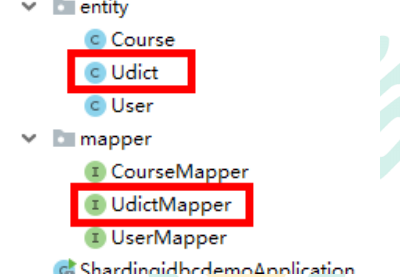
@Autowired
private UdictMapper udictMapper;
//======================测试公共表===================
//添加操作
@Test
public void addDict() {
Udict udict = new Udict();
udict.setUstatus("a");
udict.setUvalue("已启用");
udictMapper.insert(udict);
} //删除操作
@Test
public void deleteDict() {
QueryWrapper<Udict> wrapper = new QueryWrapper<>();
//设置 userid 值
wrapper.eq("dictid",465191484111454209L);
udictMapper.delete(wrapper);
}
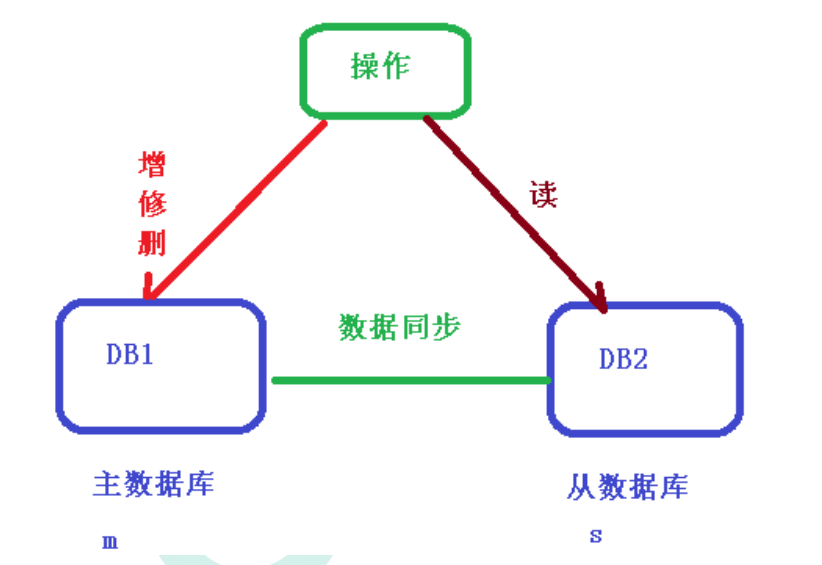
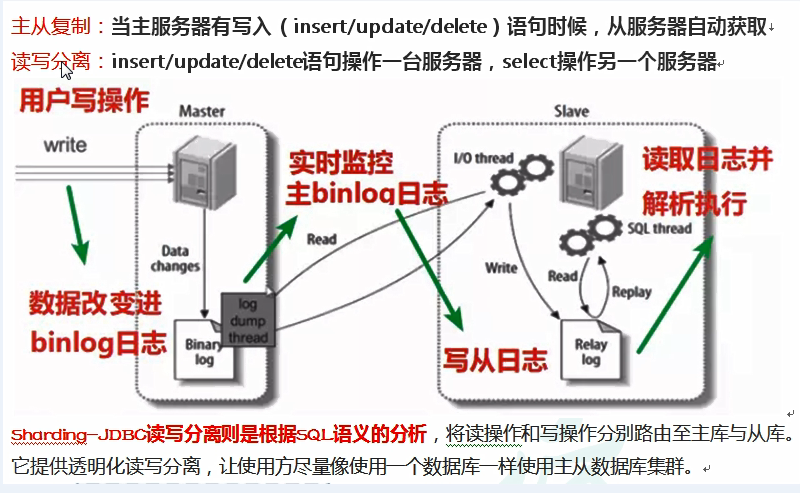
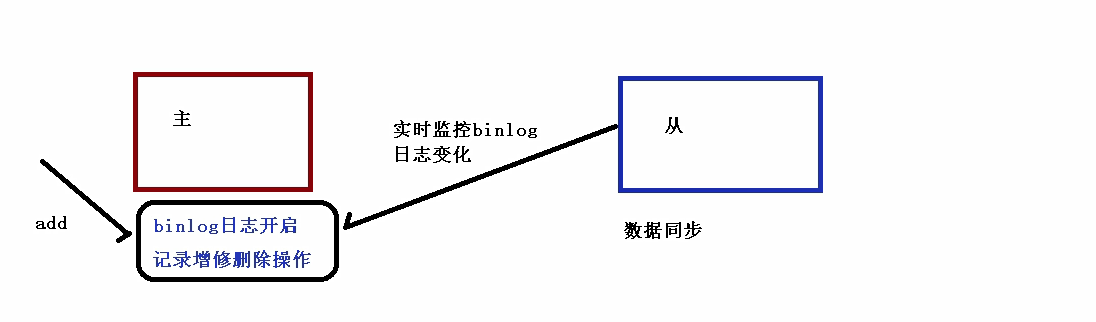
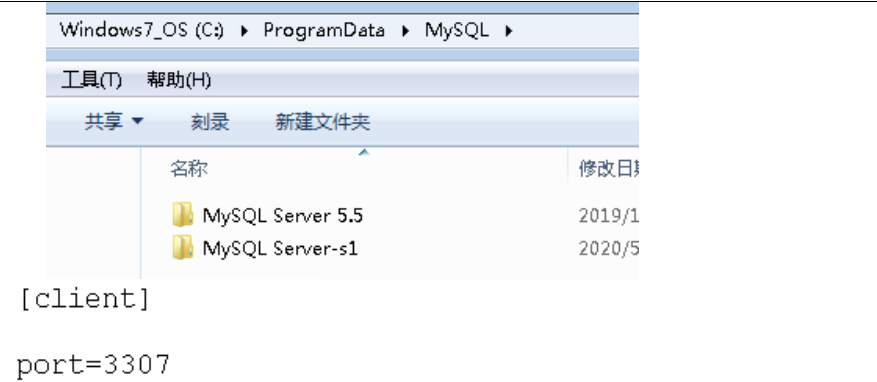
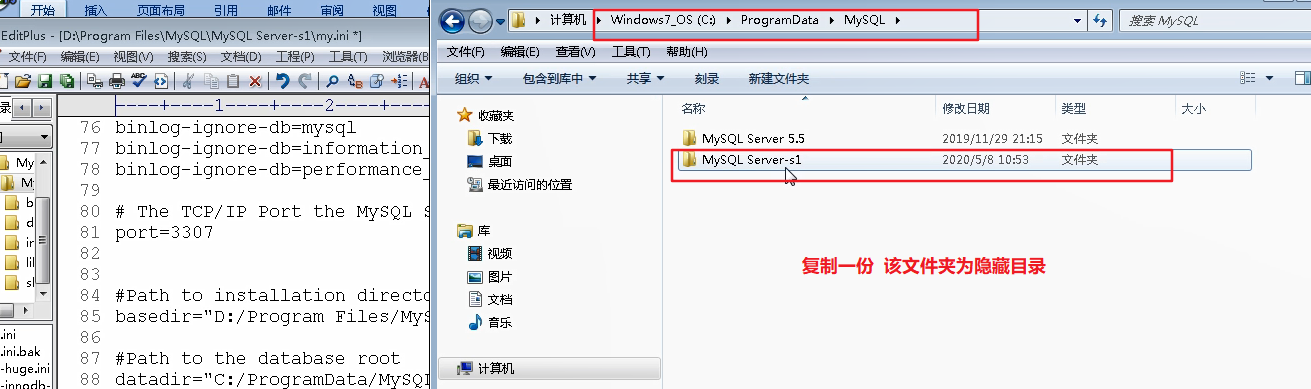
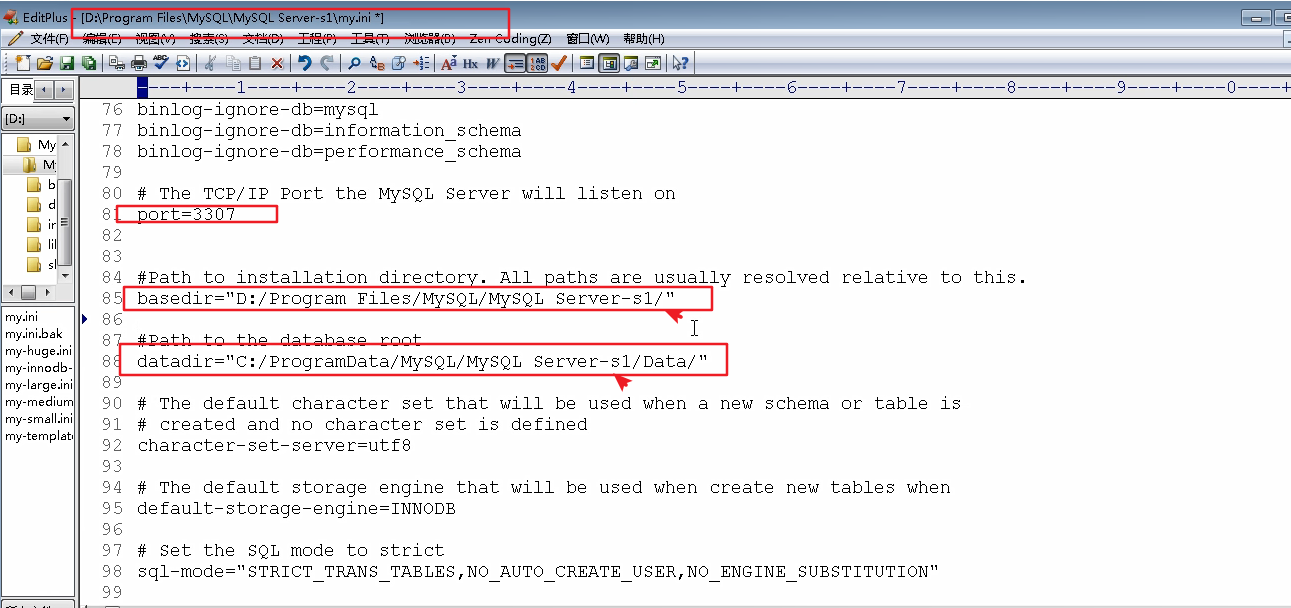
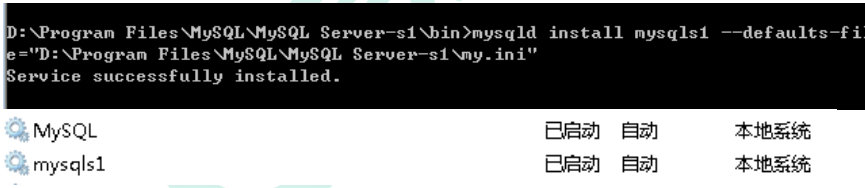
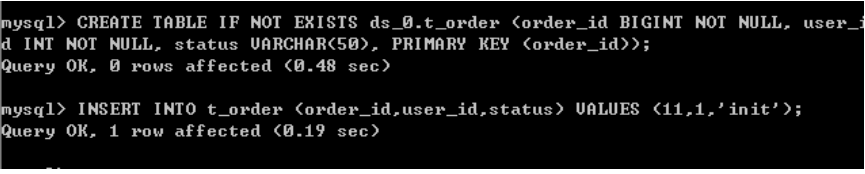
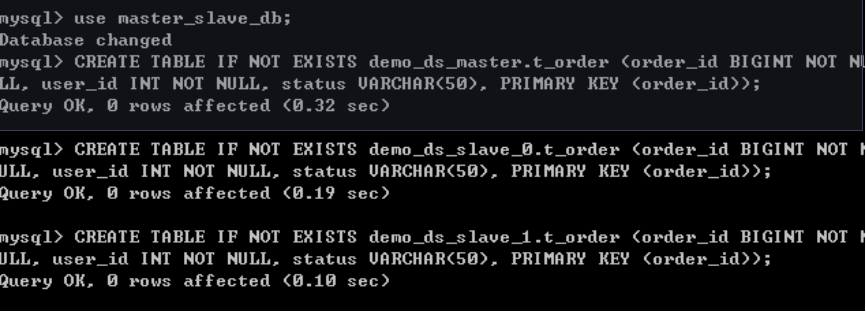
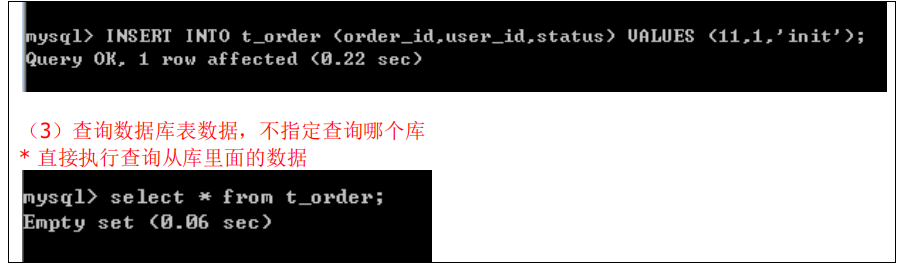
因为从库是从主库复制过来的,因此里面的数据完全一致,可使用原来的账号、密码登录
#开启日志
log‐bin = mysql‐bin
#设置服务id,主从不能一致
server‐id = 1
#设置需要同步的数据库
binlog‐do‐db=user_db
#屏蔽系统库同步
binlog‐ignore‐db=mysql
binlog‐ignore‐db=information_schema
binlog‐ignore‐db=performance_schema
[mysqld]
#开启日志
log‐bin = mysql‐bin
#设置服务id,主从不能一致
server‐id = 2
#设置需要同步的数据库
replicate_wild_do_table=user_db.%
#屏蔽系统库同步
replicate_wild_ignore_table=mysql.%
replicate_wild_ignore_table=information_schema.%
replicate_wild_ignore_table=performance_schema.%
#切换至主库bin目录,登录主库
mysql ‐h localhost ‐uroot ‐p
#授权主备复制专用账号
GRANT REPLICATION SLAVE ON *.* TO 'db_sync'@'%' IDENTIFIED BY 'db_sync'; #刷新权限
FLUSH PRIVILEGES;

#确认位点 记录下文件名以及位点
show master status;

#切换至从库bin目录,登录从库
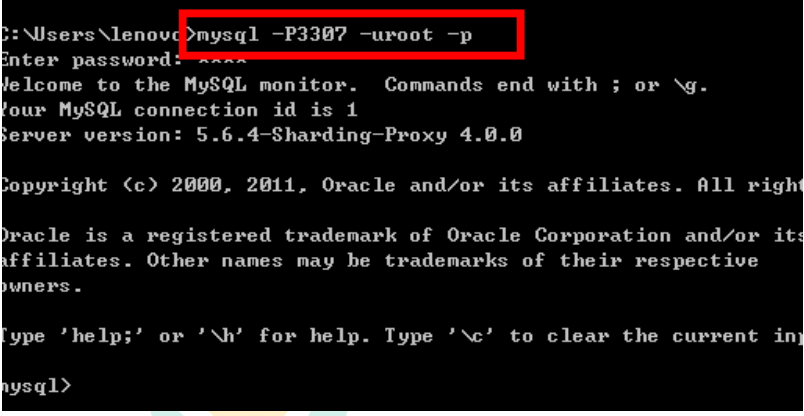
mysql ‐h localhost ‐P3307 ‐uroot ‐p
#先停止同步
STOP SLAVE;
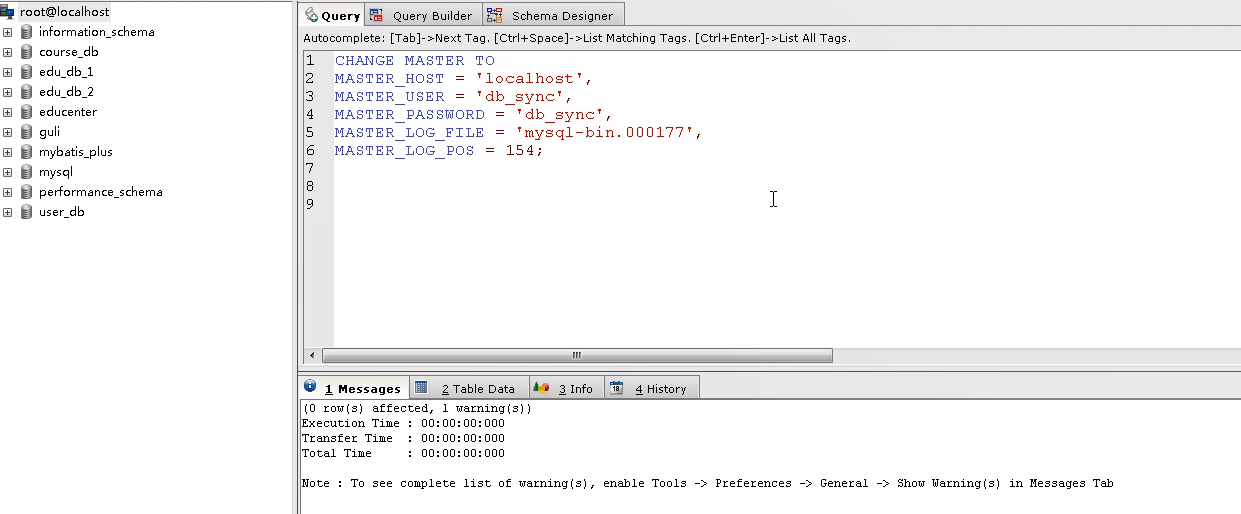
#修改从库指向到主库,使用上一步记录的文件名以及位点
CHANGE MASTER TO
master_host = 'localhost',
master_user = 'db_sync',
master_password = 'db_sync',
master_log_file = 'mysql-bin.000177',
master_log_pos = 107;
#启动同步
START SLAVE;
#查看Slave_IO_Runing和Slave_SQL_Runing字段值都为Yes,表示同步配置成功。如果不为Yes,请排
查相关异常。
show slave status


# user_db 从服务器
spring.shardingsphere.datasource.s0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.s0.url=jdbc:mysql://localhost:3307/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.s0.username=root
spring.shardingsphere.datasource.s0.password=root
# 主库从库逻辑数据源定义 ds0 为 user_db
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-sourcename=m0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-sourcenames=s0
# 配置 user_db 数据库里面 t_user 专库专表
#spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user
# t_user 分表策略,固定分配至 ds0 的 t_user 真实表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
//添加操作
@Test
public void addUserDb() {
User user = new User();
user.setUsername("lucymary");
user.setUstatus("a");
userMapper.insert(user);
}
//查询操作
@Test
public void findUserDb() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
//设置 userid 值
wrapper.eq("user_id",465508031619137537L);
User user = userMapper.selectOne(wrapper);
System.out.println(user);
}
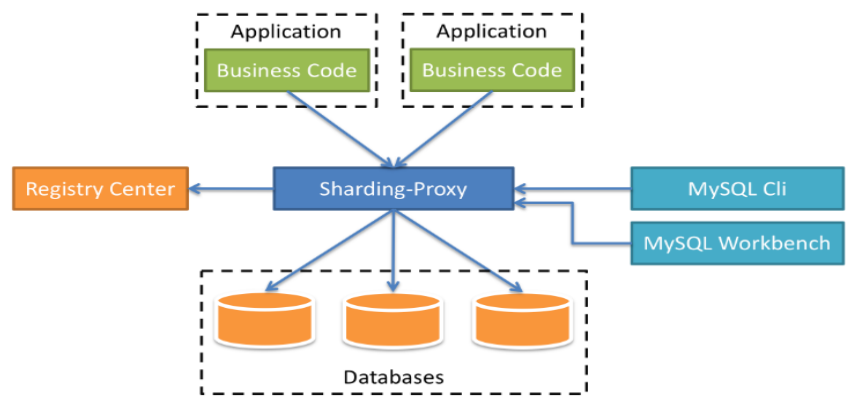



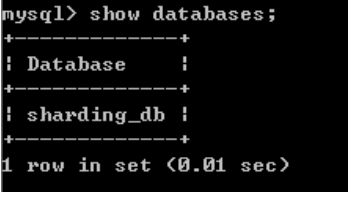
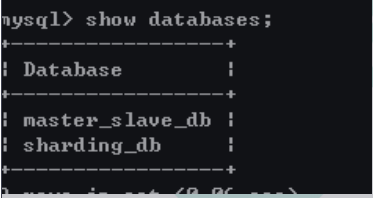
schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/edu_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
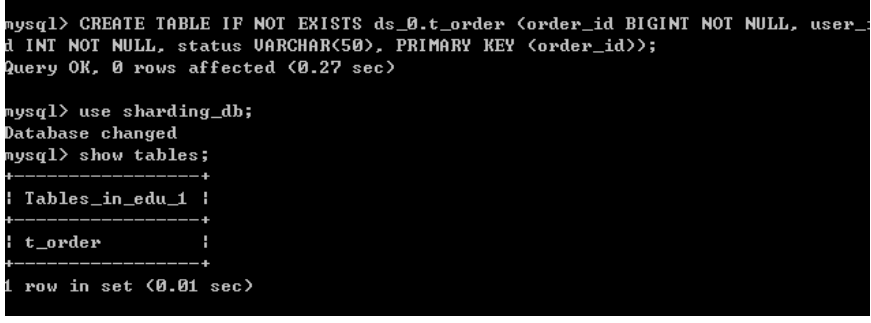
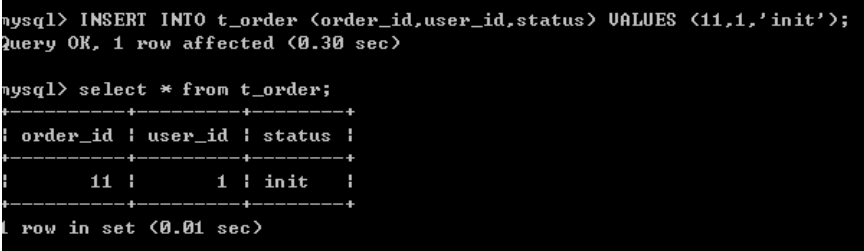
t_order:
actualDataNodes: ds_${0}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
bindingTables:
- t_order
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${0}
defaultTableStrategy:
none:


schemaName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/edu_db_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
ds_1:
url: jdbc:mysql://127.0.0.1:3306/edu_db_2?serverTimezone=UTC&useSSL=false
username: root



schemaName: master_slave_db
dataSources:
master_ds:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_master?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_0:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_slave_0?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
slave_ds_1:
url: jdbc:mysql://127.0.0.1:3306/demo_ds_slave_1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_ds
slaveDataSourceNames:
- slave_ds_0
- slave_ds_1

Sharding Sphere的分库分表的更多相关文章
- 分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html 为什么分库分表后不建议跨分片查询:https://www.jian ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- java 取模运算% 实则取余 简述 例子 应用在数据库分库分表
java 取模运算% 实则取余 简述 例子 应用在数据库分库分表 取模运算 求模运算与求余运算不同.“模”是“Mod”的音译,模运算多应用于程序编写中. Mod的含义为求余.模运算在数论和程序设计中 ...
- 分库分表技术演进&最佳实践
每个优秀的程序员和架构师都应该掌握分库分表,这是我的观点. 移动互联网时代,海量的用户每天产生海量的数量,比如: 用户表 订单表 交易流水表 以支付宝用户为例,8亿:微信用户更是10亿.订单表更夸张, ...
- 分库分表利器之Sharding Sphere(深度好文,看过的人都说好)
Sharding-Sphere Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 S ...
- 数据库分库分表(sharding)系列(一) 拆分规则
第一部分:实施策略 数据库分库分表(sharding)实施策略图解 1. 垂直切分垂直切分的依据原则是:将业务紧密,表间关联密切的表划分在一起,例如同一模块的表.结合已经准备好的数据库ER图或领域模型 ...
- 转数据库分库分表(sharding)系列(二) 全局主键生成策略
本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请参考该系列的前一篇文章:数据库分库分表( ...
- 转数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- 数据库分库分表(sharding)系列【转】
原文地址:http://www.uml.org.cn/sjjm/201211212.asp数据库分库分表(sharding)系列 目录; (一) 拆分实施策略和示例演示 (二) 全局主键生成策略 (三 ...
随机推荐
- Table.LastN保留后面N….Last…(Power Query 之 M 语言)
数据源: "姓名""基数""个人比例""个人缴纳""公司比例""公司缴纳"&qu ...
- 【译】使用 Visual Studio 调试外部源代码
您是否曾经需要调试并进入依赖于 NuGet 或 .NET 库的代码,而这些库并没有构建为您的解决方案的一部分? 现在,调试它们并不像调试作为解决方案一部分的项目那么容易.从 Visual Studio ...
- 尚硅谷SSM-CRUD实战Demo
SSM-CRUD实战项目 1. 项目总览 SpringMVC + Spring + MyBatis CRUD:增删改查 功能: 分页 数据校验 jquery前端校验+JSR303后端校验 ajax R ...
- centos使用docker安装tomcat8
下载镜像 docker pull tomcat:8 启动 docker run -d -p 8080:8080 -v /data/tomcat/webapps/:/usr/local/tomcat/w ...
- mysql报错:You do not have the SUPER privilege and binary logging is enabled
MySQL出现 You do not have the SUPER privilege and binary logging is enabled报错 解决方案: 1.用root用户登录:mysql ...
- C/C++ byte 转 int 有符号数,转成Int 无符号数
p.p1 { margin: 0; font: 12px "Helvetica Neue"; color: rgba(69, 69, 69, 1); min-height: 14p ...
- 【linux项目】lichee nano linux烧写
目录 前言 参考: 安装交叉编译链 搭建 SPI FLASH 烧录环境 让芯片进入烧写模式 sunxi 烧写命令 u-boot 裁剪 拉取 u-boot 源码 配置 u-boot 检查 flash 驱 ...
- 【LeetCode】521. Longest Uncommon Subsequence I 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】835. Image Overlap 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】77. Combinations 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 方法一:递归 方法二:回溯法 日期 题目地址:htt ...