Learning to Sample
此处主要提出几个疑问和想法:
疑问:
- 为什么需要这个匹配过程?虽然G可能不是P的子集,但是为什么一定需要他是子集呢?
- 如果一定要匹配的话,匹配过程是没法反向传播的,所以只可以在推理阶段使用,那么这个推理阶段起到了什么作用呢?训练一个针对
fixed task的S-NET么? 那么在推理阶段这个匹配就可以反向传播从而更新S-NET了么?和训练阶段有什么区别? - 但是看分类任务的数据的话,这个
S-NET确实提取出了更重要的点, - 他的采样到底有没有收到下游任务的影响,从而进行针对性的采样?如果有的话那个采样的不可微不是已经断了么?\(\color{red}{这里有解决方法。}\)链接为:https://www.cnblogs.com/A-FM/p/15694906.html
- 在几何结构信息复杂的地方多采样一些点,几何信息简单的地方可以少放一点点,并且把
point relation加进去然后做采样,再想想办法把半监督啥的放进去?因为只要这样做了采样,点很少的情况下,效果也会很不错的,这样可以借助这个优势去扩大半监督的优势?
Abstract
处理大型的点云是一项很有挑战性的任务,因此,我们将点云采样到一个合适的size去更方便的处理。
- 目前流行的采样方法是FPS,但是FPS对于下游任务是不可知的,如在反向传播啥的,他们之间是没有交互的。
- 我们证明了通过dl去学习如何采样是更好的,因此提出了一个深度网络来简化三维点云。其被称为
S-NET。 - 该方法可以解决第一点,也就是针对特定任务进行优化。
Introduction
- FPS等这些方法考虑了点云的结构,选取一组彼此相距最远的点。
- 这些采样方法和文献中其他方法一样,都是根据非学习的预定规则进行操作的。
S-NET学习生成更小的点云,该点云采样可以为下游任务进行针对性优化。
简化之后的点云必须平衡两个相互冲突的方面:
- 希望它保持和原始形状的相似性,
- 希望他可以优化到后续任务。
我们通过训练网络生成一组满足两个目标的点来解决这个问题:采样损失和任务损失。 - 采样损失驱动生成的点的形状接近输入点云。
- 任务损失确保点对任务有优化。
FPS的一个优点是他采样得到的集合是原始点的子集,但是S-NET生成的简化点云并不能保证是输入点云的子集。
- 这个方法可以被视为是一种特征选择机制,每个点都是基础形状的一个特征,此处试图找出对任务贡献最大的点。
- 它也可以被解释为是视觉注意力的一种形式,将后续的任务网络集中在重要的点上。
贡献:
- 针对特定任务数据驱动采样方法
- 一种递进的抽样方法,根据点与任务的相关性进行排序
相关工作
点云的采样和简化
相关的方法,都是在优化各种抽样目标,然而他们没有考虑到所执行的任务的目标。
Method
问题描述:给定一个点集\(P=\{p_i\in\mathbb{R}^3,i=1,\dots,n\}\),采样大小为\(k\leq n\)和一个任务网络\(T\),找出\(k\)个点的子集\(S^*\),使任务网络的目标函数\(f\)最小化。
\]
\(\color{red}{这个问题带来了一个挑战就是采样看起来类似于池化,但是采样是无法反向传播的,但是池化可以,因此可以计算池化的梯度。}\)
然而离散采样就像arg-pooling,传播的值不能增量的更新。因此抽样操作不可以直接进行训练。因此,我们将生成的点和原始点云进行匹配,得到输入点的子集,即采样点。如下图
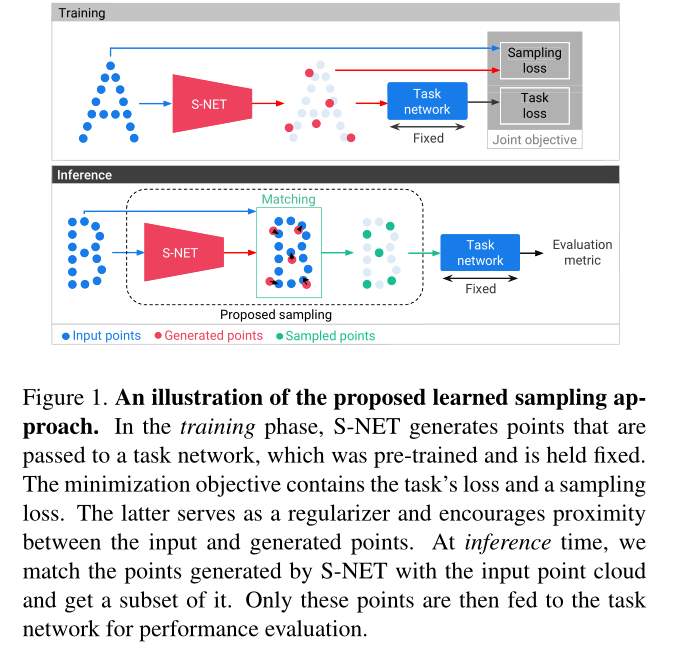
S-NET的输入是\(n\)个三维坐标的集合,代表一个三维形状。S-NET的输出是\(k\)个生成的点。S-NET后面是一个任务网络。输入\(n\)个点对任务网络进行预训练,在点云上执行给定的任务。S-NET在训练和测试的过程中保持固定,这确保了采样是针对任务进行优化的,而不是针对任意抽样进行优化的任务。
在训练阶段,生成的点被送到任务网络当中,这些点通过最小化任务损失来优化手头的任务。并且使用第二个损失项,鼓励生成的每个点靠近输入点的位置,并迫使生成的点在输入点云的分布中扩散。
在推理阶段的时候,将生成的点和输入点云进行匹配以获得其子集。这些采样点就是我们的最终输出采样点,这些点通过网络并对其性能进行评估。
此处提供了两个采样版本:S-NET和ProgressiveNet。在第一个版本中,我们根据样本大小训练不同的采样网络。在第二个版本中,它可以产生任何大小的 小于输入样本的采样样本。
S-NET
S-NET的结构使用的是PointNet的方法。输入点经过一组\(1\times 1\)的卷积层,得到每个点的特征向量。然后使用对称的特征最大池来获得全局特征向量。最后,我们使用几个完全连接的层,最后一层的输出是生成的点集。
我们将生成的点集表示为\(G\),输入的点集表示为\(P\),我们构造一个采样正则化损失,它由三个项组成:
\]
\]
\]
\(L_f\)和\(L_m\)在平均和最差的情况下,让\(G\)尽量可能的接近\(P\)。\(L_b\)保证生成的点尽量均匀的分布在输入点上。我们可以将上述公式转化为:
\]
此外我们使用\(L_{task}\)表示任务网络损失,最终S-NET的损失函数为:
\]
S-NET的输出是\(k \times 3\)的矩阵,\(k\)是采样样本的点数,接下来我们就对这\(k\)个点进行训练。
Matching
生成的点G不能保证是输入点\(P\)的子集,为了得到输入点的子集,我们将生成的点匹配到输入点云。
一个广泛使用的匹配两个点集的方法是EMD,它可以在集合之间找到一个bijection,使对应的点的距离最小,但是它要求这两个点集有相同的数量。但是在这里我们的两个点集的大小是不同的。
我们测试两种匹配方法。第一种方法是将EMD适用于不均匀点集。第二种是基于最近邻匹配的问题。这里我们使用的是第二种,它可以产生更好的效果。在基于最近邻的匹配中,每个点\(x\in G\)被替代为欧几里得空间内最近的点\(y^*\in P\):
\]
由于\(G\)中的几个点可能会接近于\(P\)中的同一个点,所以采样点的数量可能会小于需要点的数量。因此我们去掉重复的点并且得到一个初始的采样集合。然后我们通过FPS完成这个集合,我们每一步都从P中添加一个距离当前点集最远的点
匹配过程我们仅仅在推理时使用,作为推理的最后一步。在训练阶段当中,生成的点由任务网络按照原样处理,因为匹配是不可微的,不能将任务损失传播回S-NET
ProgressiveNet: sampling as ordering
S-NET被训练来采样单一,预训练过的尺寸大小的点。但是如果我们需要很多个采样大小呢?那么就需要对应数量的S-NET被训练。如果我们想训练一个可以产出任意大小的采样算法要怎么做的,然后这里提出了ProgressiveNet。ProgressiveNet的训练输入是给定大小的点云,输出是同样大小的点云,虽然输入点的顺序是任意的,但是输出点的顺序是根据他们与任务的相关性排序的。这样就允许我们对任意大小的样本进行抽样,我们只需要获取ProgressiveNet输出的前\(k\)个点云,然后丢弃其他样本。ProgressiveNet的结构和S-NET的相同,最后一个全连接层的大小等于输入点云的大小。
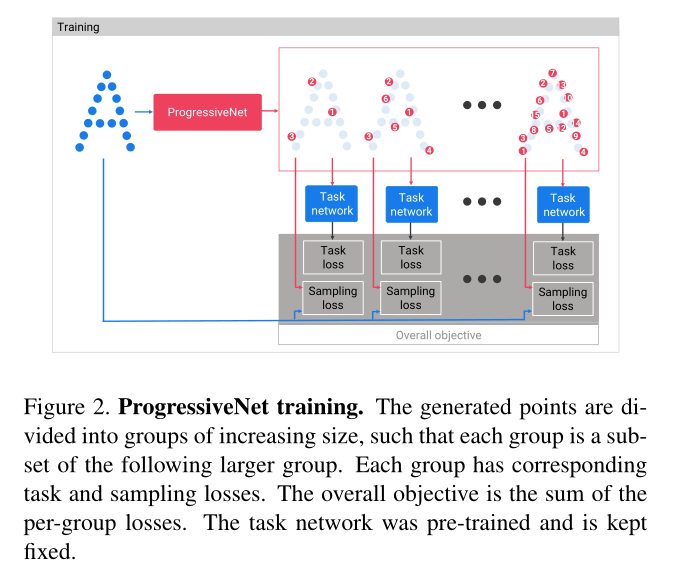
为了训练ProgressiveNet我们定义一个集合\(C_s=\{2^1,2^2,\dots,2^{log_2(n)}\}\)。对于每一个大小\(c\in C_s\)我们计算任务损失项和一个采样正则化损失项,使ProgressiveNet的总损失变为:
\]
其中的\(L^{S-NET}\)是方程6定义的公式,\(G_c\)是ProgressiveNet生成的点的前\(c\)个点
不继续看了, 这个没啥东西。 就是为了可变采样大小,通过给采样点排序的方法。
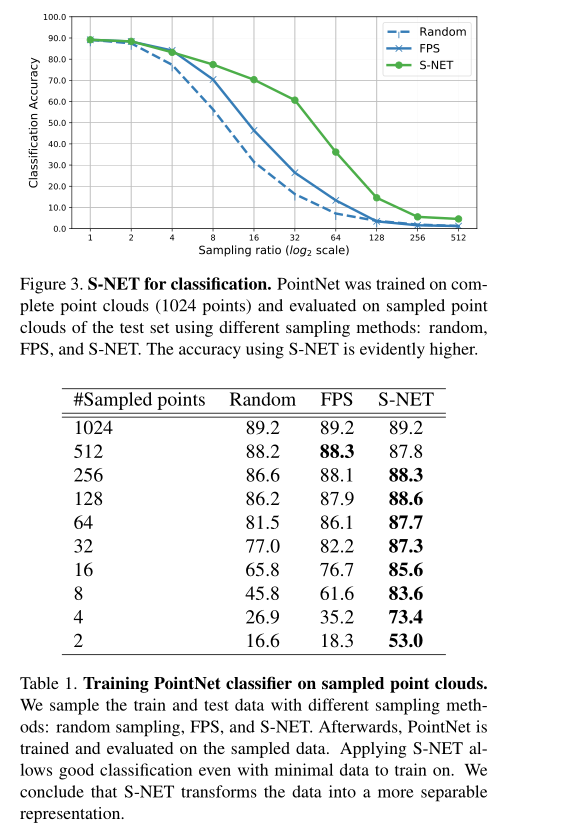
实验
Learning to Sample的更多相关文章
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- 小样本学习最新综述 A Survey on Few-shot Learning | Introduction and Overview
目录 01 Introduction Bridging this gap between AI and humans is an important direction. FSL can also h ...
- (转)Let’s make a DQN 系列
Let's make a DQN 系列 Let's make a DQN: Theory September 27, 2016DQN This article is part of series Le ...
- 线性、逻辑回归的java实现
线性回归和逻辑回归的实现大体一致,将其抽象出一个抽象类Regression,包含整体流程,其中有三个抽象函数,将在线性回归和逻辑回归中重写. 将样本设为Sample类,其中采用数组作为特征的存储形式. ...
- scikit-learn:3.3. Model evaluation: quantifying the quality of predictions
參考:http://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter 三种方法评估模型的预測质量: Est ...
- 一、【python】机器学习基础
专有名词 机器学习 (machine learning) 预测分析 (predictive analytics) 统计学习 (statistical learning) 监督学习 (supervise ...
- SampleNet: Differentiable Point Cloud Sampling
Abstract 经典的采样方法(FPS)之类的没有考虑到下游任务. 改组上一篇工作没有解决不可微性,而是提供了变通的方法. 本文提出了解决不可微性的方法 可微松弛点云采样,近似采样点作为一个混合点在 ...
- 【PSMA】Progressive Sample Mining and Representation Learning for One-Shot Re-ID
目录 主要挑战 主要的贡献和创新点 提出的方法 总体框架与算法 Vanilla pseudo label sampling (PLS) PLS with adversarial learning Tr ...
- Deep learning:五十一(CNN的反向求导及练习)
前言: CNN作为DL中最成功的模型之一,有必要对其更进一步研究它.虽然在前面的博文Stacked CNN简单介绍中有大概介绍过CNN的使用,不过那是有个前提的:CNN中的参数必须已提前学习好.而本文 ...
随机推荐
- CF1290E Cartesian Tree
考虑笛卡尔树的意义: 一个点在笛卡尔树中的子树,代表以他为最小/最大值的区间. 所以一个点的子树大小,一定是类似到达序列边界或者被一个比他更大的数隔离. 考虑记录 \(l_i,r_i\) 为第 \(i ...
- CF1493E Enormous XOR
题目传送门. 题意简述:给出长度为 \(n\) 的二进制数 \(l,r\),求 \(\max_{l\leq x\leq y\leq r}\oplus_{i=x}^yi\). 非常搞笑的题目,感觉难度远 ...
- 【软连接已存在,如何覆盖】ln: failed to create symbolic link ‘file.txt’: File exists
ln -s 改成 ln -sf f在很多软件的参数中意味着force ln -sf /usr/bin/bazel-1.0.0 /usr/bin/bazel
- 详细解析Thinkphp5.1源码执行入口文件index.php运行过程
详细解析Thinkphp5.1源码执行入口文件index.php运行过程 运行了public目录下的index.php文件后,tp的运行整个运行过程的解析 入口文件index.php代码如下: < ...
- snakmake 小练习
最近在学习snakemake 用于生信流程管理,现在用一个snakemake 来完成小任务:将在某一文件夹下的多个bam文件截取一部分,然后建立索引,在提取出fastq序列,最后比对回基因组. 需要两 ...
- Can't connect to HTTPS URL because the SSL module is not available. - skipping
今天用pip3安装第三方库的时候报了这样一个错: Can't connect to HTTPS URL because the SSL module is not available. - skipp ...
- Spark(八)【利用广播小表实现join避免Shuffle】
目录 使用场景 核心思路 代码演示 正常join 正常left join 广播:join 广播:left join 不适用场景 使用场景 大表join小表 只能广播小表 普通的join是会走shuff ...
- Vue中加载百度地图
借助百度地图的 LocalSearch 和 Autocomplete 两个方法 实现方式:通过promise以及百度地图的callback回调函数 map.js 1 export function M ...
- 【2021赣网杯web(一)】gwb-web-easypop
源码分析 <?php error_reporting(0); highlight_file(__FILE__); $pwd=getcwd(); class func { public $mod1 ...
- 【leetcode】834. Sum of Distances in Tree(图算法)
There is an undirected connected tree with n nodes labeled from 0 to n - 1 and n - 1 edges. You are ...