【预训练语言模型】BERT原理解析、常见问题和微调实战
一、BERT原理
1、概述
2、BERT模型
- pre-training 阶段,BERT 在无标记的数据上进行无监督学习;
- fine-tuning 阶段,BERT利用预训练的参数初始化模型,并利用下游任务标记好的数据进行有监督学习,并对所有参数进行微调。
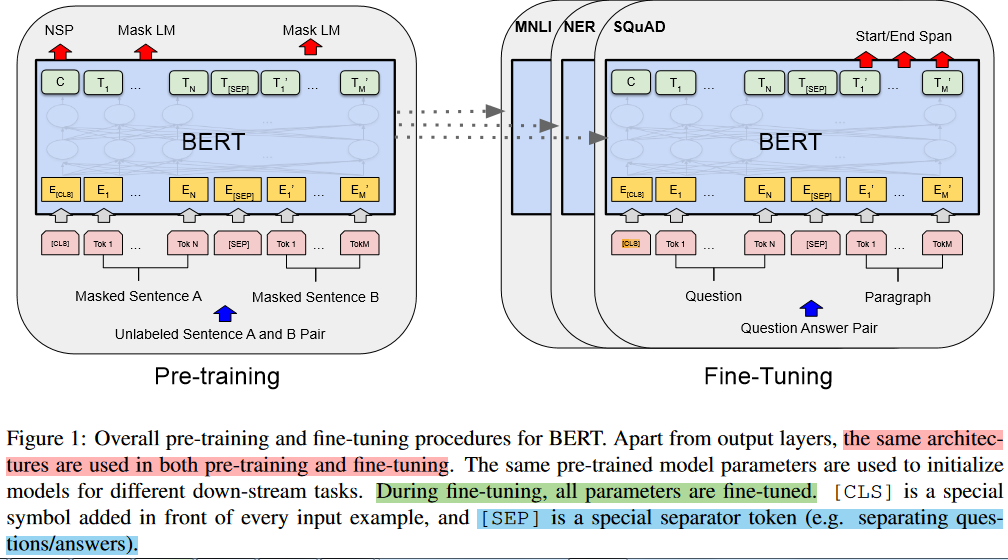
2.1、模型架构
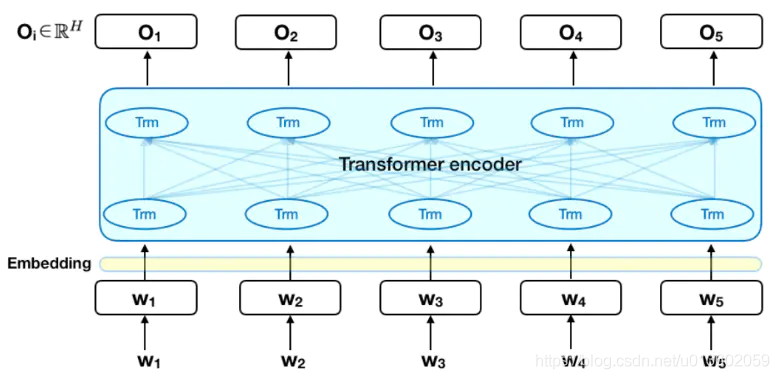
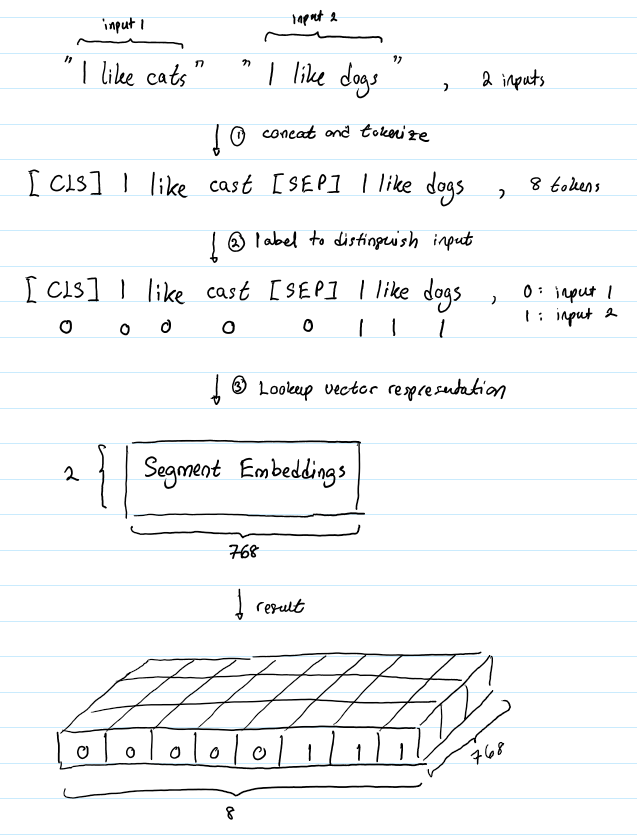
2.2、输入
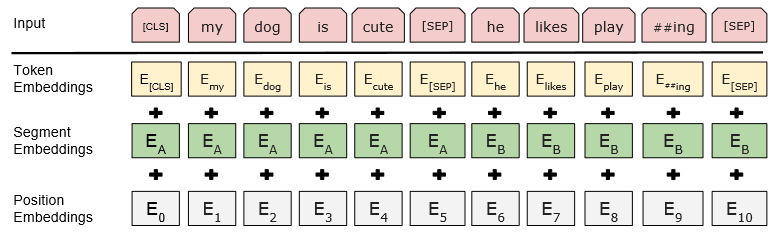
- Token Embeddings 采用的 WordPiece Tokenizer进行分词,词表数量为30000。每个 sequence 会以一个特殊的 classification token [CLS] 开始,同时这也会作为分类任务的输出;句子间会以 special seperator token [SEP] 进行分割。
- Segment Embedding也可以用来分割句子,但主要用来区分句子对。Embedding A 和 Embedding B 分别代表左右句子,如果是普通的句子就直接用 Embedding A。
- Position Embedding 是用来给词元Token定位的,学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。
WordPiece Tokenizer分词器:采用 BPE 双字节编码,在单词进行拆分,比如 “loved” “loving” ”loves“ 会拆分成 “lov”,“ed”,“ing”,“es”。
2.3、预训练Pre-training
2.3.1、任务一:Masked LM

- 80% 的 [MASK] token 会继续保持 [MASK];—my dog is [MASK]
- 10% 的 [MASK] token 会被随机的一个单词取代;my dog is apple
- 10% 的 [MASK] token 会保持原单词不变(但是还是要预测)my dog is hairy
- 在 encoder 的输出上添加一个前馈神经网络,将其转换为词汇的维度
- softmax 计算词汇表中每个单词的概率
2.3.2、任务二:Next Sentence Prediction
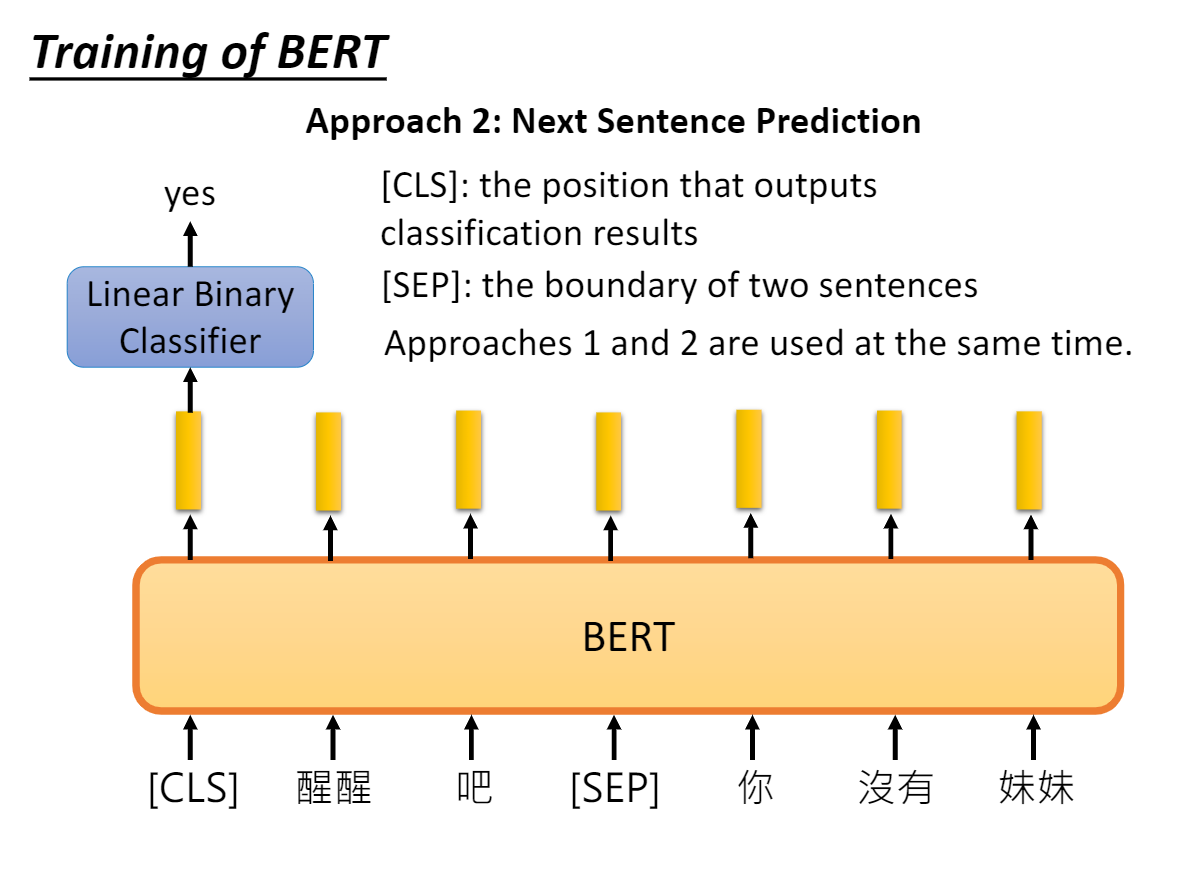
- B有一半的几率是A的下一句,即正例;
- B有一半的几率是随机取一个句子作为负例。
2.4、微调Fine-tuning

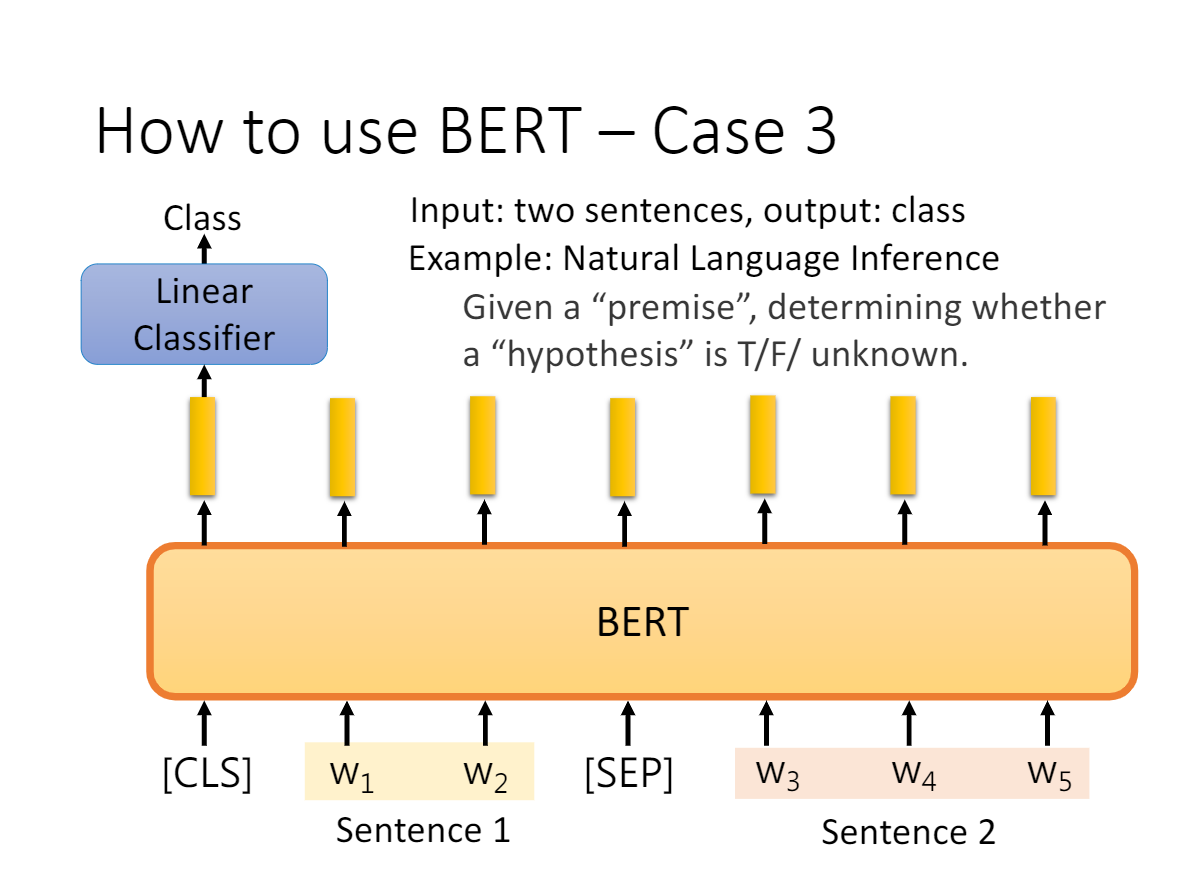
- a、b 是 sentence-level 级别的任务,类似句子分类,情感分析等等,输入句子或句子对,在 [CLS] 位置接入 Softmax 输出 Label;
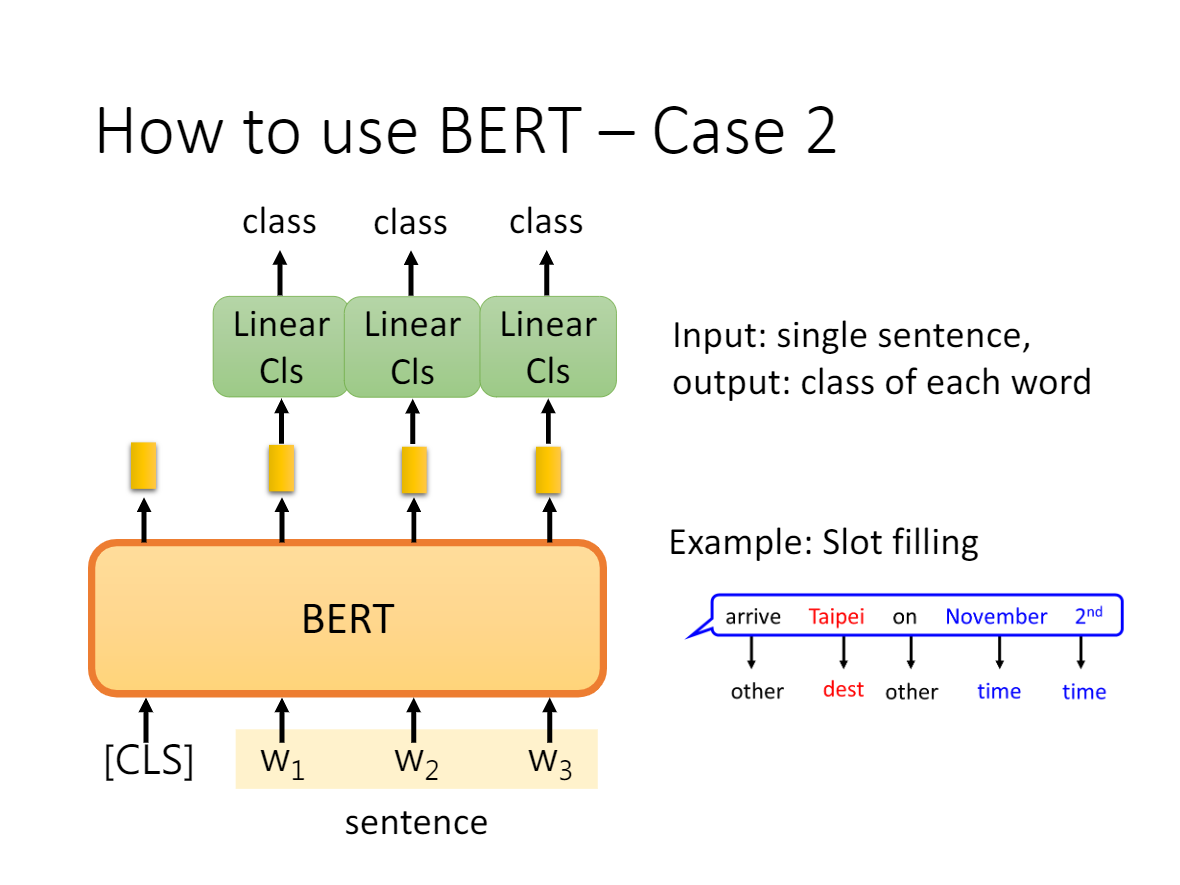
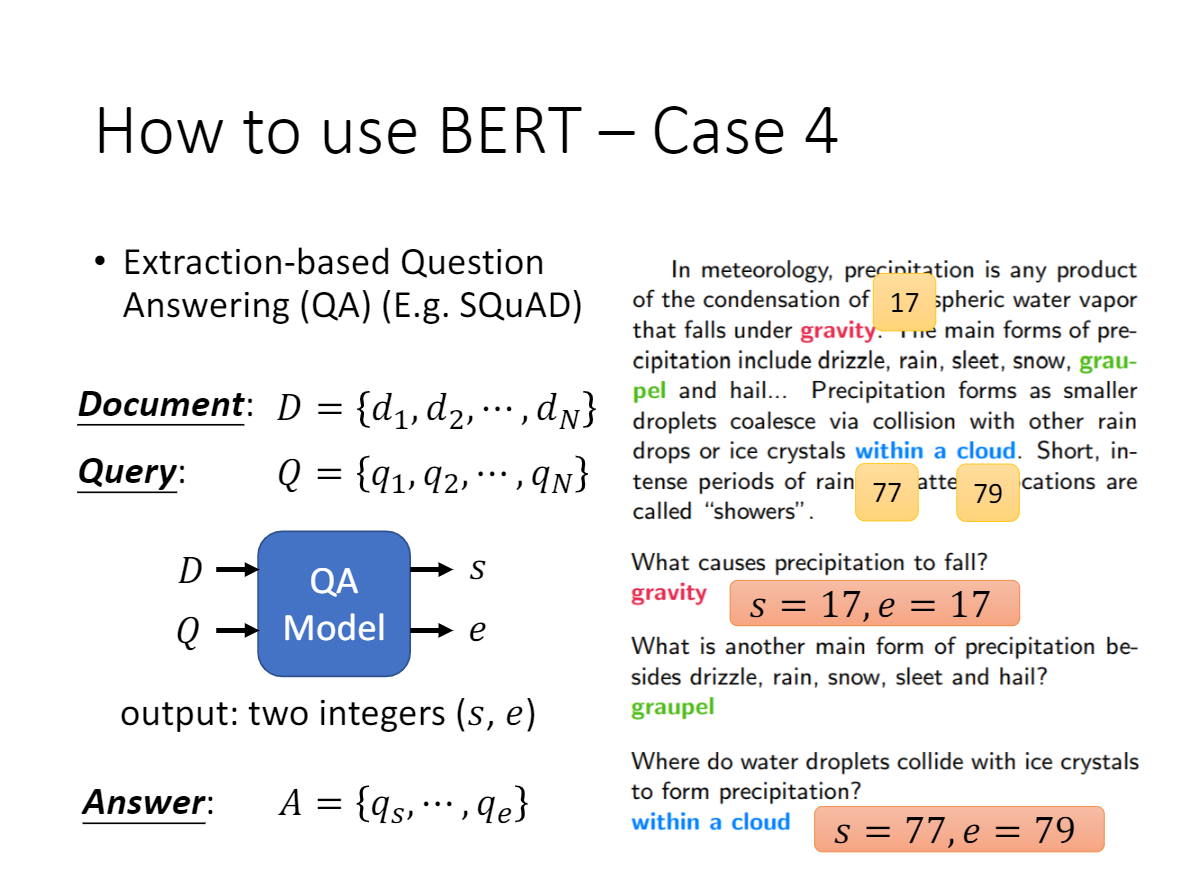
- c是token-level级别的任务,比如 QA 问题,输入问题和段落,在 Paragraph 对应输出的 hidden vector 后接上两个 Softmax 层,分别训练出 Span 的 Start index 和 End index(连续的 Span)作为 Question 的答案;
- d也是token-level级别的任务,比如命名实体识别问题,接上 Softmax 层即可输出具体的分类。
例如:
在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
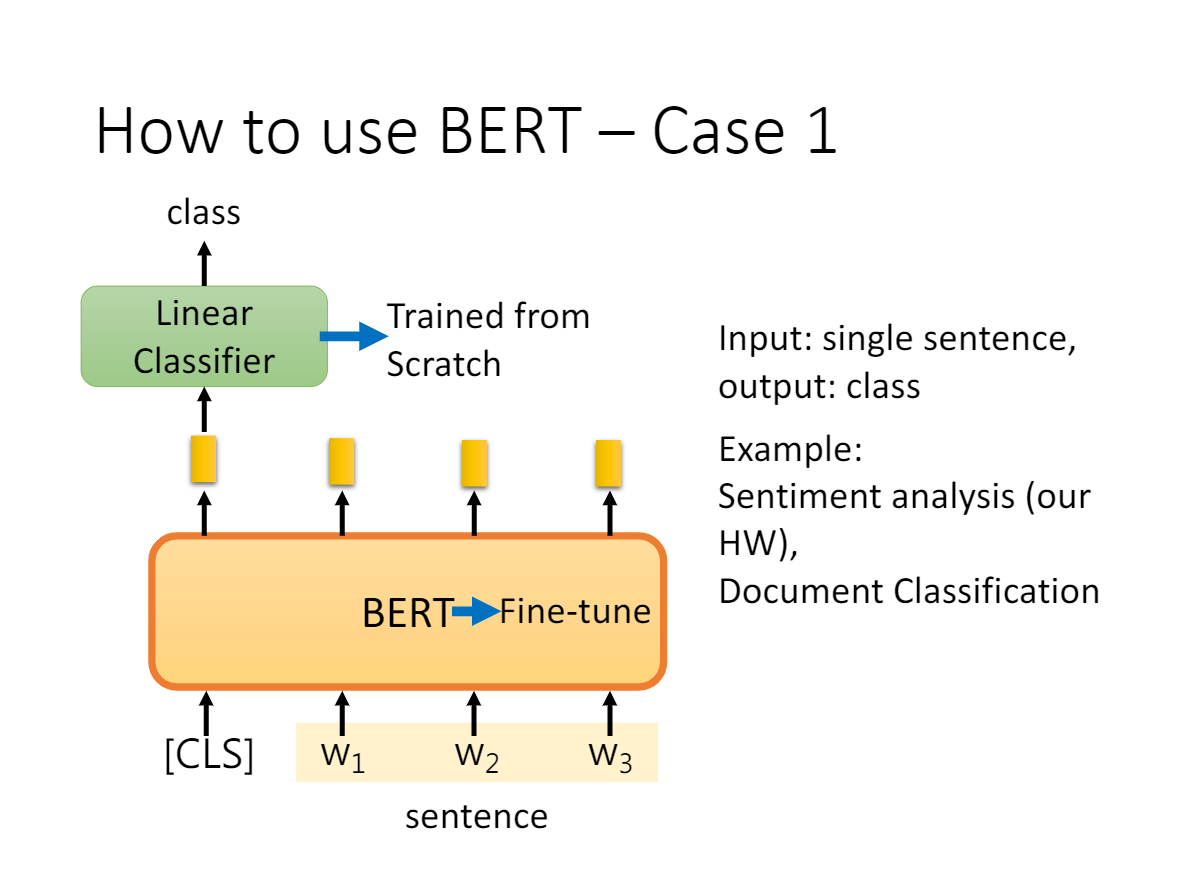
在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
3. 结论
- BERT的Transformer Encoder的Self-Attention结构能较好地建模上下文,而且在经过在语料上预训练后,能获取到输入文本较优质的语义表征。
- BERT的MLP和NSP联合训练,让其能适配下游多任务(Token级别和句子级别)的迁移学习
- [MASK] token在推理时不会出现,因此训练时用过多的[MASK]会影响模型表现(需要让下游任务去适配预训练语言模型,而不是让预训练语言模型主动针对下游任务做优化)
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(BERT对语料的利用低。而GPT对语料的利用率更高,它几乎能利用句子的每个token);
- BERT的上下文长度固定为512,输入过长需要阶段(对长文本不友好)
二、BERT答疑
1、三个Embedding怎么来的
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
from transformers import AutoTokenizer checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
tokenized_sentences_2 = tokenizer(raw_datasets["train"]["sentence2"])
nputs = tokenizer("This is the first sentence.", "This is the second one.") inputs
结果:input_ids为token ids, token_type_ids用于区分两个toke序列(对应segment embeddings)
{'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
反tokenize
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
结果
['[CLS]',
'this',
'is',
'the',
'first',
'sentence',
'.',
'[SEP]',
'this',
'is',
'the',
'second',
'one',
'.',
'[SEP]']
2、不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
3、为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
4、为什么BERT在第一句前会加一个[CLS]标志?

BERT在第一句前会加一个CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义
5、Self-Attention 的时间复杂度是怎么计算的?
6、Transformer在哪里做了权重共享,为什么可以做权重共享?
7、BERT非线性的来源在哪里?
8. BERT参数量
- BERT-BASE-Uncase (L=12, H=768, A=12, Total Parameters=110M)
- BERT-LARGE-Uncase (L=24, H=1024, A=16, Total Parameters=340M)
三、BERT调包和微调
- 1. 所有的句子必须被填充或截断成一个固定的长度。
- 2. 最大的句子长度是512个tokens。
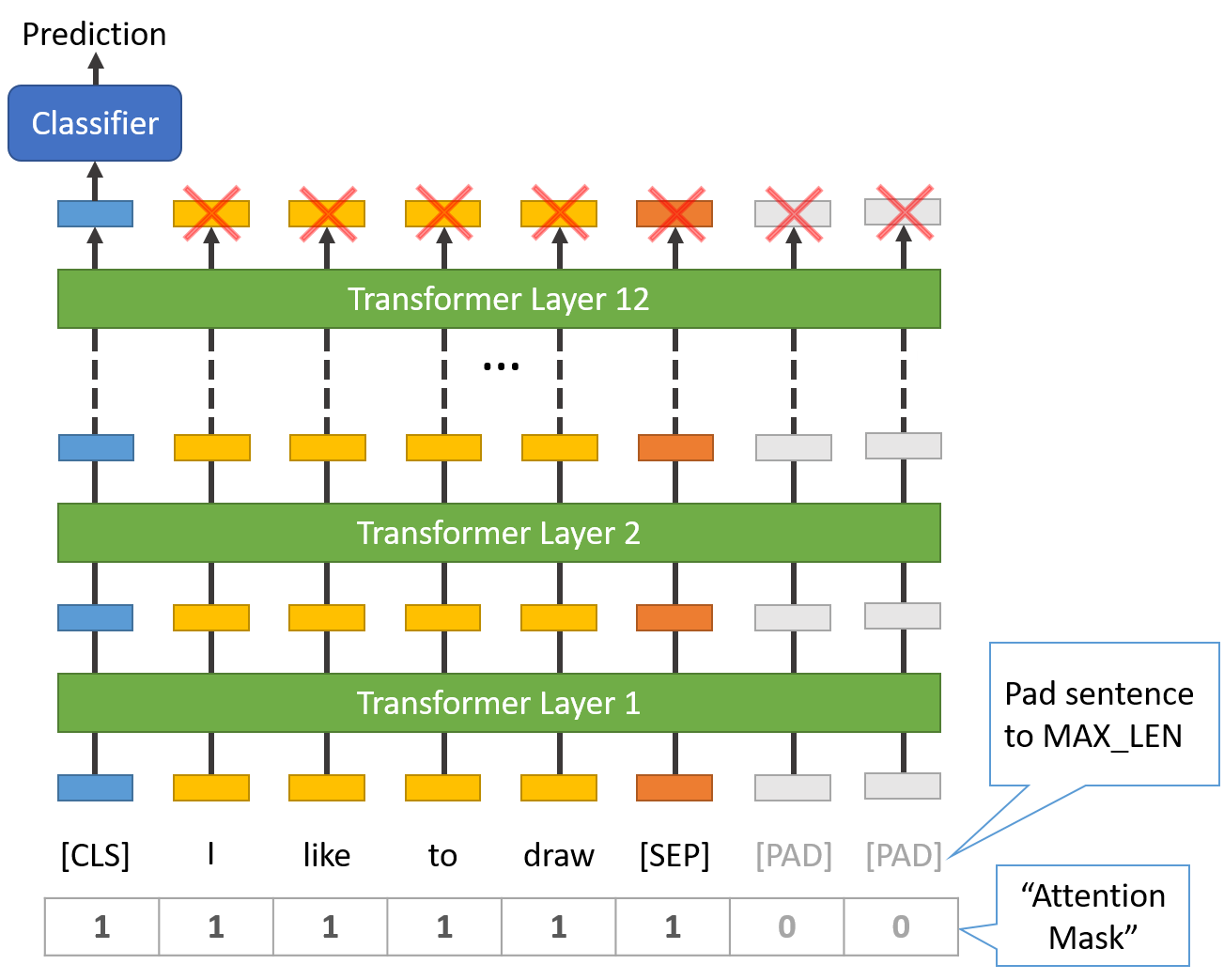
- 将句子分割成token。
- 添加特殊的[CLS]和[SEP]标记。
- 将这些标记映射到它们的ID上。
- 把所有的句子都垫上或截断成相同的长度。
- 创建注意力Masl,明确区分真实 token 和[PAD]token。
- BertModel
- BertForPreTraining
- BertForMaskedLM
- BertForNextSentencePrediction(下句预测)
- BertForSequenceClassification - 我们将使用的那个。
- BertForTokenClassification
- BertForQuestionAnswering
import torch
from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification # Same as before
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This course is amazing!",
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt") # This is new
batch["labels"] = torch.tensor([1, 1]) optimizer = AdamW(model.parameters())
loss = model(**batch).loss
loss.backward()
optimizer.step()
代码源自huggingface Transformer库教程
参考
- 用huggingface.transformers在文本分类任务(单任务和多任务场景下)上微调预训练模型https://blog.csdn.net/PolarisRisingWar/article/details/127365675
- 处理数据 - Hugging Face NLP Course
- 比赛:Datawhale零基础入门NLP赛事 - Task5 基于深度学习的文本分类https://tianchi.aliyun.com/notebook/118258
【预训练语言模型】BERT原理解析、常见问题和微调实战的更多相关文章
- 学习AI之NLP后对预训练语言模型——心得体会总结
一.学习NLP背景介绍: 从2019年4月份开始跟着华为云ModelArts实战营同学们一起进行了6期关于图像深度学习的学习,初步了解了关于图像标注.图像分类.物体检测,图像都目标物体检测等 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
- 预训练语言模型整理(ELMo/GPT/BERT...)
目录 简介 预训练任务简介 自回归语言模型 自编码语言模型 预训练模型的简介与对比 ELMo 细节 ELMo的下游使用 GPT/GPT2 GPT 细节 微调 GPT2 优缺点 BERT BERT的预训 ...
- NLP中的预训练语言模型(五)—— ELECTRA
这是一篇还在双盲审的论文,不过看了之后感觉作者真的是很有创新能力,ELECTRA可以看作是开辟了一条新的预训练的道路,模型不但提高了计算效率,加快模型的收敛速度,而且在参数很小也表现的非常好. 论文: ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
- 知识增广的预训练语言模型K-BERT:将知识图谱作为训练语料
原创作者 | 杨健 论文标题: K-BERT: Enabling Language Representation with Knowledge Graph 收录会议: AAAI 论文链接: https ...
- 知识增强的预训练语言模型系列之KEPLER:如何针对上下文和知识图谱联合训练
原创作者 | 杨健 论文标题: KEPLER: A unified model for knowledge embedding and pre-trained language representat ...
- 【译】深度双向Transformer预训练【BERT第一作者分享】
目录 NLP中的预训练 语境表示 语境表示相关研究 存在的问题 BERT的解决方案 任务一:Masked LM 任务二:预测下一句 BERT 输入表示 模型结构--Transformer编码器 Tra ...
- NLP中的预训练语言模型(三)—— XL-Net和Transformer-XL
本篇带来XL-Net和它的基础结构Transformer-XL.在讲解XL-Net之前需要先了解Transformer-XL,Transformer-XL不属于预训练模型范畴,而是Transforme ...
- NLP中的预训练语言模型(二)—— Facebook的SpanBERT和RoBERTa
本篇带来Facebook的提出的两个预训练模型——SpanBERT和RoBERTa. 一,SpanBERT 论文:SpanBERT: Improving Pre-training by Represe ...
随机推荐
- 多路io复用epoll [补档-2023-07-20]
多路io- epoll 4-1简介 它是linux中内核实现io多路/转接复用的一个实现.(epoll不可跨平台,只能用于Linux)io多路转接是指在同一个操作里,同时监听多个输入输出源,在其中 ...
- 提升编码幸福感的秘密「GitHub 热点速览」
写代码是一个充满挑战的事情,在这段充满挑战的旅途中,我们都渴望找到那个提升幸福感的秘密.没准是更先进或是更快的工具,希望本期热点速递的开源项目,能给你带来启迪和乐趣,上菜! 第一个上场的是一款用 Ru ...
- html 图片地图
<html> <head> <title></title> </head> <body> <img src="8 ...
- Intel Arrow Lake处理器还是8+16 24核心:接口换LGA1851
Intel已经确认,将在今年内发布未来两代处理器Arrow Lake.Lunar Lake,其中前者将弥补Meteor Lake的不足,同时用于笔记本.桌面.服务器,现在它的核心规格流出了. 这份曝光 ...
- Vulkan学习苦旅06:创建渲染通道(VkRenderPass)
对于一个复杂的图形应用程序,需要多个过程的配合,以生成图像的各个部分.通常,各个过程间存在着依赖关系,例如某个过程生成的图像(输出)被另一个过程使用(作为此过程的输入).在Vulkan中,每个过程被称 ...
- Mysql切割字符串
我们常常会遇到需要处理字段中字符串的需求,包括切割.拼接以及搜索等等,在这里介绍几个常用的切割字符串的函数,首先我们在表格中加入我们的实验字段值:https://www.cnblogs.com/Yao ...
- Linux-expect(以交互形式输入命令,实现交互通信)
1.expect简介 expect是一种脚本语言,它能够代替人工实现与终端的交互,主要应用于执行命令和程序时,系统以交互形式要求输入指定字符串,实现交互通信. 安装命令: yum install ex ...
- ABC 306
前三题过水. D \(dp[i][j]\) 表示吃完前 \(i\) 个菜,胃的状况为 \(j\)(\(0\) 是健康,\(1\) 是不好)所获得的最大美味值. E 暴力的平衡树.用 multiset ...
- idea 报错: Unable to import maven project: See logs for details
错误再现: idea 工具日志: 1) No implementation for org.apache.maven.model.path.PathTranslator was bound. whil ...
- java 注解结合 spring aop 实现日志traceId唯一标识
MDC 的必要性 日志框架 日志框架成熟的也比较多: slf4j log4j logback log4j2 我们没有必要重复造轮子,一般是建议和 slf4j 进行整合,便于后期替换为其他框架. 日志的 ...