分布式ID生成方案
系统唯一ID是设计一个系统的时候常常会遇到的问题,也常常为这个问题而纠结。
生成ID的方法有很多,适应不同的场景、需求以及性能要求。所以有些比较复杂的系统会有多个ID生成的策略。
0. 分布式ID要求
(1)全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求;
(2)粗略有序:如果在分布式环境中做到完全有序,需要用到锁等,考虑到性能,采用粗略有序,具体分为秒级有序和毫秒级有序;
(3)可反解:即生成ID服务提供反解方法,这样在存储时就能以十进制存储,省下传统timestamp类字段的占用空间了;
(4)可伸缩:中心发布模式时可以进行集群部署,这样在生成ID里就必须包含机器ID;
(5)趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-Tree的数据结构来存储索引数据,在主键的选择上我们应该尽量使用有序的主键保证写入性能;
(6)单调递增:保证下一个ID一定大于上一个ID,例如事务版本号,IM增量信息,排序特殊需求;
(7)信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易,直接按照顺序下载指定URL即可,如果是订单号就更危险了
1. 数据库自增长列或字段
针对主库单点,如果有个多个master库,则每个master库设置的起始数字不一样,步长一样(可以使master的个数)。比如:master1生成的是1,4,7,10,master2生成的是2,5,8,11,master3生成的是3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
优点:
(1)最常见的方式,利用数据库,全数据库唯一,简单,代码方便,性能可以接受
(2)数字ID天然排序,对分页或需要排序的结果很有帮助
缺点:
(1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理
(2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成,有单点故障的风险
(3)在性能达不到要求的情况下,比较难于扩展
(4)如果遇到多个系统需要合并或者涉及到数据迁移会相当痛苦
(5)分表分库的时候有麻烦
2. UUID
优点:
(1)常见的方式,可以利用数据库也可以利用程序生成,一般来说全球唯一,简单,代码方便
(2)生成ID性能非常好,基本不会有性能问题
(3)全球唯一,在遇见数据迁移,系统数据合并或数据库变更等情况下,可以从容应对
缺点:
(1)没有排序,无法保证趋势递增
(2)UUID往往是使用字符串存储,查询的效率比较低
(3)存储空间比较大,如果是海量数据库,就需要存储量的问题
(4)传输数据量大
(5)不可读
3. Redis生成ID
当使用数据库来生成ID性能不够要求的时候,可以尝试用Redis来生成ID。
4. Twitter的snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:
使用41bit作为毫秒数
10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID)
12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID)
最后还有一个符号位,永远是0。
https://github.com/twitter/snowflake
优点:
(1)不依赖数据库,灵活方便,且性能优于数据库
(2)ID按照时间在单机上是递增的
缺点:
(1)在单机上是递增的,但是由于涉及到分布式环境中,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
5. 利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID,主要是由于依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境中,也不甚理想。
6. MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法类似。它涉及成轻量级,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求,使其在分布式环境中要容易生成得多。
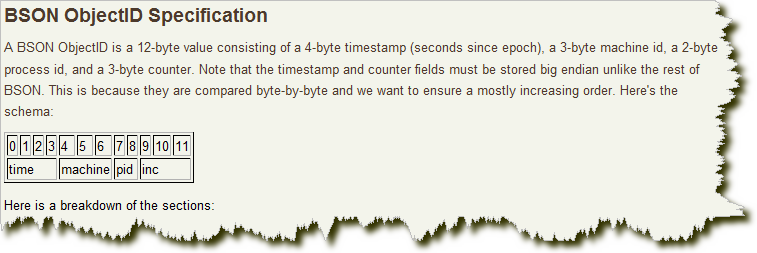
前4个字节是从标准纪元开始的时间戳,单位是秒。时间戳和随后的5个字节组合起来,提供了秒级别的唯一性。由于时间戳在前,意味着ObjectId大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率。这4个字节也隐含了文档创建时间。绝大多数客户端类库都会公开一个方法从ObjectId获取这个信息。
接下来3字节是所在主机的唯一标识符。通常是主机名的散列值,这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
接下来2个字节来自产生ObjectId的进程标识符(PID),为了确保在同一台机器上并发的多个进程产生的ObjectId是唯一的。
前9字节保证了同一秒中不同机器不同进程产生的ObjectId是唯一的,后3字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId也是不一样的。同一秒钟最多允许每个进程拥有16777216个不同的ObjectId。
7. 单点批量ID生成服务
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”,要想保证绝对的时序,还是只能使用单点服务,用本地时钟保证“绝对时序”。数据库写压力大,是因为每次生成ID都访问了数据库,可以使用批量的方式降低数据库写压力。
数据库中只存储当前ID的最大值,例如0。ID生成服务假设每次批量拉取6个ID,服务访问数据库,将当前ID的最大值修改为5,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4,5这些ID了,当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6了。
优点:
(1)保证了ID生成的绝对递增有序
(2)大大的降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
(1)服务仍然是单点
(2)如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,5,数据库中max-id是5,分配到3时,服务重启了,下次会从6开始分配,4和5就成了空洞,不过这个问题也不大)
(3)虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
改进方法:
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”,所以我们能用以下方法优化上述缺点(1)。对外提供的服务是主服务,有一个影子服务时刻处于备用状态,当主服务挂了的时候影子服务顶上。这个切换的过程对调用方是透明的,可以自动完成,常用的技术是vip+keepalived,具体就不在这里展开。
参考资料:
https://www.cnblogs.com/haoxinyue/p/5208136.html
https://tech.meituan.com/MT_Leaf.html
分布式ID生成方案的更多相关文章
- 一种基于Orleans的分布式Id生成方案
基于Orleans的分布式Id生成方案,因Orleans的单实例.单线程模型,让这种实现变的简单,贴出一种实现,欢迎大家提出意见 public interface ISequenceNoGenerat ...
- 搞懂分布式技术12:分布式ID生成方案
搞懂分布式技术12:分布式ID生成方案 ## 转自: 58沈剑 架构师之路 2017-06-25 一.需求缘起 几乎所有的业务系统,都有生成一个唯一记录标识的需求,例如: 消息标识:message-i ...
- 分布式id生成方案总结
本文已经收录自 JavaGuide (60k+ Star[Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.) 本文授权转载自:https://juejin.im/post/ ...
- 分布式ID生成方案总结整理
目录 1.为什么需要分布式ID? 2.业务系统对分布式ID有什么要求? 3.分布式ID生成方案 3.1 UUID 3.2.数据库自增 3.3.号段模式 3.4. Redis实现 3.4. 雪花算法(S ...
- 分布式ID生成方案汇总
1.目标 1.1.全局唯一 不能出现重复的ID,全局唯一是最基本的要求. 1.2.趋势有序 业务上分页查询需求,排序需求,如果ID直接有序,则不必建立更多的索引,增加查询条件. 而且Mysql Inn ...
- 分布式ID详解(5种分布式ID生成方案)
分布式架构会涉及到分布式全局唯一ID的生成,今天我就来详解分布式全局唯一ID,以及分布式全局唯一ID的实现方案@mikechen 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消 ...
- 分布式唯一ID生成方案是什么样的?(转)
一.前言 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题, ...
- 一线大厂的分布式唯一ID生成方案是什么样的?
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取.传送门:h ...
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
随机推荐
- React的第一个例子
准备: 官网:https://facebook.github.io/react/downloads.html Github地址:https://github.com/facebook/react 首先 ...
- ASP.NET MVC:看 MVC 源码,学习:如何将 Area 中的 Controller 放到独立的程序集?
背景 本文假设您已经熟悉了 ASP.NET MVC 的常规开发方式.执行模型和关键扩展点,这里主要说一下如何使用 ASP.NET MVC 的源代码解决一些问题. 如何将 Area 中的 Control ...
- 页游安全攻与防,SWF加密和隐藏密匙
原文链接:http://netsecurity.51cto.com/art/201211/364775.htm 页游,最最核心的就是客户端(swf)与服务端的游戏通信了.游戏通信产生的封包,内容是否可 ...
- Log4j写入数据库详解
log4j是一个优秀的开源日志记录项目,我们不仅可以对输出的日志的格式自定义,还可以自己定义日志输出的目的地,比如:屏幕,文本文件,数据库,甚至能通过socket输出.本节主要讲述如何将日志信息输入到 ...
- 非归档数据文件offline的恢复
本文主要介绍非归档模式下offline数据文件的恢复,测试过程如下: SQL> select * from v$version where rownum<3; BANNER ------- ...
- Json转java对象和List集合
public static void main(String[] args) { // 转换对象 String strJson ="{\"basemenu_id\":\& ...
- vue项目中使用mockjs模拟接口返回数据
Mock.js 是一个模拟数据生成器,利用它,可以拦截ajax请求,直接模拟返回数据,这样前后端只要约定好数据格式,前端就不需要依赖后端的接口,可以直接使用模拟的数据了. 网上介绍mock的教程也较多 ...
- T_SQL的 FOR XML PATH 用法
T_SQL的 FOR XML PATH FOR XML PATH 有的人可能知道有的人可能不知道,其实它就是将查询结果集以XML形式展现,有了它我们可以简化我们的查询语句实现一些以前可能需要借助函数活 ...
- 【转发】Visual Studio 2013 如何关闭调试而不关闭IIS Express
在VS主面板打开:工具->选项->调试->编辑继续 取消选中[启用"编辑并继续"] 就OK了 (英文版的请对应相应的操作) 不过这是针对所有的调试,如果你想针 ...
- unix 网络编程第八章 UDP
code 见 https://github.com/juniperdiego/Unix-network-programming-of-mine/tree/master/udpserv01 1 建立so ...