大量SQL的解决方案——sdmap
大量SQL的解决方案——sdmap
最近看到群里面经常讨论大型应用中SQL的管理办法,有人说用EF/EF Core,但很多人不信任它生成SQL的语句;有人说用Dapper,但将SQL写到代码中有些人觉得不合适;有人提出用存储过程,但现在舆论纷纷反对这种做法;有人提出了iBatis.NET,它可以配置确保高灵活性高性能,也提供动态SQL的功能,但已经多年没有维护。
在几年前,我们某项目中就有总共4MB以上的SQL语句文本,我也注意到产品做大后会,一定出现这个问题,所以我就依照MyBatis的核心思想,支持可配置、动态SQL,但去除了臃肿的xml,自己实现了一套简单好用的语法,然后开源了出来,名字就叫sdmap。
在我的介绍页面上已经指出,sdmap的如下特性:
- 非常简单的语法来描述动态
SQL; - 使用了
Emit CIL来确保性能; - 有
Visual Studio插件支持,实现了代码高亮、代码折叠、快速导航的特性; - 支持所有主流数据库,如
MySQL、SQL Server、SQLite等(只要Dapper能支持); - 可以扩展支持非关系型数据库,如
Neo4j; - 单元测试全覆盖。
语法
如图:
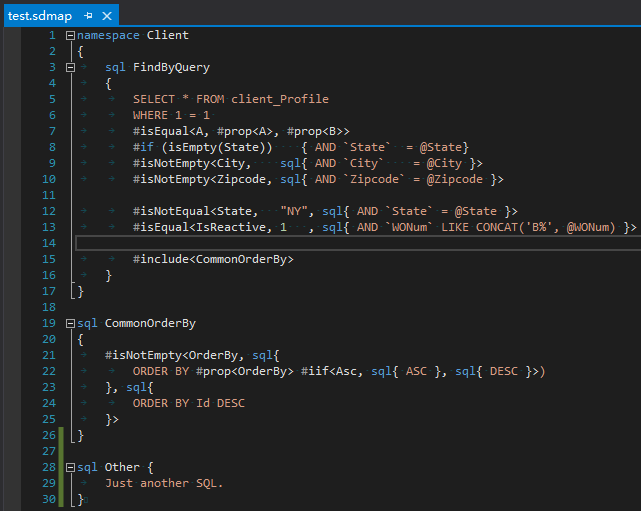
该语法有如下特点:
- 用
namespace关键字表达名字空间; - 用
sql关键字表示模板语句; - 用
#号的特殊语法可以进行一些判断,里面有isEqual<>、#isNotEmpty<>等特殊语法; - 用
#include<>,可以包含另一个SQL语句; - 语句可以嵌套,
sql{}中可以包含另一个sql{}。
我们可以对比一下iBatis/MyBatis的语法:
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.apache.ibatis.submitted.rounding.Mapper">
<resultMap type="org.apache.ibatis.submitted.rounding.User" id="usermap">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="funkyNumber" property="funkyNumber"/>
<result column="roundingMode" property="roundingMode"/>
</resultMap>
<select id="getUser" resultMap="usermap">
select * from users
</select>
<insert id="insert">
insert into users (id, name, funkyNumber, roundingMode) values (
#{id}, #{name}, #{funkyNumber}, #{roundingMode}
)
</insert>
<resultMap type="org.apache.ibatis.submitted.rounding.User" id="usermap2">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="funkyNumber" property="funkyNumber"/>
<result column="roundingMode" property="roundingMode"
typeHandler="org.apache.ibatis.type.EnumTypeHandler"/>
</resultMap>
<select id="getUser2" resultMap="usermap2">
select * from users2
</select>
<insert id="insert2">
insert into users2 (id, name, funkyNumber, roundingMode) values (
#{id}, #{name}, #{funkyNumber}, #{roundingMode, typeHandler=org.apache.ibatis.type.EnumTypeHandler}
)
</insert>
</mapper>
相比之下,由于XML的存在,MyBatis的语法有更多噪音。
简单应用
Hello World
其实和MyBatis不同,sdmap设计之初就只考虑好好做一个小巧、精致、快速的模板引擎。因此sdmap可以不依赖于任何数据库,只做字符串解析,最简单的代码是:
// 安装NuGet包:sdmap
var c = new SdmapCompiler();
c.AddSourceCode("sql v1 {Hello World}");
Console.WriteLine(c.Emit("v1", null)); // Hello World
参数传入
当然有一些前端输入,这样就需要第二个参数:
var c = new SdmapCompiler();
c.AddSourceCode("sql v1 {Hello #prop<Name>!}");
Console.WriteLine(c.Emit("v1", new { Name = "Hero"})); // Hello Hero!
注意我使用了一个#prop<>的语法,这是sdmap中调用指令的语句,表示将Name属性按原样显示在此处。
参数判断
有些语句需要根据前端的不同而不同,比如典型的“动态SQL”问题,如果前端传了参数,则执行过滤,没有传则不过滤,这样的代码如下:
var c = new SdmapCompiler();
c.AddSourceCode(@"
sql v1
{
SELECT * FROM [Customer]
WHERE 1=1
#isNotEmpty<Location, sql {AND Location = '#prop<Location>'}
}");
Console.WriteLine(c.Emit("v1", new { Id = 1, Location = "长沙"}));
Console.WriteLine(c.Emit("v1", new { Id = 2, Location = ""}));
输出结果如下:
SELECT * FROM [Customer]
WHERE 1=1
AND Location = '长沙'
SELECT * FROM [Customer]
WHERE 1=1
可见,关键的那个isNotEmpty<>控制了Location判断的语句。
扩展:sdmap.ext
每次使用时,都需要实例化一个SdmapCompiler来加载sdmap语句很麻烦,在项目中,这部分逻辑重用度非常高,因此我写了一个扩展:sdmap.ext,定义了ISdmapEmiter接口,该接口定义如下:
public interface ISdmapEmiter
{
string Emit(string statementId, object parameters);
}
相当于最简单的生成器,然后我写了几个内置实现,可以直接从文件系统或者程序集嵌入的资源中读入这些文件:
public class EmbeddedResourceSqlEmiter : ISdmapEmiter
{
public static EmbeddedResourceSqlEmiter CreateFrom(Assembly assembly);
// ...
}
public class MultipleAssemblyEmbeddedResourceSqlEmiter : ISdmapEmiter
{
public static MultipleAssemblyEmbeddedResourceSqlEmiter CreateFrom(params Assembly[] assemblies);
// ...
}
public class FileSystemSqlEmiter : ISdmapEmiter
{
public static FileSystemSqlEmiter FromSqlDirectory(
string sqlDirectory,
bool ensureCompiled = false);
public static FileSystemSqlEmiter FromSqlDirectoryAndWatch(
string sqlDirectory,
bool ensureCompiled = false);
// ...
}
那么有人会问,数据库参数化该如何实现呢?
扩展:sdmap.ext.Dapper
答案是Dapper,sdmap访问数据库时,依赖Dapper做参数化。其实很好理解,sdmap只做数据库访问时的SQL模板引擎前端,Dapper做后端(当然不一定非要用Dapper),sdmap只负责生成SQL语句。
但随着大家使用越来越多,我也注意到确实可以写一些东西,便于大家更好地配合Dapper一起使用。因此我写了另外两个扩展:sdmap.ext和sdmap.ext.Dapper。
其中sdmap.ext仍然和数据库无关,定义了一些.sdmap文件的读取和自动加载逻辑;sdmap.ext.Dapper依赖于Dapper,定义了一些便利方法:

如图,用过Dapper的朋友知道,Dapper为IDbConnection定义了一套扩展方法,这里我也为IDbConnection定义了一套一样的扩展,只要最后加了ByMap后缀,第二个参数都为sqlMapName,与其传入原始的SQL语句,此处将传入定义在.sdmap文件中的配置,如原先使用Dapper的朋友,代码可能这样写:
var data = _db.Query<Customer>("SELECT * FROM [Customer] Where Id = @Id");
换成sdmap后,代码应该是这样写:
var data = _db.QueryByMap<Customer>("Customers.GetById");
然后sdmap配置如下:
namespace Customers
{
sql GetById
{
SELECT * FROM [Customer] WHERE Id = @Id
}
}
注意,sdmap使用了Dapper的参数化方式,只需在SQL中写@Id这样的语句,即可自动实现参数化,得出结果完全一样,并且SQL不存在注入问题,代码中不包含SQL语句,语句都写在配置文件中。
数组参数化
由于Dapper的存在,sdmap相当于也自动支持了数组的参数化,只要像Dapper那样写IN即可:
namespace Customer
{
sql GetByIds
{
SELECT * FROM [Customer] WHERE Id IN @Ids
}
}
相关链接
Github地址
https://github.com/sdcb/sdmap
我的Github首页还包含了使用sdmap.ext.Dapper的一步一步使用教程,可以依照上面的使用。
文档地址
https://github.com/sdcb/sdmap/wiki
所有指令参考链接:
https://github.com/sdcb/sdmap/wiki/Common-macros
NuGet包地址
- https://www.nuget.org/packages/sdmap
- https://www.nuget.org/packages/sdmap.ext
- https://www.nuget.org/packages/sdmap.ext.Dapper
Visual Studio插件地址
https://marketplace.visualstudio.com/items?itemName=sdmapvstool.sdmapvstool
VS插件提供了.sdmap文件代码高亮、自动定位、代码折叠的功能,可以不装,但不装就没这些体验。
总结
我写sdmap最初纯粹是因为想挑战自己,它包含了【编译器前端——ANTLR】、【编译器后端——CIL】、【Visual Studio插件如何制作】、单元测试、文档等主题。
但后来随着这个项目的发展,越来越多的朋友用了起来。用过的都纷纷提出了自己的想法,然后做了许多润色,解决了不少局限性,但我从未做过推广——这是我第一次将这个项目用文字的形式发表出来。希望这个项目能给大家以管理大量SQL的启发。
上文中提到了许多有意思的主题,2020年到了,我有空就会一一介绍这些主题,都非常有意思,最重要的是,其实都很好学
大量SQL的解决方案——sdmap的更多相关文章
- 城市经纬度 json 理解SignalR Main(string[] args)之args传递的几种方式 串口编程之端口 多线程详细介绍 递归一个List<T>,可自己根据需要改造为通用型。 Sql 优化解决方案
城市经纬度 json https://www.cnblogs.com/innershare/p/10723968.html 理解SignalR ASP .NET SignalR 是一个ASP .NET ...
- Sql 优化解决方案
转自:https://blog.csdn.net/jie_liang/article/details/77340905 用以记录: 在sql查询中为了提高查询效率,我们常常会采取一些措施对查询语句进行 ...
- 开发板远程操作SQL SERVER解决方案
环境: 开发板:freescale 2.6 armv71,系统只读,唯一可以读写的路径是/tmp/sd(这是一个sd卡).程序放在/tmp/sd/transfer下(下文以运行路径代替),sql语句以 ...
- 在ABP中通过EF直接执行原生Sql的解决方案
一般情况下,使用EF中的查询语法和方法语法可以帮助我们完成绝大部分业务,但是也有特殊的情况需要直接执行Sql语句.比如,我们的业务过于复杂繁琐,或是有些业务使用EF操作时比较复杂,但是使用Sql时会很 ...
- Ubuntu12.10下Python(pyodbc)访问SQL Server解决方案
一.基本原理 请查看这个网址,讲得灰常详细:http://www.jeffkit.info/2010/01/476/ 二.实现步骤 1.安装linux下SQL Server的驱动程序 安装Free ...
- 面试遇到的订单表sql的解决方案
对于以下需求:用户表:users (user_id int)订单表:order_tb(user_id int, or_time date, or_money double)求以下用户:一月下过单, ...
- ubuntu下连microsoft sql server解决方案
shell for MSSQL: https://github.com/dbcli/mssql-cli mssql-cli -S 127.0.0.1,1433 -d testDB -U myuser ...
- sql注入原理及解决方案
sql注入原理 sql注入原理就是用户输入动态的构造了意外sql语句,造成了意外结果,是攻击者有机可乘 SQL注入攻击指的是通过构建特殊的输入作为参数传入Web应用程序,而这些输入大都是SQL语法里的 ...
- SQL Server认证培训与考试
Microsoft 技术专员 (MTA) - 数据库 https://www.microsoft.com/zh-cn/learning/mta-certification.aspx MCSA: SQL ...
随机推荐
- laravel 学习笔记blog后台
https://github.com/almasaeed2010/adminlte composer require "almasaeed2010/adminlte=~2.0"
- 根据IP定位用户所在城市信息
http://www.9958.pw/post/city_ip 1.调用新浪IP地址库 新浪提供了开放的IP地址库数据供开发者调用,调用地址: http://int.dpool.sina.com.cn ...
- 打开phpstorm 的terminal 工具框的快捷键 alt+F12
打开phpstorm 的terminal 工具框的快捷键 alt+F12 Alt + #[0-9] 打开相应的工具窗口
- PHP实现微信小程序人脸识别刷脸登录功能
首先我们先确认我们的百度云人脸库里已经上传了我们的个人信息照片 然后我们在后台写刷脸登陆的接口login我们要把拍照获取的照片存储到服务器 public function login(){ // ...
- Python--day66--内容回顾
3,python中的大小比较和js中的大小比较规则: python中a>b>c,就是先比较a>b,然后再比较b>c,都为true的话就返回true: js中的a>b> ...
- java什么叫面向对象?
面向对象(Object-Oriented,简称OO)就是一种常见的程序结构设计方法. 面向对象思想的基础是将相关的数据和方法放在一起,组合成一种新的复合数据类型,然后使用新创建的复合数据类型作为项目的 ...
- H3C 通配符掩码的应用示例
- java 内省 了解JavaBean
JavaBean是一种特殊的Java类,主要用于传递数据信息,这种java类中的方法主要用于访问私有的字段,且方法名符合某种命名规则. 如果要在两个模块之间传递多个信息,可以将这些信息封装到一个Jav ...
- P1025 最大完美度
题目描述 定义一个字符串的完美度为字符串中所有字符的完美度的和. 现在给你一个只含字母的字符串s, 每一个字母的完美度由你进行分配, 可以分配给一个字母[1,26]中的一个数字作为完美度, 但每个字母 ...
- H3C 配置路由器作为FTP服务器端