Python读写Excel文件的实例
最近由于经常要用到Excel,需要根据Excel表格中的内容对一些apk进行处理,手动处理很麻烦,于是决定写脚本来处理。首先贴出网上找来的读写Excel的脚本。 1.读取Excel(需要安装xlrd):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#-*- coding: utf8 -*-import xlrd fname = "reflect.xls"bk = xlrd.open_workbook(fname)shxrange = range(bk.nsheets)try: sh = bk.sheet_by_name("Sheet1")except: print "no sheet in %s named Sheet1" % fname#获取行数nrows = sh.nrows#获取列数ncols = sh.ncolsprint "nrows %d, ncols %d" % (nrows,ncols)#获取第一行第一列数据 cell_value = sh.cell_value(1,1)#print cell_value row_list = []#获取各行数据for i in range(1,nrows): row_data = sh.row_values(i) row_list.append(row_data) |
2.写入Excel(需安装pyExcelerator)
|
1
2
3
4
5
6
7
8
|
from pyExcelerator import *w = Workbook() #创建一个工作簿ws = w.add_sheet('Hey, Hades') #创建一个工作表ws.write(0,0,'bit') #在1行1列写入bitws.write(0,1,'huang') #在1行2列写入huangws.write(1,0,'xuan') #在2行1列写入xuanw.save('mini.xls') #保存 |
3.再举个自己写的读写Excel的例子 读取reflect.xls中的某些信息进行处理后写入mini.xls文件中。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
#-*- coding: utf8 -*-import xlrdfrom pyExcelerator import * w = Workbook() ws = w.add_sheet('Sheet1') fname = "reflect.xls"bk = xlrd.open_workbook(fname)shxrange = range(bk.nsheets)try: sh = bk.sheet_by_name("Sheet1")except: print "no sheet in %s named Sheet1" % fnamenrows = sh.nrowsncols = sh.ncolsprint "nrows %d, ncols %d" % (nrows,ncols) cell_value = sh.cell_value(1,1)#print cell_value row_list = []mydata = []for i in range(1,nrows): row_data = sh.row_values(i) pkgdatas = row_data[3].split(',') #pkgdatas.split(',') #获取每个包的前两个字段 for pkgdata in pkgdatas: pkgdata = '.'.join((pkgdata.split('.'))[:2]) mydata.append(pkgdata) #将列表排序 mydata = list(set(mydata)) print mydata #将列表转化为字符串 mydata = ','.join(mydata) #写入数据到每行的第一列 ws.write(i,0,mydata) mydata = [] row_list.append(row_data[3])#print row_listw.save('mini.xls') |
4.现在我需要根据Excel文件中满足特定要求的apk的md5值来从服务器获取相应的apk样本,就需要这样做:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#-*-coding:utf8-*-import xlrdimport osimport shutil fname = "./excelname.xls"bk = xlrd.open_workbook(fname)shxrange = range(bk.nsheets)try: #打开Sheet1工作表 sh = bk.sheet_by_name("Sheet1")except: print "no sheet in %s named Sheet1" % fname#获取行数nrows = sh.nrows#获取列数ncols = sh.ncols#print "nrows %d, ncols %d" % (nrows,ncols)#获取第一行第一列数据cell_value = sh.cell_value(1,1)#print cell_value row_list = []#range(起始行,结束行)for i in range(1,nrows): row_data = sh.row_values(i) if row_data[6] == "HXB": filename = row_data[3]+".apk" #print "%s %s %s" %(i,row_data[3],filename) filepath = r"./1/"+filename print "%s %s %s" %(i,row_data[3],filepath) if os.path.exists(filepath): shutil.copy(filepath, r"./myapk/") |
补充一个使用xlwt3进行Excel文件的写操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import xlwt3if __name__ == '__main__': datas = [['a', 'b', 'c'], ['d', 'e', 'f'], ['g', 'h']]#二维数组 file_path = 'D:\\test.xlsx' wb = xlwt3.Workbook() sheet = wb.add_sheet('test')#sheet的名称为test #单元格的格式 style = 'pattern: pattern solid, fore_colour yellow; '#背景颜色为黄色 style += 'font: bold on; '#粗体字 style += 'align: horz centre, vert center; '#居中 header_style = xlwt3.easyxf(style) row_count = len(datas) col_count = len(datas[0]) for row in range(0, row_count): col_count = len(datas[row]) for col in range(0, col_count): if row == 0:#设置表头单元格的格式 sheet.write(row, col, datas[row][col], header_style) else: sheet.write(row, col, datas[row][col]) wb.save(file_path) |
输出的文件内容如下图:
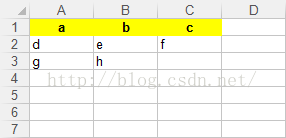
注:以上代码在Python 3.x版本测试通过。
好了,python操作Excel就这么!些了,简单吧
Python读写Excel文件的实例的更多相关文章
- [转]用Python读写Excel文件
[转]用Python读写Excel文件 转自:http://www.gocalf.com/blog/python-read-write-excel.html#xlrd-xlwt 虽然天天跟数据打交 ...
- python读写Excel文件的函数--使用xlrd/xlwt
python中读取Excel的模块或者说工具有很多,如以下几种: Packages 文档下载 说明 openpyxl Download | Documentation | Bitbucket The ...
- Python读写Excel文件和正则表达式
Python 读写Excel文件 这里使用的是 xlwt 和 xlrd 这两个excel读写库. #_*_ coding:utf-8 _*_ #__author__='观海云不远' #__date__ ...
- 用Python读写Excel文件(转)
原文:google.com/ncr 虽然天天跟数据打交道,也频繁地使用Excel进行一些简单的数据处理和展示,但长期以来总是小心地避免用Python直接读写Excel文件.通常我都是把数据保存为以TA ...
- 用Python读写Excel文件的方式比较
虽然天天跟数据打交道,也频繁地使用Excel进行一些简单的数据处理和展示,但长期以来总是小心地避免用Python直接读写Excel文件.通常我都是把数据保存为以TAB分割的文本文件(TSV),再在Ex ...
- Python读写EXCEL文件常用方法大全
前言 python读写excel的方式有很多,不同的模块在读写的讲法上稍有区别,这里我主要介绍几个常用的方式. 用xlrd和xlwt进行excel读写: 用openpyxl进行excel读写: 用pa ...
- python 读写 Excel文件
最近用python处理一个小项目,其中涉及到对excel的读写操作,通过查资料及实践做了一下总结,以便以后用. python读写excel文件要用到两个库:xlrd和xlwt,首先下载安装这两个库. ...
- python读写Excel文件--使用xlrd模块读取,xlwt模块写入
一.安装xlrd模块和xlwt模块 1. 下载xlrd模块和xlwt模块 到python官网http://pypi.python.org/pypi/xlrd下载模块.下载的文件例如:xlrd-0.9. ...
- python读写Excel文件_xlrd模块读取,xlwt模块写入
一.安装xlrd模块和xlwt模块(服务器) 1. 下载xlrd模块和xlwt模块 到python官网http://pypi.python.org/pypi/xlrd下载模块.下载的文件例如:xlrd ...
随机推荐
- ETCD:etcd网关
原文地址:L4 gateway 什么是etcd网关 etcd网关是一个简单的TCP代理,可将网络数据转发到etcd集群.网关是无状态且透明的: 它既不会检查客户端请求,也不会干扰群集响应. 网关支持多 ...
- halcon 算子功能查找大全中文版(可直接下载)
原文作者:aircraft 原文链接:https://www.cnblogs.com/DOMLX/p/11543364.html haicon算子中文查找大全百度云链接 链接:https://pan. ...
- c#时间戳相互转换
/// <summary> /// 获取时间戳 /// </summary> /// <returns></returns> public static ...
- IDEA中新建SpringBoot项目时提示:Artifact contains illegal characters
场景 一步一步教你在IEDA中快速搭建SpringBoot项目: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/87688277 ...
- echarts背景颜色渐变的三种类型
// 线性渐变,多用于折线柱形图,前四个参数分别是 x0, y0, x2, y2, 范围从 0 - 1,相当于在图形包围盒中的百分比,如果 globalCoord 为 `true`,则该四个值是绝对的 ...
- [转]Sumifs函数多条件求和的9个实例
本文转自:http://m.officezhushou.com/sumif/5187.html 第一部分:sumifs函数用法介绍 excel中sumifs函数是Excel2007以后版本新增的多条件 ...
- TypeScript 学习笔记(四)
函数: 1.函数是一组一起执行一个任务的语句 2.我们可以把一段可复用的代码放到一起组成函数,从而提高效率 3.函数声明(通过关键字 function 来声明)告诉编译器函数的名称.返回类型和参数 4 ...
- windows下安装react
在 Windows 10 64 下创建 React App 由 SHUIJINGWAN · 2018/03/26 1.在官方网站:https://nodejs.org/zh-cn/ 下载推荐版本: ...
- Django使用xadmin集成富文本编辑器Ueditor(方法二)
一.xadmin的安装与配置1.安装xadmin,其中第一种在python3中安装不成功,推荐第二种或者第三种 方式一:pip install xadmin 方式二:pip install git+g ...
- jQuery实现简单的tab切换
html: <section> <nav id="nav"> <a class="on">tab1</a& ...