分布式ID详解(5种分布式ID生成方案)

分布式架构会涉及到分布式全局唯一ID的生成,今天我就来详解分布式全局唯一ID,以及分布式全局唯一ID的实现方案@mikechen
什么是分布式系统唯一ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
分布式系统唯一ID的特点
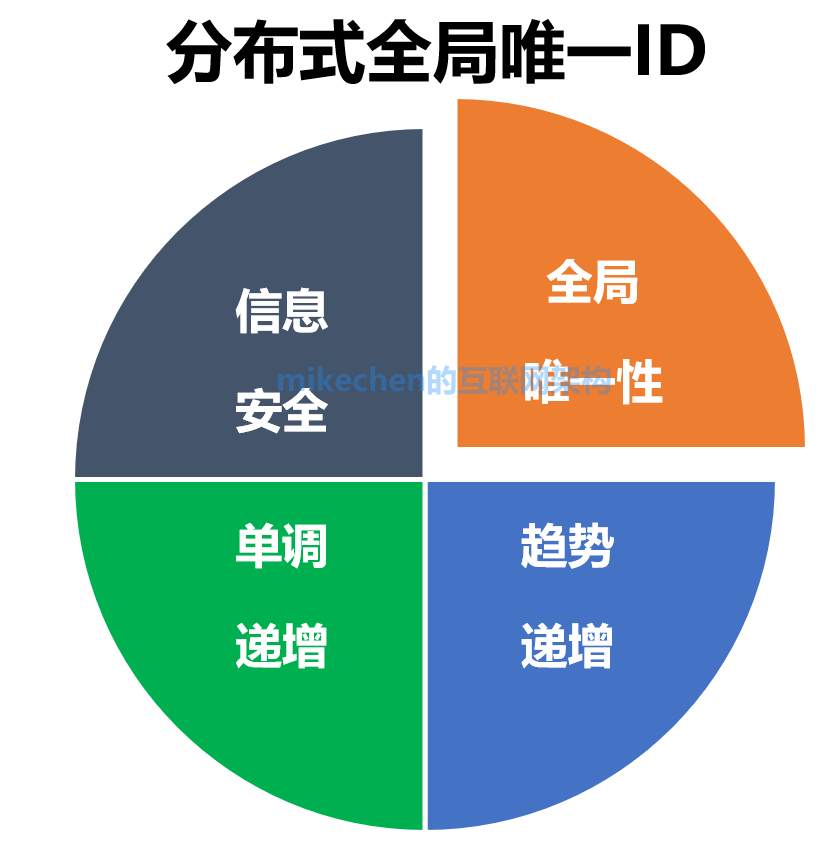
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
由此总结下一个ID生成系统应该做到如下几点:
- 平均延迟和TP999延迟都要尽可能低;
- 可用性5个9;
- 高QPS
分布式系统唯一ID的实现方案
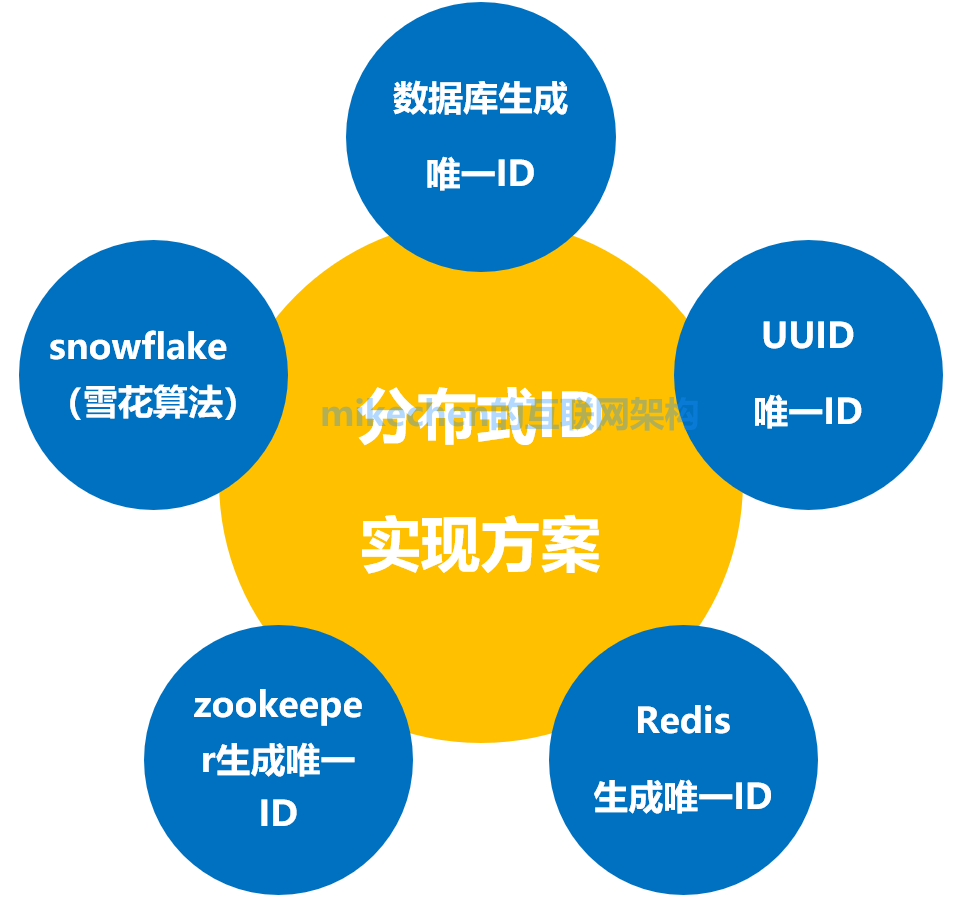
1.UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
UUID优点:
- 性能非常高:本地生成,没有网络消耗。
UUID缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用;
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置;
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用。
2.数据库生成ID
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
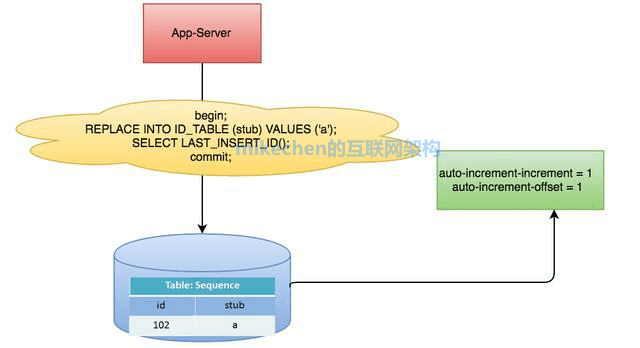
数据库生成ID优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
数据库生成ID缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
3.Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。
这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
Redis生成ID优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
Redis生成ID缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
4.利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
5.snowflake雪花算法生成ID
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:

41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
雪花算法ID优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
雪花算法ID缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
以上
作者简介
陈睿|mikechen,10年+大厂架构经验,《BAT架构技术500期》系列文章作者,专注于互联网架构技术。
阅读mikechen的互联网架构更多技术文章合集
Java并发|JVM|MySQL|Spring|Redis|分布式|高并发
分布式ID详解(5种分布式ID生成方案)的更多相关文章
- Zookeeper系列二:分布式架构详解、分布式技术详解、分布式事务
一.分布式架构详解 1.分布式发展历程 1.1 单点集中式 特点:App.DB.FileServer都部署在一台机器上.并且访问请求量较少 1.2 应用服务和数据服务拆分 特点:App.DB.Fi ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- hadoop 0.20.2伪分布式安装详解
adoop 0.20.2伪分布式安装详解 hadoop有三种运行模式: 伪分布式不需要安装虚拟机,在同一台机器上同时启动5个进程,模拟分布式. 完全分布式至少有3个节点,其中一个做master,运行名 ...
- 转:Windows下的PHP开发环境搭建——PHP线程安全与非线程安全、Apache版本选择,及详解五种运行模式。
原文来自于:http://www.ituring.com.cn/article/128439 Windows下的PHP开发环境搭建——PHP线程安全与非线程安全.Apache版本选择,及详解五种运行模 ...
- Java 枚举(enum) 详解7种常见的用法
Java 枚举(enum) 详解7种常见的用法 来源 https://blog.csdn.net/qq_27093465/article/details/52180865 JDK1.5引入了新的类型— ...
- 图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
参考网址:图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS) - 51CTO.COM 深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath ...
- 详解k8s一个完整的监控方案(Heapster+Grafana+InfluxDB) - kubernetes
1.浅析整个监控流程 heapster以k8s内置的cAdvisor作为数据源收集集群信息,并汇总出有价值的性能数据(Metrics):cpu.内存.网络流量等,然后将这些数据输出到外部存储,如Inf ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- 分布式大牛详解Zookeeper底层原理
很多学员都在反馈,说zk很难学,学的不是很明白,在这里,我继续带着大家详解一遍Zookeeper 首先zk是什么呢首先肯定是一个个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用 ...
随机推荐
- docker容器数据管理
Docker容器数据卷 Docker中的数据可以存储在类似于虚拟机磁盘的介质中,在Docker中称为数据卷(Data Volume). 数据卷可以用来存储Docker应用的数据,也可以用来在Docke ...
- 利用Kaptcha.jar生成图片验证码(以下源码可以直接复制并自定义修改)
说明:Kaptcha是一个很实用的验证码生成工具,它可以生成各种样式的验证码,因为它是可以配置的 目录: 一 实现步骤 二 实例 A 编写jsp页面 B 配置web.xml C 验证输入正确与否. 一 ...
- C++ 处理类型名(typedef,auto和decltype)
随着程序越来越复杂,程序中用到的类型也越来越复杂,这种复杂性体现在两个方面.一是一些类型难于"拼写",它们的名字既难记又容易写错,还无法明确体现其真实目的和含义.二是有时候根本搞不 ...
- python主动杀死线程
简介 在一些项目中,为了防止影响主进程都会在执行一些耗时动作时采取多线程的方式,但是在开启线程后往往我们会需要快速的停止某个线程的动作,因此就需要进行强杀线程,下面将介绍两种杀死线程的方式. 直接强杀 ...
- ApacheCon 首次亚洲大会 —— Incubator 专场介绍
Apache 孵化器即为想要进入 Apache 软件基金会(ASF)的项目提供相关帮助和服务.它帮助进入的项目(称为"podling")采用 Apache 的治理风格,并引导使用 ...
- Excelize 发布 2.6.1 版本,支持工作簿加密
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准.可以使用它来读取.写入由 Microsoft Exc ...
- jQuery使用case记录
添加元素/内容追加等 元素内: append() - 在被选元素的结尾插入内容 prepend() - 在被选元素的开头插入内容 元素外: after() - 在被选元素之后插入内容 before() ...
- PI控制器的由来
20世纪20年代初,一位名叫尼古拉斯·米诺斯基(Nicolas Minorsky)的俄裔美国工程师通过观察舵手在不同条件下如何驾驶船只,为美国海军设计了自动转向系统. 根据Wikipedia.org, ...
- js实现多条件排序
1.sort排序允许接受一个参数(函数),这个函数接受2个形参a,b,并且通过冒泡的方式比较.例子:Arr.sort((a,b) => a-b); 升序排列Arr.sort((a,b) =& ...
- vue中处理过内存泄露处理方法
1>意外的全局变量函数中意外的定义了全局变量,每次执行该函数都会生成该变量,且不会随着函数执行结束而释放. 2>未清除的定时器定时器没有清除,它内部引用的变量,不会被释放. 3>脱离 ...