论文解读(TAT)《 Transferable Adversarial Training: A General Approach to Adapting Deep Classifiers》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Transferable Adversarial Training: A General Approach to Adapting Deep Classifiers
论文作者:Hong Liu, Mingsheng Long, Jianmin Wang, Michael I. Jordan
论文来源:ICML 2019
论文地址:download
论文代码:download
1 Introduction
出发点:当使用对抗性训练的时候,因为抑制领域特定的变化时,会扭曲原始的特征分布;
事实:

Figure2(b):
- 使用源域和目标域的标记数据做测试,对比了使用对抗性训练(DANN、MCD)和监督训练(EestNet50)的测试误差;
- 结论:使用对抗性训练,减少特定领域的变化不可避免地打破了原始表示的判别结构;
Figure2(c):
计算特征表示层模型权重的奇异值分布;
结论:使用对抗性训练的奇异值分布更加重尾,表示条件更差和更扭曲的特征表示;
2 方法
2.1 模型框架
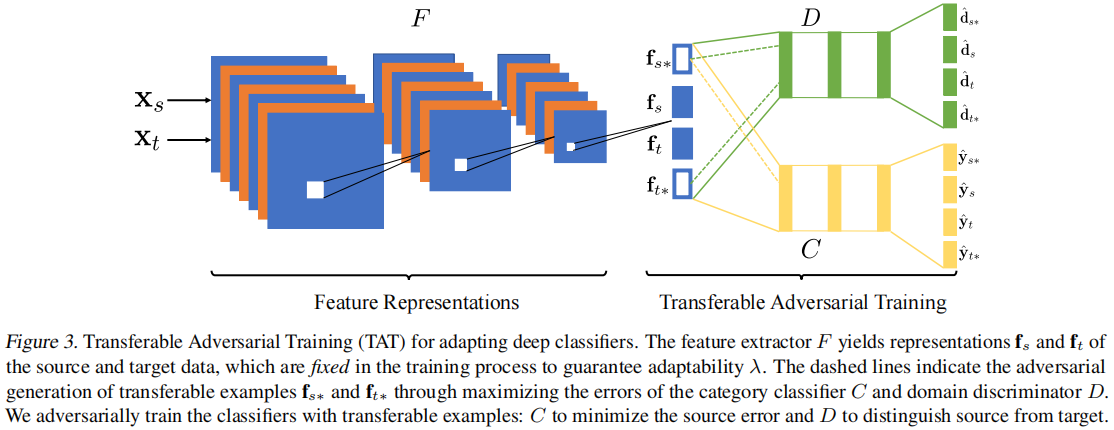
2.2 Adversarial Generation of Transferable Examples
现有的对抗性特征自适应方法通过学习领域不变表示来减少特定领域的变化。用 $f = F (x)$ 表示特征提取器,用 $d = D (f)$ 表示域鉴别器。$D$ 和 $F$ 形成一个双人极大极小博弈:$D$ 训练区分源和目标,而 $F$ 同时训练混淆 $D$。然而,这样种过程可能会恶化适应性。为保证适应性,本文提出修复特征表示,并生成可转移的例子来弥合域差距。具体地说,仍然训练域鉴别器 $D$ 通过以下损失函数来区分源域和目标域:
$\begin{aligned}\ell_{d}\left(\theta_{D}, \mathbf{f}\right)= & -\frac{1}{n_{s}} \sum_{i=1}^{n_{s}} \log \left[D\left(\mathbf{f}_{s}^{(i)}\right)\right] \\& -\frac{1}{n_{t}} \sum_{i=1}^{n_{t}} \log \left[1-D\left(\mathbf{f}_{t}^{(i)}\right)\right] .\end{aligned} \quad\quad(1)$
分类器 $C$ 通过源域样本监督训练:
$\ell_{c}\left(\theta_{C}, \mathbf{f}\right)=\frac{1}{n_{s}} \sum_{i=1}^{n_{s}} \ell_{c e}\left(C\left(\mathbf{f}_{s}^{(i)}\right), \mathbf{y}_{s}^{(i)}\right) \quad\quad(2)$
与现有的对抗性训练方法不同,本文通过在一种新的对抗性训练范式中生成的可转移样本来填补源域和目标域之间的差距,从而减少分布变化。
生成的可转移样本需要满足两个条件:
- 首先,可转移的样本应该有效地混淆域鉴别器 $D$,从而填补域间隙,桥接源域和目标域;
- 其次,可转移的样本应该能够欺骗类别分类器 $C$,这样它们就可以推动决策边界远离数据点;
因此,可转移的样本是通过 $\ell_{c}$ 和 $\ell_{d}$ 的联合损失而反向生成的:
$\begin{aligned}\mathbf{f}_{t^{k+1}} \leftarrow \mathbf{f}_{t^{k}} & +\beta \nabla_{\mathbf{f}_{t^{k}}} \ell_{d}\left(\theta_{D}, \mathbf{f}_{t^{k}}\right) \\& -\gamma \nabla_{\mathbf{f}_{t^{k}}} \ell_{2}\left(\mathbf{f}_{t^{k}}, \mathbf{f}_{t^{0}}\right) \\\end{aligned} \quad\quad(3)$
$\begin{aligned}\mathbf{f}_{s^{k+1}} \leftarrow \mathbf{f}_{s^{k}} & +\beta \nabla_{\mathbf{f}_{s}} \ell_{d}\left(\theta_{D}, \mathbf{f}_{s^{k}}\right) \\& -\gamma \nabla_{\mathbf{f}_{s}} \ell_{2}\left(\mathbf{f}_{s^{k}}, \mathbf{f}_{s^{0}}\right) \\& +\beta \nabla_{\mathbf{f}_{s k}} \ell_{c}\left(\theta_{C}, \mathbf{f}_{s^{k}}\right)\end{aligned} \quad\quad(4)$
其中,$\mathbf{f}_{t^{0}}=\mathbf{f}_{t}, \mathbf{f}_{s^{0}}=\mathbf{f}_{s}, \mathbf{f}_{t *}=\mathbf{f}_{t^{K}}, \mathbf{f}_{s *}=\mathbf{f}_{s^{K}}$。
此外,为避免生成的样本的发散,控制生成的样本与原始样本之间的 $\ell_{2}$-距离。
2.3 Adversarial Training with Transferable Examples
因此,对类别分类器 $C$ 的对抗性训练的损失函数表述如下:
$\begin{aligned}\ell_{c, a d v}\left(\theta_{C}, \mathbf{f}_{*}\right) & =\frac{1}{n_{s}} \sum_{i=1}^{n_{s}} \ell_{c e}\left(C\left(\mathbf{f}_{s *}^{(i)}\right), \mathbf{y}_{s *}^{(i)}\right) \\& +\frac{1}{n_{t}} \sum_{i=1}^{n_{t}}\left|C\left(\left(\mathbf{f}_{t *}^{(i)}\right)\right)-C\left(\left(\mathbf{f}_{t}^{(i)}\right)\right)\right|\end{aligned} \quad\quad(5)$
与训练类别分类器类似,也用生成的可转移的例子来训练域鉴别器。这对于稳定对抗性训练过程很重要,否则生成的可转移的例子就会出现分歧。另一个关键的观点是利用这些可转移的例子来弥合领域上的差异。简单地在原始数据上欺骗域鉴别器并不能保证生成的示例可以从一个域转移到另一个域。因此,建议反向训练域鉴别器,以进一步区分可转移的例子从源和目标,使用以下损失:
$\begin{aligned}\ell_{d, a d v}\left(\theta_{D}, \mathbf{f}_{*}\right)= & -\frac{1}{n_{s}} \sum_{i=1}^{n_{s}} \log \left[D\left(\mathbf{f}_{s *}^{(i)}\right)\right] \\& -\frac{1}{n_{t}} \sum_{i=1}^{n_{t}} \log \left[1-D\left(\mathbf{f}_{t *}^{(i)}\right)\right]\end{aligned} \quad\quad(6)$
我们共同最小化误差(1)和误差(6)来训练 $D$,最小化误差(2)和误差(5) 来训练 $C$,训练目标:
$\begin{array}{l}\underset{\theta_{D}, \theta_{C}}{\text{min}}\;\;\ell_{d}\left(\theta_{D}, \mathbf{f}\right)+\ell_{c}\left(\theta_{C}, \mathbf{f}\right) +\ell_{d, a d v}\left(\theta_{D}, \mathbf{f}_{*}\right)+\ell_{c, a d v}\left(\theta_{C}, \mathbf{f}_{*}\right) \end{array} \quad\quad(7)$
3 实验


论文解读(TAT)《 Transferable Adversarial Training: A General Approach to Adapting Deep Classifiers》的更多相关文章
- 迁移学习(PAT)《Pairwise Adversarial Training for Unsupervised Class-imbalanced Domain Adaptation》
论文信息 论文标题:Pairwise Adversarial Training for Unsupervised Class-imbalanced Domain Adaptation论文作者:Weil ...
- 论文解读(ARVGA)《Learning Graph Embedding with Adversarial Training Methods》
论文信息 论文标题:Learning Graph Embedding with Adversarial Training Methods论文作者:Shirui Pan, Ruiqi Hu, Sai-f ...
- 论文解读( FGSM)《Adversarial training methods for semi-supervised text classification》
论文信息 论文标题:Adversarial training methods for semi-supervised text classification论文作者:Taekyung Kim论文来源: ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- 《C-RNN-GAN: Continuous recurrent neural networks with adversarial training》论文笔记
出处:arXiv: Artificial Intelligence, 2016(一年了还没中吗?) Motivation 使用GAN+RNN来处理continuous sequential data, ...
- 自监督学习(Self-Supervised Learning)多篇论文解读(下)
自监督学习(Self-Supervised Learning)多篇论文解读(下) 之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测.旋转预测.灰度图片上色.视频帧排序等 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- Adversarial Training
原于2018年1月在实验室组会上做的分享,今天分享给大家,希望对大家科研有所帮助. 今天给大家分享一下对抗训练(Adversarial Training,AT). 为何要选择这个主题呢? 我们从上图的 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- CVPR2020 论文解读:少点目标检测
CVPR2020 论文解读:具有注意RPN和多关系检测器的少点目标检测 Few-Shot Object Detection with Attention-RPN and Multi-Relation ...
随机推荐
- 2022-11-09:给定怪兽的血量为hp 第i回合如果用刀砍,怪兽在这回合会直接掉血,没有后续效果 第i回合如果用毒,怪兽在这回合不会掉血, 但是之后每回合都会掉血,并且所有中毒的后续效果会叠加 给
2022-11-09:给定怪兽的血量为hp 第i回合如果用刀砍,怪兽在这回合会直接掉血,没有后续效果 第i回合如果用毒,怪兽在这回合不会掉血, 但是之后每回合都会掉血,并且所有中毒的后续效果会叠加 给 ...
- group_concat 自定义聚合查询
group_concat
- es笔记一之es安装与介绍
本文首发于公众号:Hunter后端 原文链接:es笔记一之es安装与介绍 首先介绍一下 es,全名为 Elasticsearch,它定义上不是一种数据库,是一种搜索引擎. 我们可以把海量数据都放到 e ...
- CANoe学习笔记(六):如何实现LIN和CAN的多帧传输-----LIN
内容: 1.实现LIN的多帧传输 一.新建一个基于LIN的CANoe工程 二.接下来创建一些工程用得上的变量.文件: 2.1 LDF文件: 这部分注意:包含三个调度表,①3C诊断请求帧②3D诊断响应帧 ...
- Helm实战案例一:在Kubernetes上使用Helm搭建Prometheus Operator监控
目录 一.系统环境 二.前言 三.Prometheus Operator简介 四.helm安装prometheus-operator 五.配置prometheus-operator 5.1 修改gra ...
- 你的专属音乐生成器「GitHub 热点速览」
如果你制作视频,一定会碰到配乐的问题.虽然网上找的一些免费配乐能勉强满足需求,但是如果有个专属的配乐生成器,根据你的视频画面生成对应配乐是不是不错呢?audiocraft 也许能帮助你,把相关画面用文 ...
- SPSS统计教程:卡方检验
本文简要的介绍了卡方分布.卡方概率密度函数和卡方检验,并通过SPSS实现了一个卡方检验例子,不仅对结果进行了解释,而且还给出了卡方.自由度和渐近显著性的计算过程.本文用到的数据"2.2.sa ...
- Educational Codeforces Round 150 (Rated for Div. 2) A-E
比赛链接 A 代码 #include <bits/stdc++.h> using namespace std; using ll = long long; bool solve() { i ...
- 如何使用libavfilter库给pcm音频采样数据添加音频滤镜?
一.初始化音频滤镜 初始化音频滤镜的方法基本上和初始化视频滤镜的方法相同,不懂的可以看上篇博客,这里直接给出代码: //audio_filter_core.cpp #define INPUT_SAMP ...
- "Process finished with exit code 1" 进程结束
问题描述 : springboot 程序运行出现以下情况 没有错误日志 返回运行结束 状态码 1 状态码为 1 的时候表示程序不是异常终止 连接到目标VM, 地址: ''127. ...