python整理1992、2009国家标准学科分类及代码数据并存入MySQL数据库
文件内容
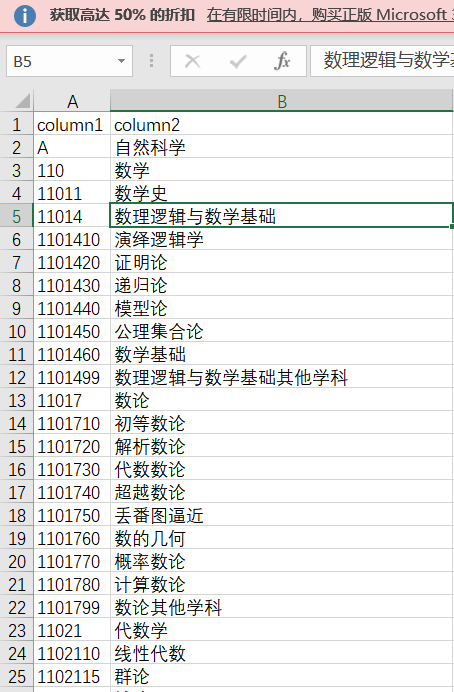
处理结果
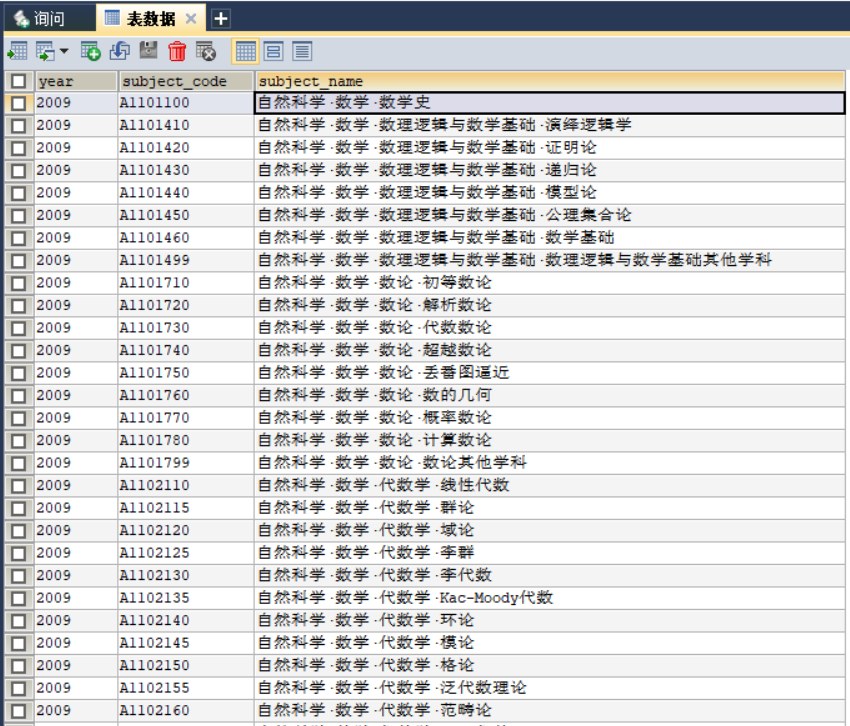
代码
1 import pandas as pd
2 import pymysql
3
4
5 def get_subject_1992():
6 res={}
7 the_former_code = ""
8 layer1_code = "" # 一位
9 layer1_name = ""
10 layer2_code = "" # 三位
11 layer2_name = "" # 三位
12 layer3_code = "" # 五位
13 layer3_name = ""
14 layer4_code = "" # 七位
15 layer4_name = "" # 七位
16 df = pd.read_excel("std_subject_1992.xlsx")
17 for i in range(len(df.values)):
18 item=df.values[i]
19 # print(item[0],item[1])
20 if (len(str(item[0])) == 1):
21 layer1_code = str(item[0])
22 layer1_name = item[1]
23 # print(layer1_code,layer1_name)
24 if (len(str(item[0])) == 3):
25 layer2_code = str(item[0])
26 layer2_name = item[1]
27 # print(layer2_code, layer2_name)
28 if (len(str(item[0])) == 5):
29 layer3_code = str(item[0])
30 layer3_name = item[1]
31 if(i!=(len(df.values)-1)):
32 if(len(str(df.values[i+1][0]))!=7):
33 # print(layer1_code + layer3_code,layer1_name + "·" + layer2_name + "·" +layer3_name)
34 res.update({layer1_code + layer3_code+"00":layer1_name + "·" + layer2_name + "·" +layer3_name})
35 # print(layer3_code, layer3_name)
36 if (len(str(item[0])) == 6):
37 layer4_code = str(item[0])+"0"
38 layer4_name = item[1]
39 # print(layer4_code, layer4_name)
40 if (layer4_code[:5] == layer3_code):
41 # print(layer1_code + layer4_code,layer1_name + "·" + layer2_name + "·" + layer3_name + "·" + layer4_name)
42 res.update({layer1_code + layer4_code:layer1_name + "·" + layer2_name + "·" + layer3_name + "·" + layer4_name})
43 if (len(str(item[0])) == 7):
44 layer4_code = str(item[0])
45 layer4_name = item[1]
46 # print(layer4_code, layer4_name)
47 if (layer4_code[:5] == layer3_code):
48 # print(layer1_code + layer4_code,layer1_name + "·" + layer2_name + "·" + layer3_name + "·" + layer4_name)
49 res.update({layer1_code + layer4_code:layer1_name + "·" + layer2_name + "·" + layer3_name + "·" + layer4_name})
50 return res
51
52 """
53 ---------------------------------------------------------------------------------------
54 """
55 def get_subject_2009():
56 res={}
57 the_former_code = ""
58 layer1_code = "" # 一位
59 layer1_name = ""
60 layer2_code = "" # 三位
61 layer2_name = "" # 三位
62 layer3_code = "" # 五位
63 layer3_name = ""
64 layer4_code = "" # 七位
65 layer4_name = "" # 七位
66 df = pd.read_excel("std_subject_2009.xlsx")
67 for i in range(len(df.values)):
68 item=df.values[i]
69 # print(item[0],item[1])
70 if (len(str(item[0])) == 1):
71 layer1_code = str(item[0])
72 layer1_name = item[1]
73 # print(layer1_code,layer1_name)
74 if (len(str(item[0])) == 3):
75 layer2_code = str(item[0])
76 layer2_name = item[1]
77 # print(layer2_code, layer2_name)
78 if (len(str(item[0])) == 5):
79 layer3_code = str(item[0])
80 layer3_name = item[1]
81 if(i!=(len(df.values)-1)):
82 if(len(str(df.values[i+1][0]))!=7):
83 # print(layer1_code + layer3_code,layer1_name + "·" + layer2_name + "·" +layer3_name)
84 res.update({layer1_code + layer3_code+"00":layer1_name + "·" + layer2_name + "·" +layer3_name})
85 if (len(str(item[0])) == 7):
86 layer4_code = str(item[0])
87 layer4_name = item[1]
88 # print(layer4_code, layer4_name)
89 if (layer4_code[:5] == layer3_code):
90 # print(layer1_code + layer4_code,layer1_name + "·" + layer2_name + "·" + layer3_name + "·" + layer4_name)
91 res.update({layer1_code + layer4_code:layer1_name + "·" + layer2_name + "·" + layer3_name + "·" + layer4_name})
92 return res
93 """
94 ---------------------------------------------------------------------------------------------------------------
95 """
96 def get_conn():
97 """
98 :return: 连接,游标
99 """
100 # 创建连接
101 conn = pymysql.connect(host="127.0.0.1",
102 user="root",
103 password="000429",
104 db="data_cleaning",
105 charset="utf8")
106 # 创建游标
107 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
108 return conn, cursor
109
110 def close_conn(conn, cursor):
111 if cursor:
112 cursor.close()
113 if conn:
114 conn.close()
115
116
117 def into_mysql():
118 global conn, cursor
119 res=get_subject_2009()
120 for k,v in res.items():
121 print(k,v)
122 try:
123 conn,cursor=get_conn()
124 SQL="insert into std_subject_2009 (year,subject_code,subject_name) values (2009,'"+k+"','"+v+"')"
125 cursor.execute(SQL)
126 conn.commit()
127 except:
128 print(k,v+" 插入失败!")
129 conn,cursor.close()
130 return None
131 if __name__ == '__main__':
132 into_mysql()
获取标准学科分类表 请关注公众号【靠谱杨阅读人生】回复【学科】获取
python整理1992、2009国家标准学科分类及代码数据并存入MySQL数据库的更多相关文章
- python爬虫学习(2)__抓取糗百段子,与存入mysql数据库
import pymysql import requests from bs4 import BeautifulSoup#pymysql链接数据库 conn=pymysql.connect(host= ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- 用Python获取沪深两市上市公司股票信息,提取创近10天股价新高的、停牌的、复牌不超过一天或者新发行的股票,并存入mysql数据库
#该脚本可以提取沪深两市上市公司股票信息,并按以下信息分类:(1)当天股价创近10个交易日新高的股票:(2)停牌的股票:(3)复牌不超过一个交易日或者新发行的股票 #将分类后的股票及其信息(股价新高. ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫:爬取易迅网价格信息,并写入Mysql数据库
本程序涉及以下方面知识: 1.python链接mysql数据库:http://www.cnblogs.com/miranda-tang/p/5523431.html 2.爬取中文网站以及各种乱码处 ...
- Python scrapy爬虫数据保存到MySQL数据库
除将爬取到的信息写入文件中之外,程序也可通过修改 Pipeline 文件将数据保存到数据库中.为了使用数据库来保存爬取到的信息,在 MySQL 的 python 数据库中执行如下 SQL 语句来创建 ...
- 【原创】python爬虫获取网站数据并存入本地数据库
#coding=utf-8 import urllib import re import MySQLdb dbnumber = MySQLdb.connect('localhost', 'root', ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- python爬取疫情数据存入MySQL数据库
import requests from bs4 import BeautifulSoup import json import time from pymysql import * def mes( ...
- 使用Python将Excel中的数据导入到MySQL
使用Python将Excel中的数据导入到MySQL 工具 Python 2.7 xlrd MySQLdb 安装 Python 对于不同的系统安装方式不同,Windows平台有exe安装包,Ubunt ...
随机推荐
- 我的小程序之旅三:微信小程序登录流程设计
登录时序图 获取小程序的AppID和AppSecret 一.微信获取登录用户的openId 1.wx.login() { "code": "192038921jkjKHW ...
- CDN 加速原理
=> CDN 加速原理 HTTP 请求流程说明: 用户在浏览器输入要访问的网站域名,向本地 DNS 发起域名解析请求. 域名解析的请求被发往网站授权 DNS 服务器. 网站 DNS 服务器解析发 ...
- python selenium list index out of range
常见错误原因 常见错误原因 其他错误原因 场景 使用selenium循环打开并跳转到新的网页,然后关闭新的窗口,然后回到原来窗口,这时候获取list中的值,报错: list index out of ...
- AI 让观众成为 3D 版《老友记》的导演了?
<老友记>上线 3D 版了? 允许用户旋转镜头,且从近景切换到全景观看故事? 今年出炉的 3D 方向 AI 项目 SitCom3D,能够自动补齐<老友记>原剧中的三维拍摄空间, ...
- 【转载】大数据OLAP系统--开源组件方案对比
开源大数据OLAP组件,可以分为MOLAP和ROLAP两类.ROLAP中又可细分为MPP数据库和SQL引擎两类.对于SQL引擎又可以再细分为基于MPP架构的SQL引擎和基于通用计算框架的SQL引擎: ...
- BeanShell Sample 如何使用?
一 引入: eanShell Sample主要用于生成一些逻辑复杂的数据,例如用于加解密数据: **每次调用前重置bsh.Interpreter:每个BeanShell副本都有自己的解释器副本(每个线 ...
- 万字博文让我们携手一起走进bs4的世界【python Beautifulsoup】bs4入门 find()与find_all()
目录 Beautiful Soup BeautifulSoup类的基本元素 1.Tag的name 2.Tag的attrs(属性) 3.Tag的NavigableString 二.遍历文档树 下行遍历 ...
- 摆脱鼠标系列 - 打开微信(Alt+V) - 打开双核浏览器(Alt+S) - HotkeyP
摆脱鼠标系列 - 打开微信(Alt+V) - 打开双核浏览器(Alt+S) - HotkeyP 新定义了两个快捷键 这两个比较常用
- vscode 格式化 vue 等文件的 配置 eslint vetur prettier Beautify
需求 自动格式化需求 多行回车 合并一行,去分号 最后一个逗号,自动删除,符合eslint 结果 虽然能用了,但是 百度好几个方案,也不知道哪个对哪个,太忙没时间弄了. 配置文件记录 eslint 得 ...
- IntentGC-A Scalable Graph Convolution Framework Fusing Heterogeneous Information for Recommendation-KDD19
一.摘要 网络嵌入的显著进步导致了最先进的推荐算法.然而,网站上的用户-物品交互(即显式偏好)的稀疏性仍然是预测用户行为的一个很大的挑战. 虽然,已经有研究利用了一些辅助信息(如用户间的社会关系)来解 ...