matlib实现梯度下降法
样本文件下载:ex2Data.zip
ex2x.dat文件中是一些2-8岁孩子的年龄。
ex2y.dat文件中是这些孩子相对应的体重。
我们尝试用批量梯度下降法,随机梯度下降法和小批量梯度下降法来对这些数据进行线性回归,线性回归原理在:http://www.cnblogs.com/mikewolf2002/p/7560748.html
1.批量梯度下降法(BGD)
BGD.m代码:


clear all; close all; clc;
x = load('ex2x.dat'); %装入样本输入特征数据到x,年龄
y = load('ex2y.dat'); %装入样本输出结果数据到y,身高
figure('name','线性回归-批量梯度下降法');
plot(x,y,'o') %把样本在二维坐标上画出来
xlabel('年龄') %x轴说明
ylabel('身高') %y轴说明 m = length(y); % 样本数目
x = [ones(m, 1), x]; % 输入特征增加一列,x0=1
theta = zeros(size(x(1,:)))'; % 初始化theta MAX_ITR = 1500;%最大迭代数目
alpha = 0.07; %学习率
i = 0;
while(i<MAX_ITR)
grad = (1/m).* x' * ((x * theta) - y);%求出梯度
theta = theta - alpha .* grad;%更新theta
if(i>2)
delta = old_theta-theta;
delta_v = delta.*delta;
if(delta_v<0.000000000000001)%如果两次theta的内积变化很小,退出迭代
break;
end
end
old_theta = theta;
i=i+1;
end
i
theta
predict1 = [1, 3.5] *theta
predict2 = [1, 7] *theta
hold on
plot(x(:,2), x*theta, '-') % x现在是一个2列的矩阵
legend('训练数据', '线性回归')%标记每个数据设置
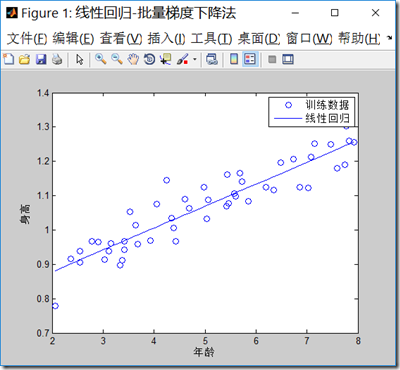
程序输结果如下:迭代次数达到了上限1500次,最后梯度下降法求解的theta值为\([0.7502,0.0639]^T\),两个预测值3.5岁,预测身高为0.9737米,7岁预测为1.1973米。
注意学习率的选择很重要,如果选择太大,可能不能得到收敛的\(\theta\)值。
i =
1500
theta =
0.7502
0.0639
predict1 =
0.9737
predict2 =
1.1973
2.随机梯度下降法
sgd.m代码如下,注意最大迭代次数增加到了15000,1500次迭代不能得到收敛的点,可见随机梯度下降法,虽然计算梯度时候,工作量减小,但是因为不是最佳的梯度下降方向,可能会使得迭代次数增加:
clear all; close all; clc;
x = load('ex2x.dat');
y = load('ex2y.dat');
figure('name','线性回归-随机梯度下降法');
plot(x,y,'o')
xlabel('年龄') %x轴说明
ylabel('身高') %y轴说明
m = length(y); % 样本数目
x = [ones(m, 1), x]; % 输入特征增加一列
theta = zeros(size(x(1,:)))';%初始化theta MAX_ITR = 15000;%最大迭代数目
alpha = 0.01;%学习率
i = 0;
while(i<MAX_ITR)
%j = unidrnd(m);%产生一个最大值为m的随机正整数j,j为1到m之间
j = mod(i,m)+1;
%注意梯度的计算方式,每次只取一个样本数据,通过轮转的方式取到每一个样本。
grad = ((x(j,:)* theta) - y(j)).*x(j,:)';
theta = theta - alpha * grad;
if(i>2)
delta = old_theta-theta;
delta_v = delta.*delta;
if(delta_v<0.0000000000000000001)
break;
end
end
old_theta = theta;
i=i+1;
end
i
theta
predict1 = [1, 3.5] *theta
predict2 = [1, 7] *theta
hold on
plot(x(:,2), x*theta, '-')
legend('训练数据', '线性回归')
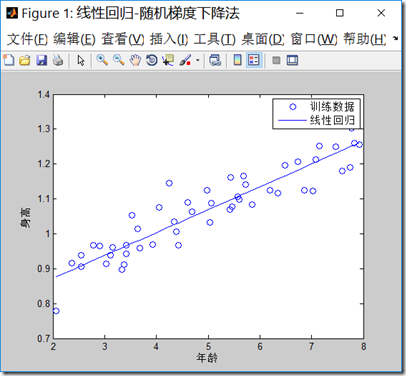
程序结果输出如下:
i =
15000
theta =
0.7406
0.0657
predict1 =
0.9704
predict2 =
1.2001
3.小批量梯度下降法
mbgd.m代码如下,程序中批量的样本数目,我们选择5:
clear all; close all; clc;
x = load('ex2x.dat');
y = load('ex2y.dat');
figure('name','线性回归-小批量梯度下降法')
plot(x,y,'o')
xlabel('年龄') %x轴说明
ylabel('身高') %y轴说明
m = length(y); % 样本数目 x = [ones(m, 1), x]; % 输入特征增加一列
theta = zeros(size(x(1,:)))'; %初始化theta MAX_ITR = 15000;%最大迭代数目
alpha = 0.01;%学习率
i = 0;
b = 5; %小批量的数目
while(i<MAX_ITR)
j = mod(i,m-b)+1;
%每次计算梯度时候,只考虑b个样本数据
grad = (1/b).*x(j:j+b,:)'*((x(j:j+b,:)* theta) - y(j:j+b));
theta = theta - alpha * grad;
if(i>2)
delta = old_theta-theta;
delta_v = delta.*delta;
if(delta_v<0.0000000000000000001)
break;
end
end
old_theta = theta;
i=i+b;
end
i
theta
predict1 = [1, 3.5] *theta
predict2 = [1, 7] *theta
hold on
plot(x(:,2), x*theta, '-')
legend('训练数据', '线性回归')
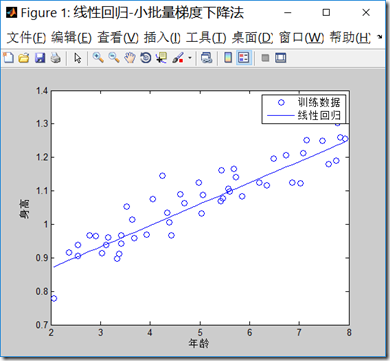
程序的输出结果:
i =
15000
theta =
0.7418
0.0637
predict1 =
0.9647
predict2 =
1.1875
matlib实现梯度下降法的更多相关文章
- matlib实现梯度下降法(序一)
数据来源:http://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant 数据描述: 有四个输入特征,这些数据来自电厂,这四个特征和 ...
- [Machine Learning] 梯度下降法的三种形式BGD、SGD以及MBGD
在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度下降法还具体包含有三种不同的形式,它们也各自有着不同的优缺点. 下面我们以线性回归算法来对三种梯度下降法进行比较. ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
- 一种利用 Cumulative Penalty 训练 L1 正则 Log-linear 模型的随机梯度下降法
Log-Linear 模型(也叫做最大熵模型)是 NLP 领域中使用最为广泛的模型之一,其训练常采用最大似然准则,且为防止过拟合,往往在目标函数中加入(可以产生稀疏性的) L1 正则.但对于这种带 L ...
- coursera机器学习笔记-机器学习概论,梯度下降法
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- 重新发现梯度下降法--backtracking line search
一直以为梯度下降很简单的,结果最近发现我写的一个梯度下降特别慢,后来终于找到原因:step size的选择很关键,有一种叫backtracking line search的梯度下降法就非常高效,该算法 ...
- 梯度下降法VS随机梯度下降法 (Python的实现)
# -*- coding: cp936 -*- import numpy as np from scipy import stats import matplotlib.pyplot as plt # ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- 理解梯度下降法(Gradient Decent)
1. 什么是梯度下降法? 梯度下降法(Gradient Decent)是一种常用的最优化方法,是求解无约束问题最古老也是最常用的方法之一.也被称之为最速下降法.梯度下降法在机器学习中十分常见,多用 ...
随机推荐
- React Native Android启动白屏的一种解决方案下
实现思路 思路大流程: 1.APP启动的时候控制ReactActivity从而显示启动屏. 2.编写原生模块,提供一个关闭启动屏的公共接口. 3.在js的适当位置(一般是程序初始化工作完成后)调用上述 ...
- MySQL数据库之索引
1 引言 在没有索引的情况下,如果要寻找特定行,数据库可能要遍历整个数据库,使用索引后,数据库可以根据索引找出这一行,极大提高查询效率.本文是对MySQL数据库中索引使用的总结. 2 索引简介 索引是 ...
- 基于CommonsCollections4的Gadget分析
基于CommonsCollections4的Gadget分析 Author:Welkin 0x1 背景及概要 随着Java应用的推广和普及,Java安全问题越来越被人们重视,纵观近些年来的Java安全 ...
- 1722 最优乘车 1997年NOI全国竞赛
题目描述 Description H城是一个旅游胜地,每年都有成千上万的人前来观光.为方便游客,巴士公司在各个旅游景点及宾馆,饭店等地都设置了巴士站并开通了一些单程巴上线路.每条单程巴士线路从某个巴士 ...
- NOIp模拟赛 巨神兵(状压DP 容斥)
\(Description\) 给定\(n\)个点\(m\)条边的有向图,求有多少个边集的子集,构成的图没有环. \(n\leq17\). \(Solution\) 问题也等价于,用不同的边集构造DA ...
- [Java]Get与Post,客户端跳转与服务器端跳转
http://www.thinksaas.cn/group/topic/133101/ 虽然说get 与post 问题很老套了,但是作为web 开发人员来说对于这个的理解确实很有必要,其实说到get ...
- CentOS 7下宿主机使用virsh console访问KVM的设置
在CentOS 6下要实现宿主机使用virsh console访问KVM可以说是非常麻烦,但这一问题在CentOS 7已经解决了,只需要两条命令在KVM下即可实现. 1.在KVM(客户机)下开机启动并 ...
- MikroTik RouterOS 5.x使用HunterTik 2.3.1进行破解
一.加载光驱: 二.一路回车: 三.说明: 1.可以不安装Debian内核,但如果在无缝升级到6.6的版本,此项就一定要选择. 2.6版本的破解必须小于等于1G的空间,不然无法破解成功,亲测有效,如果 ...
- [Asp.net core 2.0]Ueditor 图片上传
摘要 在项目中要用到富文本编辑器,包含上传图片,插入视频等功能.但ueditor只有.net版本,没有支持core.那么上传等接口就需要自己实现了. 一个例子 首先去百度ueditor官网下载简化版的 ...
- ASP.NET Web API实践系列11,如何设计出优秀的API
本篇摘自:InfoQ的微信公众号 在设计API的时候考虑的问题包括:API所使用的传输协议.支持的消息格式.接口的控制.名称.关联.次序,等等.我们很难始终作出正确的决策,很可能是在多次犯错之后,并从 ...