离线生成双语字幕,一键生成中英双语字幕,基于AI大模型,ModelScope

制作双语字幕的方案网上有很多,林林总总,不一而足。制作双语字幕的原理也极其简单,无非就是人声背景音分离、语音转文字、文字翻译,最后就是字幕文件的合并,但美中不足之处这些环节中需要接口api的参与,比如翻译字幕,那么有没有一种彻底离线的解决方案?让普通人也能一键制作双语字幕,成就一个人的字幕组?
人声背景音分离
如果视频不存在嘈杂的背景音,那么大多数情况下是不需要做人声和背景音分离的,但考虑到背景音可能会影响语音转文字的准确率,那么人声和背景音分离还是非常必要的,关于人声抽离,我们首先想到的解决方案当然是spleeter,但其实,阿里通义实验室开源的大模型完全不逊色于spleeter,它就是FRCRN语音降噪-单麦-16k,模型官方地址:
https://modelscope.cn/models/iic/speech_frcrn_ans_cirm_16k/summary
FRCRN语音降噪模型是基于频率循环 CRN (FRCRN) 新框架开发出来的。该框架是在卷积编-解码(Convolutional Encoder-Decoder)架构的基础上,通过进一步增加循环层获得的卷积循环编-解码(Convolutional Recurrent Encoder-Decoder)新型架构,可以明显改善卷积核的视野局限性,提升降噪模型对频率维度的特征表达,尤其是在频率长距离相关性表达上获得提升,可以在消除噪声的同时,对语音进行更针对性的辨识和保护。
需要注意的是该模型再Pytorch1.12上有bug,所以最好指定版本运行:
pip install pytorch==1.11 torchaudio torchvision -c pytorch
运行方式也很简单,通过pipeline调用即可:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
ans = pipeline(
Tasks.acoustic_noise_suppression,
model='damo/speech_frcrn_ans_cirm_16k')
result = ans(
'test.wav',
output_path='output.wav')
语音转文字 faster-whisper
成功分离出人声,接着要做的就是语音转文字,这里选择faster-whisper,faster-whisper 是 OpenAI Whisper 模型的重新实现,使用了 CTranslate2,这是一个用于 Transformer 模型的快速推理引擎。相比于 openai/whisper,faster-whisper 的实现速度提高了 4 倍,同时内存占用更少。此外,faster-whisper 还支持在 CPU 和 GPU 上进行 8 位量化,进一步提高了效率。
pip install faster-whisper
随后编写转写代码:
def convert_seconds_to_hms(seconds):
hours, remainder = divmod(seconds, 3600)
minutes, seconds = divmod(remainder, 60)
milliseconds = math.floor((seconds % 1) * 1000)
output = f"{int(hours):02}:{int(minutes):02}:{int(seconds):02},{milliseconds:03}"
return output
# 制作字幕文件
def make_srt(file_path,model_name="small"):
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cuda":
model = WhisperModel(model_name, device="cuda", compute_type="float16",download_root="./model_from_whisper",local_files_only=False)
else:
model = WhisperModel(model_name, device="cpu", compute_type="int8",download_root="./model_from_whisper",local_files_only=False)
# or run on GPU with INT8
# model = WhisperModel(model_size, device="cuda", compute_type="int8_float16")
segments, info = model.transcribe(file_path, beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
count = 0
with open('./video.srt', 'w') as f: # Open file for writing
for segment in segments:
count +=1
duration = f"{convert_seconds_to_hms(segment.start)} --> {convert_seconds_to_hms(segment.end)}\n"
text = f"{segment.text.lstrip()}\n\n"
f.write(f"{count}\n{duration}{text}") # Write formatted string to the file
print(f"{duration}{text}",end='')
with open("./video.srt", 'r',encoding="utf-8") as file:
srt_data = file.read()
return "转写完毕"
这里通过convert_seconds_to_hms方法来把时间戳格式化为标准字幕时间轴。
大模型翻译字幕
这里字幕翻译我们依然使用大模型,依然是阿里通义实验室的CSANMT连续语义增强机器翻译-英中-通用领域-large,模型官方地址:
https://modelscope.cn/models/iic/nlp_csanmt_translation_en2zh/summary
该模型基于连续语义增强的神经机器翻译模型,由编码器、解码器以及语义编码器三者构成。其中,语义编码器以大规模多语言预训练模型为基底,结合自适应对比学习,构建跨语言连续语义表征空间。此外,设计混合高斯循环采样策略,融合拒绝采样机制和马尔可夫链,提升采样效率的同时兼顾自然语言句子在离散空间中固有的分布特性。最后,结合邻域风险最小化策略优化翻译模型,能够有效提升数据的利用效率,显著改善模型的泛化能力和鲁棒性。
依然是通过pipeline进行调用:
# 翻译字幕
def make_tran():
pipeline_ins = pipeline(task=Tasks.translation, model=model_dir_ins)
with open("./video.srt", 'r',encoding="utf-8") as file:
gweight_data = file.read()
result = gweight_data.split("\n\n")
if os.path.exists("./two.srt"):
os.remove("./two.srt")
for res in result:
line_srt = res.split("\n")
try:
outputs = pipeline_ins(input=line_srt[2])
except Exception as e:
print(str(e))
break
print(outputs['translation'])
with open("./two.srt","a",encoding="utf-8")as f:f.write(f"{line_srt[0]}\n{line_srt[1]}\n{line_srt[2]}\n{outputs['translation']}\n\n")
return "翻译完毕"
合并字幕
虽然字幕已经完全可以导入剪辑软件进行使用了,但是依然可以通过技术手段来自动化合并字幕,这里使用ffmpeg:
# 合并字幕
def merge_sub(video_path,srt_path):
if os.path.exists("./test_srt.mp4"):
os.remove("./test_srt.mp4")
ffmpeg.input(video_path).output("./test_srt.mp4", vf="subtitles=" + srt_path).run()
return "./test_srt.mp4"
结语
笔者已经将上面提到的技术集成到了一个完整的项目之中,项目地址:
https://github.com/v3ucn/Modelscope_Faster_Whisper_Multi_Subtitle
操作简单,无须思考:
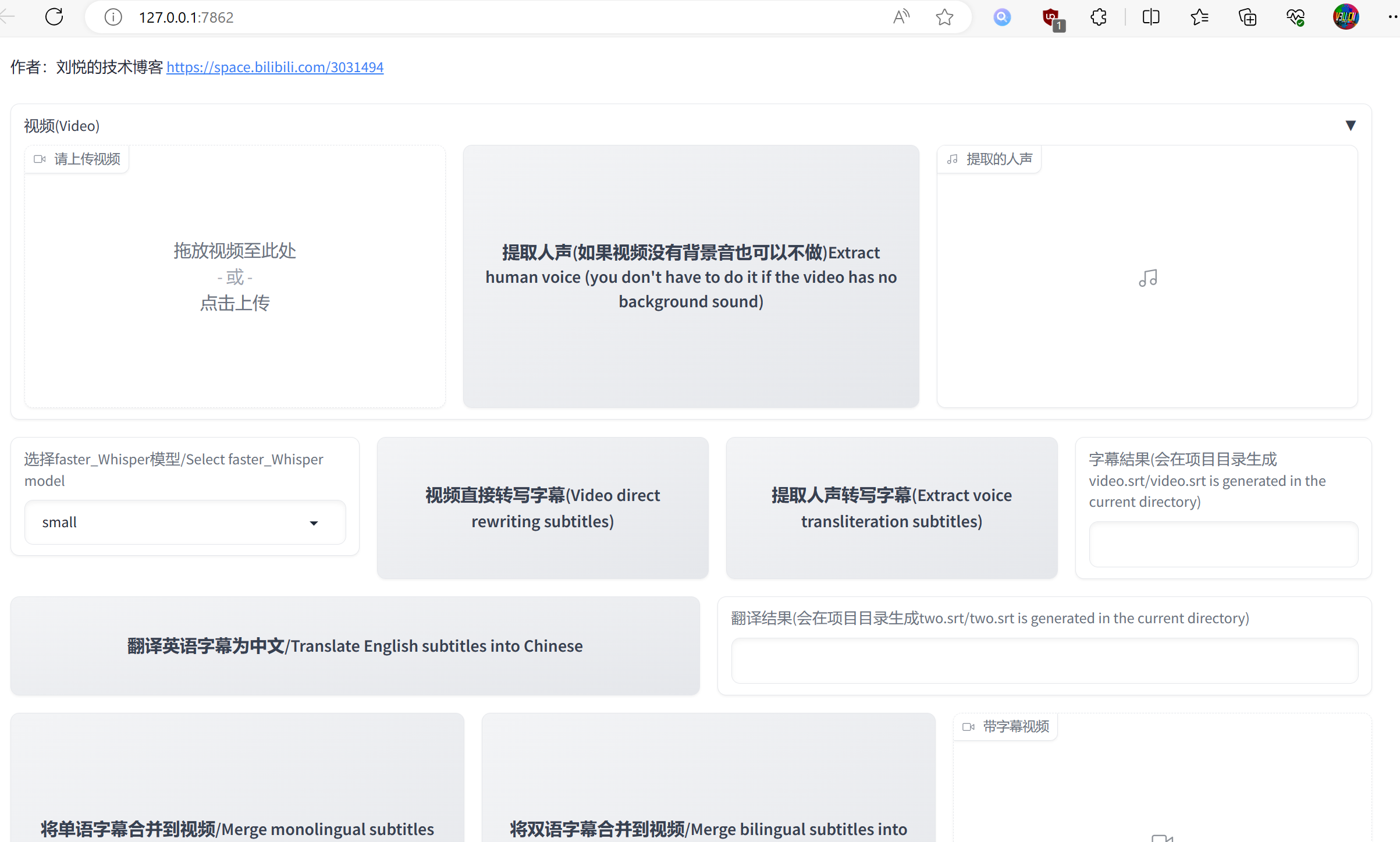
生成的双语字幕效果:

这也许是首个让普通人也能无脑操作的完全离线双语字幕制作方案。最后奉上整合包,以与众乡亲同飨:
https://pan.quark.cn/s/55248dcadfb6
离线生成双语字幕,一键生成中英双语字幕,基于AI大模型,ModelScope的更多相关文章
- 推荐系统| ② 离线推荐&基于隐语义模型的协同过滤推荐
一.离线推荐服务 离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率. 离线推 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- arcpy地理处理工具案例教程-生成范围-自动画框-深度学习样本提取-人工智能-AI
arcpy地理处理工具案例教程-生成范围-自动画框-深度学习样本提取-人工智能-AI 商务合作,科技咨询,版权转让:向日葵,135-4855_4328,xiexiaokui#qq.com 目的:对面. ...
- vscode vue 模版生成,vue 一键生成
vscode vue 模版 继上篇文章(vue 格式化),顺便记录下 vue 模版生成.图片就不在贴了,如果有找不到 vscode 插件商店的可以访问上篇文章. 一.安装 VueHelper 在 vs ...
- Excel催化剂开源第27波-Excel离线生成词云图
在数据分析领域,词云图已经成为在文本分析中装逼的首选图表,大家热烈地讨论如何在Python上做数据分析.做词云图. 数据分析从来都是Excel的主战场,能够让普通用户使用上的技术才是最有价值的技术,一 ...
- Excel催化剂开源第26波-Excel离线生成二维码条形码
在中国特有环境下,二维码.条形码的使用场景非常广泛,因Excel本身就是一个非常不错的报表生成环境,若Excel上能够直接生成二维码.条形码,且是批量化操作的,直接一条龙从数据到报表都由Excel完成 ...
- 【免费】windows下如何生成tar.gz,一键生成tar.gz
废话 一.实验背景 tar.gz 是Linux和Unix下面比较常用的格式,一条命令就可以把文件压缩打包成tar.gz格式,然而这种格式在windows并不多见. Linxu服务器上,tar.gz 包 ...
- LNMP一键安装包+Thinkphp搭建基于pathinfo模式的路由
LNMP一键安装包是一个用Linux Shell编写的可以为CentOS/RadHat/Fedora.Debian/Ubuntu/Raspbian/Deepin VPS或独立主机安装LNMP(Ngin ...
- 【Python+C#】手把手搭建基于Hugging Face模型的离线翻译系统,并通过C#代码进行访问
前言:目前翻译都是在线的,要在C#开发的程序上做一个可以实时翻译的功能,好像不是那么好做.而且大多数处于局域网内,所以访问在线的api也显得比较尴尬.于是,就有了以下这篇文章,自己搭建一套简单的离线翻 ...
- FreemarkerJavaDemo【Android将表单数据生成Word文档的方案之一(基于freemarker2.3.28,只能java生成)】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 这个方案只能在java中运行,无法在Android项目中运行.所以此方案是:APP将表单数据发送给后台,后台通过freemarker ...
随机推荐
- JAVA CRC16
JAVA CRC16 /** * CRC-16 * * <table width="400px" border="1" cellpadding=" ...
- IntelliJ IDEA 2024年最新下载、安装使用教程、亲测可用
本文讲的是2023.3最新版本IntelliJ IDEA破解.IntelliJ IDEA激活码.IntelliJ IDEA安装.IntelliJ IDEA永久激活码的最新永久激活教程,本文有mac和w ...
- 3 分钟看完 NVIDIA GPU 架构及演进
近期随着 AI 市场的爆发式增长,作为 AI 背后技术的核心之一 GPU(图形处理器)的价格也水涨船高.GPU 在人工智能中发挥着巨大的重要,特别是在计算和数据处理方面.目前生产 GPU 主流厂商其实 ...
- 机器学习 | 剖析感知器算法 & Python实现
前言:本系列博客参考于 <机器学习算法导论>和<Python机器学习> 如有侵权,敬请谅解.本书尽量用总结性的语言重述本书内容,避免侵权. 上一篇已经初步介绍了机器学习相关知识 ...
- Codeforces Round #700 (Div. 2) A ~ D1个人题解
Codeforces Round #700 (Div. 2) 比赛链接: Click Here 1480A. Yet Another String Game 因为Alice是要追求小,Bob追求大值, ...
- 无需修改代码,用 fcapp.run 运行你的 REST 应用
作者 | 阿里云 Serverless 技术研发 落语 背景 阿里云函数计算产品在较早的时候支持了HTTP触发器能力,支持用户使用 HTTP 协议进行函数调用.函数计算后端通过一个共享的 APISer ...
- mybatisplus 查询结果排除某字段实现
数据有Test表,表里有id,name,ip_address,last_time四个字段 通常查询写法,返回结果会把id,name,ip_address,last_time四个字段都返回 public ...
- Vue3 Diff算法之最长递增子序列,学不会来砍我!
专栏分享:vue2源码专栏,vue3源码专栏,vue router源码专栏,玩具项目专栏,硬核推荐 欢迎各位ITer关注点赞收藏 Vue2 Diff算法可以参考[Vue2.x源码系列08]Diff算法 ...
- Linux: CPU C-states
0. Overview There are various power modes of the CPU which are determined based on their current usa ...
- linux 对子用户配置java 环境变量
转载请注明出处: 若服务器安装 jdk 时用的是root 用户,则root 用户登录服务器可以直接获取Java环境. 当切换到其他子用户时,则会发现环境不存在,命令不存在等. 解决方案: 1. 先切换 ...