实时计算Flink on Kubernetes产品模式介绍
Flink产品介绍
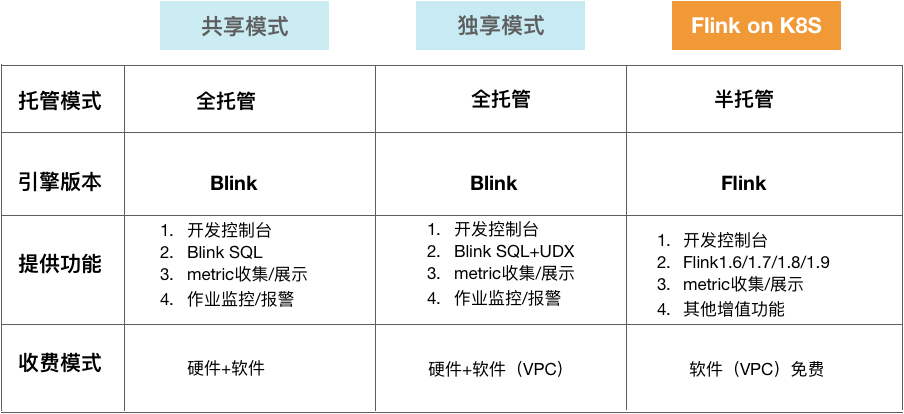
目前实时计算的产品已经有两种模式,即共享模式和独享模式。这两种模式都是全托管方式,这种托管方式下用户不需要关心整个集群的运维。其次,共享模式和独享模式使用的都是Blink引擎。这两种模式为用户提供的主要功能也类似,
- 都提供开发控制台;
- 开发使用的都是Blink SQL,其中独享模式由于进入了用户的VPC,部署在用户的ECS上,因此可以使用很多底层的API,如UDX;
- 都提供一套的开箱即用的metric收集、展示功能;
- 都提供作业监控和报警功能。
- 最后,在收费模式上,共享模式和独享模式用户所承担的都是硬件加软件(独享模式是软件(VPC))的费用。
Flink on Kubernetes模式介绍及对比
在共享和独享这两种模式的基础上,阿里云实时计算团队于2019年9月中旬会推出一个新的模式,Flink on K8S,其与前两种模式区别主要在于:
- 托管模式:集群以半托管模式部署在用户ECS和K8S上,用户对该集群用完全的掌控能力。
- 引擎版本:直接使用开源Flink版本
- 提供功能:提供开发控制台支持用户提交并控制作业;支持Flink 1.6/1.7/1.8等版本;也提供metric收集、展示、作业监控、报警功能;提供其他可插拔的增值功能。
- 收费模式:Flink on K8S模式下软件(VPC)是完全免费的,用户只需要支付ECS的费用就可以免费试用Flink产品。
各种模式对比如下:
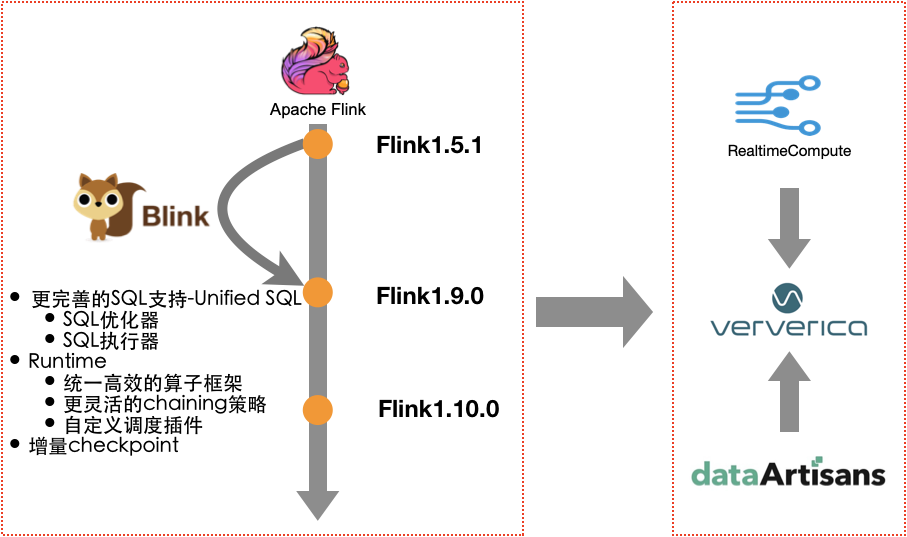
引擎方面,Blink是由阿里云实时计算团队于2016年从Flink 1.5.1拉出来的分支,在这之后的三年多的时间里,该分支被进行了一系列的改造:1)SQL优化器和执行器的改造,目前有更完善的SQL支持,提供了Unified SQL;2)在Runtime上,提供了统一高效的算子框架、更加灵活的chaining策略和自定义调度插件;3)提供增量Checkpoint。
2019年1月份,阿里巴巴决定将Blink的所有优化功能贡献给社区,经过六个多月的改造,Blink的部分基本功能已经合并到Flink 1.9.0中,与此同时,阿里也收购了Flink创始团队成立的公司dataArtisans。在此之后,两个团队将共同维护一个新的品牌Ververica,该品牌推出新的界面平台Ververica Platform来为用户提供服务。
Why Flink+Kubernetes
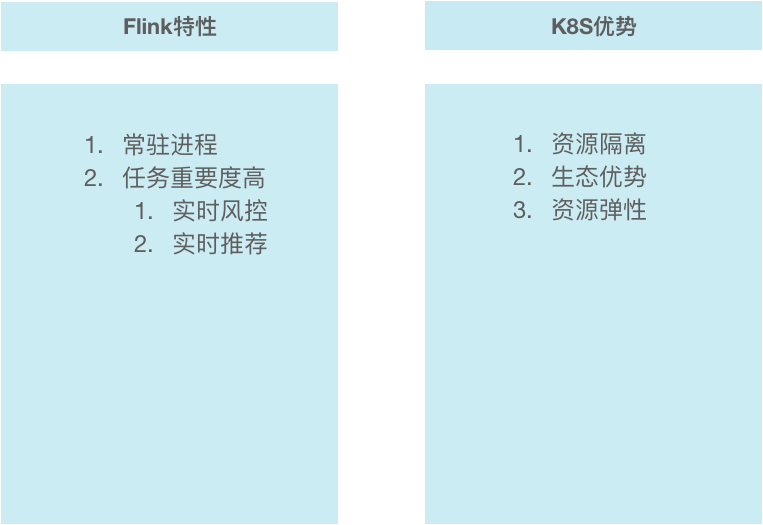
Flink之所以选择K8S来作为底层的资源管理来为用户提供服务主要原因有以下几点:
- Flink特性:首先Flink是大数据类应用,与传统大数据应用如Spark、Hadoop、MapReduce以及Hive等不同的是,Flink是常驻进程,其类似于在线业务的App,作业发布后修改频率比较低,,这就要求执行作业的worker长时间稳定运行。另外,与其他批处理作业相比,流作业任务一般应用于实时风控和实时推荐的业务场景下,其重要度更高,稳定性要求也更高。
- K8S优势:K8S设计的初衷是为在线应用服务,目标是为了帮助在线应用更好地发布和管理,实现资源隔离;其次,目前K8S具备一定的生态优势,目前很多用户已经开始或尝试开始使用K8S来管理在线应用;K8S可以很好地集成其他集群维护工具,如监控工具普罗米修斯,同时在资源弹性方面,K8S可以很方便地进行扩缩容。
Ververica Platform介绍
Ververica Platform平台所包含主要功能模块如下图所示:
- K8S集群:需要用户在阿里云上创建ACK集群(阿里云官网搜索ACK进入产品主页了解详情)。
- 可插拔组件:1) APP Manager。用户可通过APP Manager界面对作业进行提交和管理;2)开箱即用的指标收集、展示及报警组件,该组件集成了Prometheus的功能。3)日志收集、分析、展示组件
- 增值功能:首先是Libra智能调优系统。熟悉Flink的用户可能都知道,目前Flink的调优比较麻烦,尤其在开源Flink中,用户需要多次预估波峰流量来设置Flink作业的资源,否则在波峰的时候可能会出现作业延时。而所推出的Libra智能调优系统功能会根据波峰波谷的特点来自动调整Flink资源,在没有人为干预的情况下提高资源利用率,同时降低波峰时的作业延时。除此之外,平台还将提供Alink机器学习组件、Gemini等增值功能。
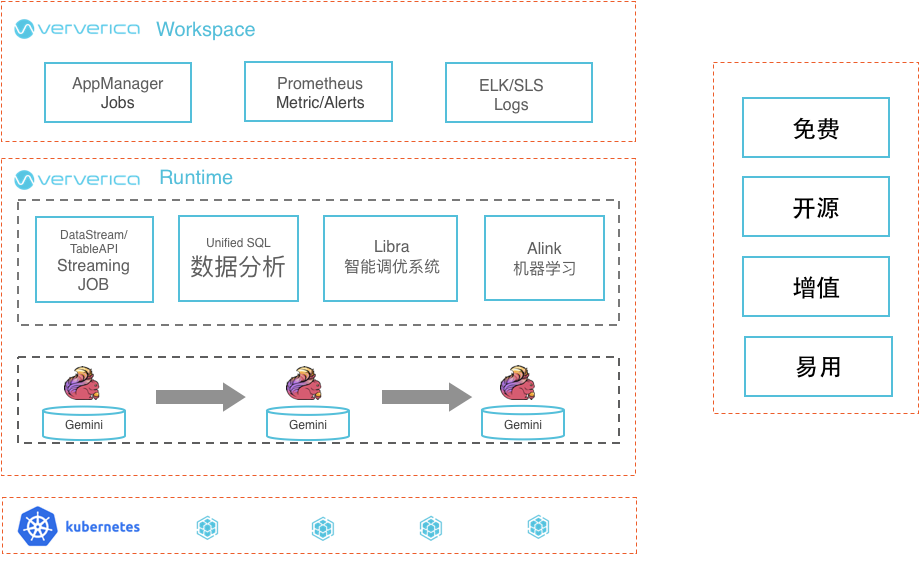
总体而言,Ververica Platform的特点是免费、开源、增值和易用。首先用户只需要支付ECS的费用便可以使用Ververica Platform平台的所有功能;其次Flink Core是开源的,用户无需的担心其兼容性和因为被某个平台绑架而产生的问题,并且开源Flink的功能可以无缝迁移到该平台上;此外,Ververica Platform提供了一系列增值功能,整个平台易用性较高。
下图是Ververica Platform的平台界面,通过该界面用户可以创建并提交一个Flink作业。用户可以设置Flink作业的名称、初始化状态、Flink版本(目前支持1.6/1.7/1.8)、Jar包地址以及开源资源配置(如并发度、Job Manager的CPC内存等),点击提交后可以很方便地在K8S上运行一个Flink作业。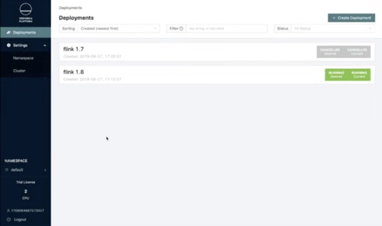
下图展示了一个已经在K8S上运行的作业,用户可以浏览整个作业的配置信息、拓扑图、在K8S上的Events、Jobs、Savepoints的状态·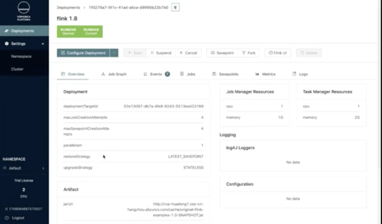
用户还可以在界面上直观地查看作业默认的metrics和logs信息,从而简化作业问题排查的复杂度。此外,该平台还支持直接显示Flink Web UI。目前的平台功能比较简洁,后续会将平台自动调优、Alink 机器学习等方面的功能纳入进来。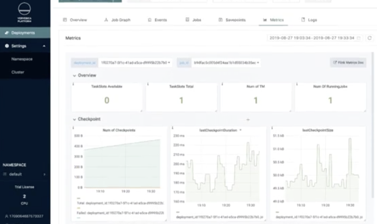
以上是阿里云Flink on Kubernetes产品形态的新功能,欢迎大家试用体验。试用的具体流程是:阿里云提交工单,工单选择实时计算产品,标明“希望试用实时计算Flink on Kubernetes产品形态”,之后便可以等待阿里云相关工作人员联系进行试用。
本文作者:小白薇薇
本文为云栖社区原创内容,未经允许不得转载。
实时计算Flink on Kubernetes产品模式介绍的更多相关文章
- 可以穿梭时空的实时计算框架——Flink对时间的处理
Flink对于流处理架构的意义十分重要,Kafka让消息具有了持久化的能力,而处理数据,甚至穿越时间的能力都要靠Flink来完成. 在Streaming-大数据的未来一文中我们知道,对于流式处理最重要 ...
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- Flink消费Kafka数据并把实时计算的结果导入到Redis
1. 完成的场景 在很多大数据场景下,要求数据形成数据流的形式进行计算和存储.上篇博客介绍了Flink消费Kafka数据实现Wordcount计算,这篇博客需要完成的是将实时计算的结果写到redis. ...
- Flink+kafka实现Wordcount实时计算
1. Flink Flink介绍: Flink 是一个针对流数据和批数据的分布式处理引擎.它主要是由 Java 代码实现.目前主要还是依靠开源社区的贡献而发展.对 Flink 而言,其所要处理的主要场 ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- Apache Flink 如何正确处理实时计算场景中的乱序数据
一.流式计算的未来 在谷歌发表了 GFS.BigTable.Google MapReduce 三篇论文后,大数据技术真正有了第一次飞跃,Hadoop 生态系统逐渐发展起来. Hadoop 在处理大批量 ...
- Flink实时计算pv、uv的几种方法
本文首发于:Java大数据与数据仓库,Flink实时计算pv.uv的几种方法 实时统计pv.uv是再常见不过的大数据统计需求了,前面出过一篇SparkStreaming实时统计pv,uv的案例,这里用 ...
随机推荐
- window location跳转
"top.location.href"是最外层的页面跳转"window.location.href"."location.href"是本页面 ...
- 3.7.4 Tri0 and tri1 nets
Frm: IEEE Std 1364™-2001, IEEE Standard Verilog® Hardware Description Language The tri0 and tri1 net ...
- SPN扫描利用
一.利用环境: 在内网渗透的信息收集中,机器服务探测一般都是通过端口扫描去做的,但是有些环境不允许这些操作.通过利用 SPN 扫描可快速定位开启了关键服务的机器,这样就不需要去扫对应服务的端口,有效规 ...
- this 、typeof、false、parseInt()、this、arguments、Array和object判断
typeof typeof (undefined) 不会报错 undefined object Number boolean function String 返回值为字符串类型 false .fals ...
- 【luoguP3868】猜数字
description 现有两组数字,每组k个,第一组中的数字分别为:a1,a2,...,ak表示,第二组中的数字分别用b1,b2,...,bk表示.其中第二组中的数字是两两互素的.求最小的非负整数n ...
- js字符串去重复
var str="fdafdasfdasfdsfdseeeu"; function te(str){ var hash=[]; var arr=new Array(); var s ...
- thinkphp 变量输出
在模板中输出变量的方法很简单,例如,在控制器中我们给模板变量赋值: 大理石平台支架 $name = 'ThinkPHP'; $this->assign('name',$name); $this- ...
- docker-compose安装及docker-compose.yml详解
1.下载安装 [root@cx-- ~]# curl -L https://github.com/docker/compose/releases/download/1.24.1/docker-comp ...
- C++在#include命令中,用〈 〉和“”有什么区别
使用尖括号表示在包含文件目录中去查找(包含目录是由用户在设置环境时设置的),而不在源文件目录去查找: 使用双引号则表示首先在当前的源文件目录中查找,若未找到才到包含目录中去查找.
- django2 rest_framework + vue.js + mysql5.6 实现增删改查
1.安装pymysql,mysqlclient,创建项目django-admin startproject django3 2.在Mysql中创建一个数据库叫django3db,打开项目,修改一下数据 ...