hdfs standby namenode checkpoint 的一些参数
dfs.namenode.checkpoint.period
--两次检查点创建之间的固定时间间隔,默认3600,即1小时。所以去ann snn 看到的fsimage 相隔1个小时。
dfs.namenode.checkpoint.txns
--standby namenode 检查的事务数量。若检查事务数达到这个值,也触发一次checkpoint,1,000,000。
以上两个参数都是触发snn checkpoint 的条件
dfs.namenode.checkpoint.check.period
--standby namenode检查是否满足建立checkpoint的条件的检查周期。默认60,即每1min检查一次。
dfs.namenode.num.checkpoints.retained
--在namenode上保存的fsimage的数目,超出的会被删除。默认保存2个。
dfs.namenode.num.checkpoints.retained
--最多能保存的edits文件个数,默认为1,000,000. 为防止standby namenode宕机导致edits文件堆积的情况,设置的限制。
dfs.ha.tail-edits.period
--standby namenode每隔多长时间去检测新的Edits文件。只检测完成了的Edits, 不检测inprogress的文件。default:60s
StandbyCheckpointer 的doWork()
SNN查看是否满足创建checkpoint 的条件:
1) 距离上次checkpoint的时间间隔 >= ${dfs.namenode.checkpoint.period}(
2) Edits中的事务条数达到${dfs.namenode.checkpoint.txns}限制
这两个条件任何一个被满足了,就触发一次checkpoint 创建。
也可以手动checkpoint :
1. hdfs dfsadmin -safemode enter
>Safe mode is ON in dev01/192.168.254.43:8020
>Safe mode is ON in dev02/192.168.254.44:8020
2. hdfs dfsadmin -saveNamespace
> Save namespace successful for dev01/192.168.254.43:8020
> Save namespace successful for dev02/192.168.254.44:8020
3. hdfs dfsadmin -safemode leave
>Safe mode is OFF in dev01/192.168.254.43:8020
>Safe mode is OFF in dev02/192.168.254.44:8020
首先,checkpoint 之前要先进入安全模式。进入安全模式后,执行saveNamespace命令,他会把a-nn的fsimage 与 大于fsimage txid的editlog(包括finalized 与 in_progress的)合并成新的fsimage并落盘,然后新生成一个editlog。
checkpoint before:

checkpoint after:
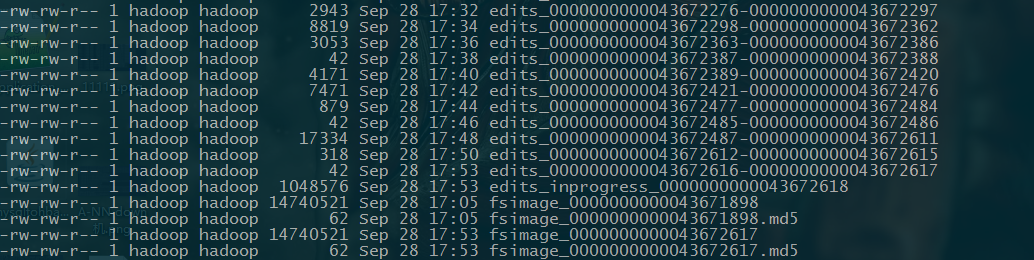
参考:http://blog.cloudera.com/blog/2014/03/a-guide-to-checkpointing-in-hadoop/
hdfs standby namenode checkpoint 的一些参数的更多相关文章
- hadoop 的HDFS 的 standby namenode无法启动事故处理
standby namenode无法启动 现象:线上使用的2.5.0-cdh5.3.2版本Hadoop,开启了了NameNode HA,HA采用QJM方式.hadoop的集群的namenode的sta ...
- HDFS的namenode从单节点扩展为HA需要注意的问题
扩展为HA需要注意的问题 原Namenode称为namenode1,新增的Namenode称为namenode2. 从namenode单节点扩展为HA模式官网上有详细的教程,下面是扩展过程中疏忽的地方 ...
- HDFS之NameNode
NameNode&Secondary NameNode工作机制 1)第一阶段:namenode启动 (1)第一次启动namenode格式化后,创建fsimage和edits文件.如果不是第一次 ...
- HDFS中NameNode管理元数据机制
NameNode职责 响应客户端请求 维护目录树 管理元数据(查询,修改) HDFS元数据存储 内存中有一份完整的元数据(特定数据结构) 磁盘有一个“准完整”的元数据的镜像文件 当客户端对HDFS中的 ...
- HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制 0)启动概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个 ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- HDFS中的checkpoint( 检查点 )的问题
1.问题的描述 由于某种原因,需要在原来已经部署了Cloudera CDH集群上重新部署,重新部署之后,启动集群,由于Cloudera Manager 会默认设置dfs.namenode.checkp ...
- Hadoop之HDFS及NameNode单点故障解决方案
Hadoop之HDFS 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: http://www.cnblogs.com/sxt-zkys/QQ技术交流群:299142667 H ...
- HDFS中namenode启动失败
1.环境配置: -1.core-site.xml文件 <configuration> <property> <name>fs.defaultFS</name& ...
随机推荐
- 【巷子】---react-redux---【react】
一.Redux与组件 react-redux是一个第三方插件使我们在react上更方便的来使用redux这个数据架构 React-Redux提供connect方法,用于从UI组件生成容器组件,conn ...
- php 二维数组按照指定字段进行排序
$allItem = [ ["id"=>10,"updated_at"=>"2018-11-01"], ["id&qu ...
- 黄聪:VS2017调试时提示“运行时无法计算表达式的值”
具体操作: 工具-选项-调试-常规,选中“使用托管兼容模式”,问题解决
- elasticsearch 口水篇(4)java客户端 - 原生esClient
上一篇(elasticsearch 口水篇(3)java客户端 - Jest)Jest是第三方客户端,基于REST Api进行调用(httpClient),本篇简单介绍下elasticsearch原生 ...
- vue过渡
vue在插入.更新或者移除DOM时,提供了多种不同方式的应用过渡效果,下面主要总结一些常用的过渡. 单元素过渡(vue1.0) 我们常用的动画是css3的动画,在vue中依旧有效. <!DOCT ...
- Oracle 锁的概念
用scott/orcl登录并且模拟数据 SQL> conn scott/orclConnected.SQL> create table tt(id int primary key); Ta ...
- [UE4]UMG编辑器:中心点对齐
- conda命令
- vmware workstation14嵌套安装kvm
1.前言 我在2017-11-06使用virtualbox安装了centos,然后嵌套kvm(win7),链接地址如下: https://www.cnblogs.com/tcicy/p/7790956 ...
- 匿名内部类中不能修改int变量时、final int i 不能改变i的值时、或 i++线程不安全。使用AtomicInteger;
在匿名内部类或某某情况下中引入的变量必须是Final最终型的:这时还想要去修改这个变量就需要使用到AtomicInteger这个类了: AtomicInteger CarSize = new Atom ...