编写hadoop程序,并打包jar到hadoop集群运行
windows环境下编写hadoop程序
- 新建:File->new->Project->Maven->next
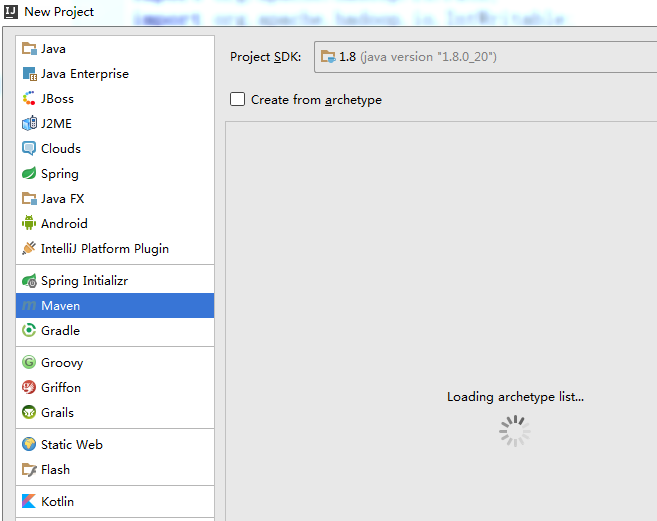
GroupId 和ArtifactId 随便写(还是建议规范点)->finfsh

会生成pom.xml,文件内容如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hadoopbook</groupId>
<artifactId>hadoop-demo</artifactId>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
- 可以网上找个wordCount(单词计数)源码进行测试,复制进去会发现以下的那些包都是报红,因为许多类都是无法识别的。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
接下来打开File->project Structure->Modules->右侧+->JARs or directories
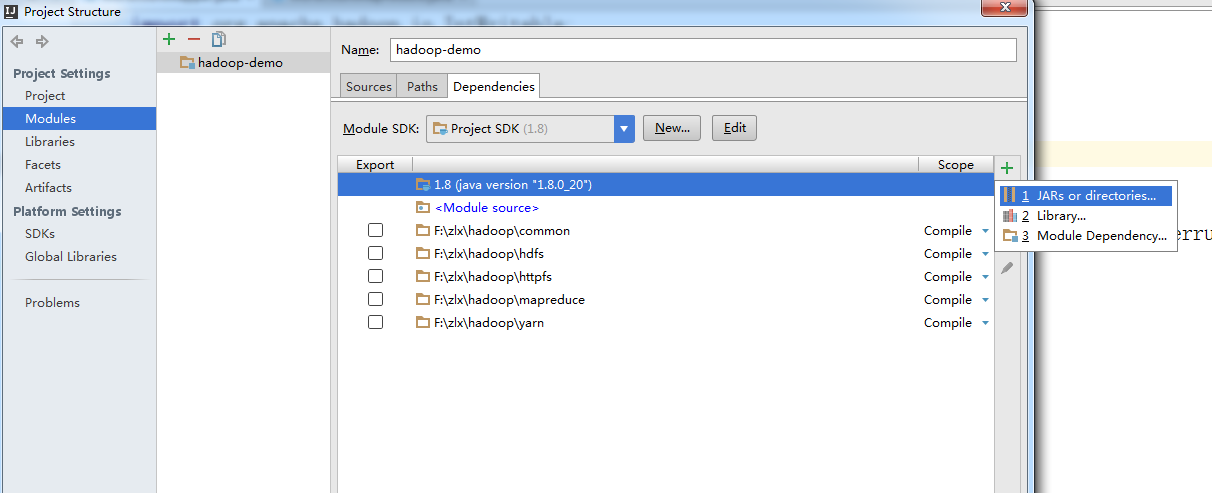
将你hadoop集群里面下载的jar包全部导入进去
点击左侧Arifacts ->+->JAR->empty
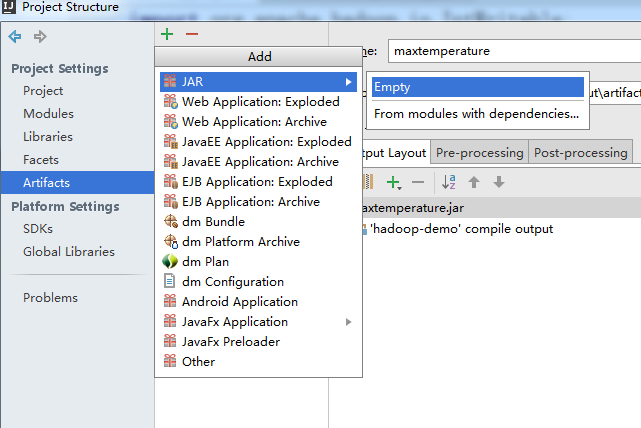
点击output layout下方的+,选择module output,然后勾选我们的项目,点击确定,这时报错的信息就没有了
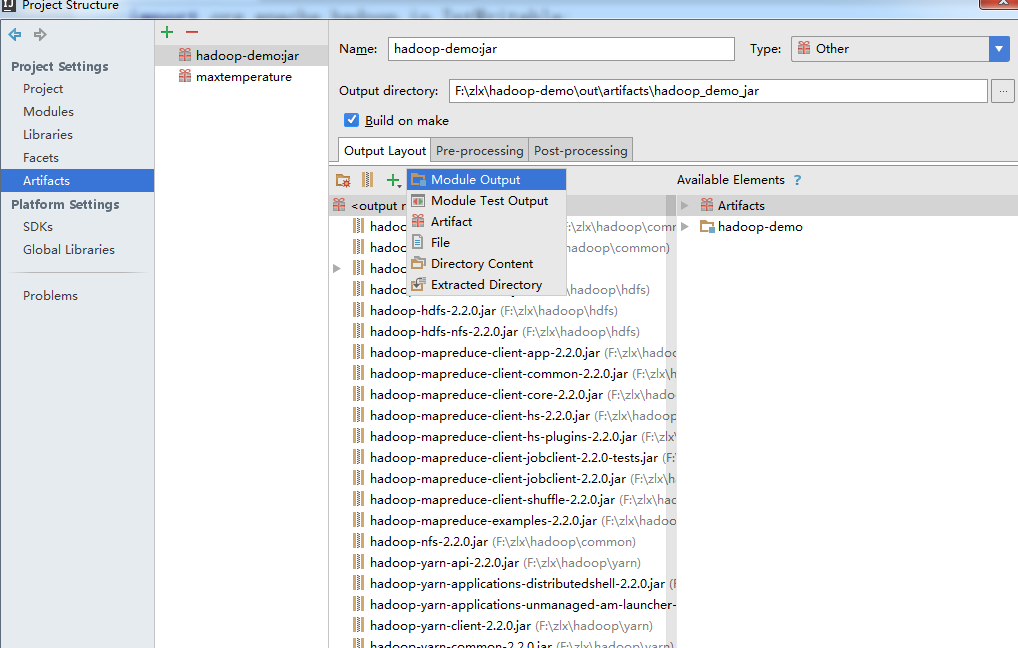
idea打包成jar
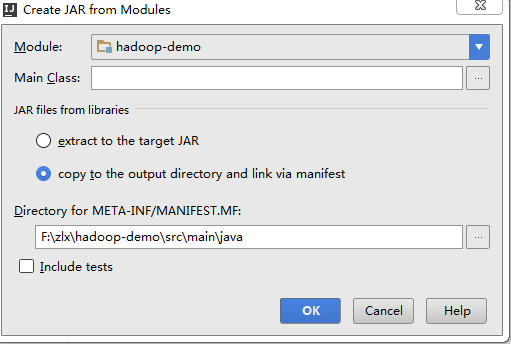
- File->project Structure->点击左侧Arifacts->+->JAR->From modules with dependenciestu,Build on make打上勾
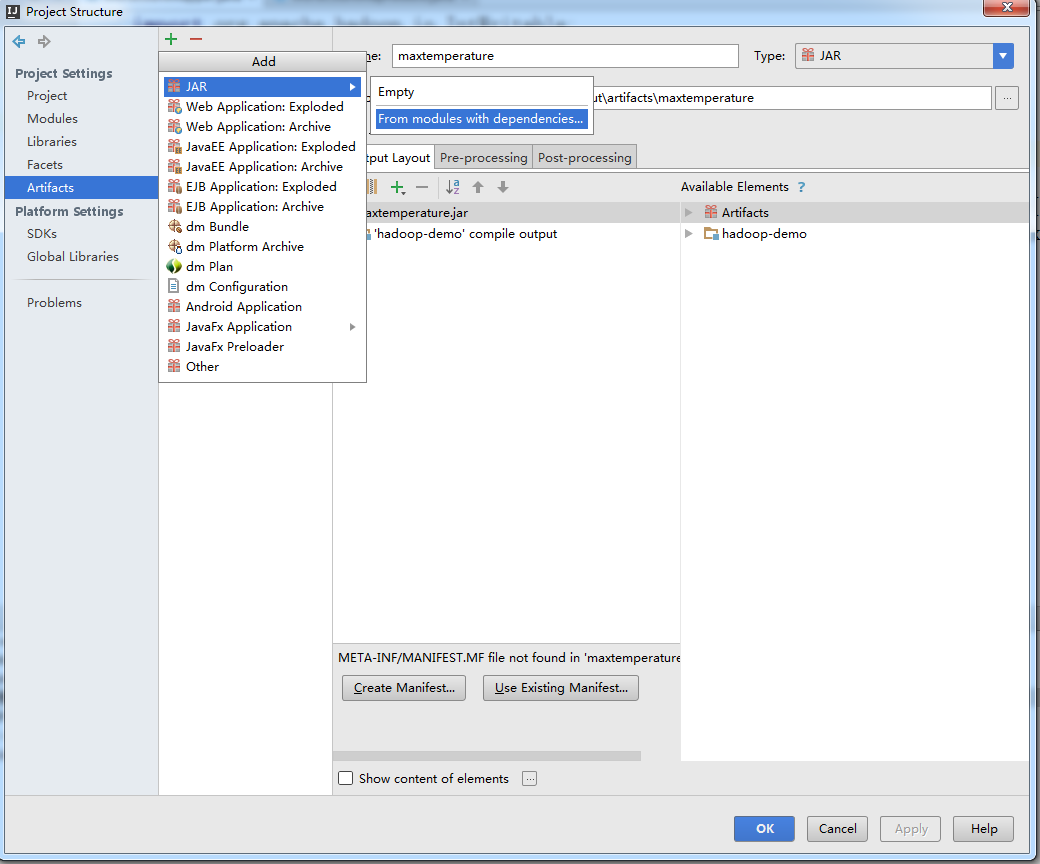
MAain.class为程序的主方法,相当于程序的入口
JAR files from libraries选第二个,选定输出路径->ok
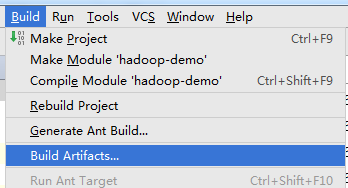
- Build->Build Arifacts->项目的jar->build->到输出路径查看即可。
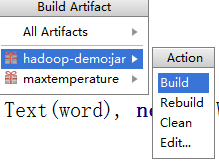
上传jar包到hadoop集群并运行
- 利用远程工具将生成的.jar上传到hadoop主节点的目录下(/app/hadoop/hadoop-2.2.0)目录根据自己的情况而定
- 创建input目录
hadoop fs -mkdir -p /usr/hadoop/input
- 复制本地文件到hdfs文件系统
hadoop fs -put test.txt /usr/hadoop/input
- 现在.jar有了,输入文件有了,执行.jar。切记不要自己手动提前新建输出文件
hadoop jar hadoop_demo_jar/hadoop-demo.jar workCount /usr/hadoop/input /usr/hadoop/output
- 执行成功

- 查看输出结果
hadoop fs -cat /usr/hadoop/output/*

HDFS常用命令可以参考这篇博客写得不错:https://blog.csdn.net/sunshingheavy/article/details/53227581
编写hadoop程序,并打包jar到hadoop集群运行的更多相关文章
- flink idea 打包jar 并放到集群上运行
flink idea 打包jar 并放到集群上运行 在开始之前注意前提,当前项目的scala的版本要和集群上的scala一致 我已经创建好一个wordCount的flink项目 注意项目的po ...
- MR程序本地调试,提交到集群运行
在本地调试,提交到集群上运行. 在本地程序中的Configuration中添加如下配置: Configuration conf = new Configuration(); conf.set(&quo ...
- 编写hadoop程序并打成jar包上传到hadoop集群运行
准备工作: 1. hadoop集群(我用的是hadoop-2.7.3版本),这里hadoop有两种:1是编译好的hadoop-2.7.3:2是源代码hadoop-2.7.3-src: 2. 自己的机器 ...
- Hadoop集群运行JNI程序
要在Hadoop集群运行上运行JNI程序,首先要在单机上调试程序直到可以正确运行JNI程序,之后移植到Hadoop集群就是水到渠成的事情. Hadoop运行程序的方式是通过jar包,所以我们需要将所有 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:安装zookeeper集群
实验目的 了解zookeeper的概念和原理 学会安装zookeeper集群并验证 掌握zookeeper命令使用 实验原理 1.Zookeeper介绍 ZooKeeper是一个分布式的,开放源码的分 ...
- hadoop一代集群运行代码案例
hadoop一代集群运行代码案例 集群 一个 master,两个slave,IP分别是192.168.1.2.192.168.1.3.192.168.1.4 hadoop版 ...
随机推荐
- mybatis四大接口之 StatementHandler
1. 继承结构 StatementHandler:顶层接口 BaseStatementHandler : 实现顶层接口的抽象类,实现了部分接口,并定义了一个抽象方法 SimpleStatementHa ...
- tkinter之Frame
tkinter的Frame即容器,在容器内部好像不能再嵌套一个Frame.
- 副本集mongodb 无缘无故 cpu异常
mondb 服务器故障 主从复制集 主: 192.168.1.106从: 192.168.1.100仲裁:192.168.1.102 os版本:CentOS Linux release 7.3 ...
- 【并发】2、AtomicReferenceFieldUpdater初体验
对于volatile对象的原子更新 AtomicReferenceFieldUpdater这个对象进行原子更新的时候,外部操作对象只能是public,因为外部访问不到private对象,但是在内内部确 ...
- 关于a标签的onclick与href的执行顺序
onclick的事件被先执行,其次是href中定义的(页面跳转或者javascript), 同时存在两个定义的时候(onclick与href都定义了),如果想阻止href的动作,在onclick必须加 ...
- opencv实现正交匹配追踪算法OMP
//dic: 字典矩阵: //signal :待重构信号(一次只能重构一个信号,即一个向量) //min_residual: 最小残差 //sparsity:稀疏度 //coe:重构系数 //atom ...
- Nginx配置SSL自签名证书
生成自签名SSL证书 生成RSA密钥(过程需要设置一个密码,记住这个密码) $ openssl genrsa -des3 -out domain.key 1024 拷贝一个不需要输入密码的密钥文件 $ ...
- tabs高度自适应方法
1.去掉easyui-tabs类属性,改为id=tabs 2.用js控制高度
- JavaScript -- Anchor
-----052-Anchor.html----- <!DOCTYPE html> <html> <head> <meta http-equiv=" ...
- 【Java初探实例篇01】——Java语言基础
示例系列,将对每节知识辅以实际代码示例,通过代码实际编写,来深入学习和巩固学习的知识点. IDE:intellij IDEA: 语言:Java 本次示例:Java语言基础知识的应用. 创建包day_4 ...