2-10 就业课(2.0)-oozie:6、通过oozie执行mr任务,以及执行sqoop任务的解决思路
执行sqoop任务的解决思路(目前的问题是sqoop只安装在node03上,而oozie会随机分配一个节点来执行任务):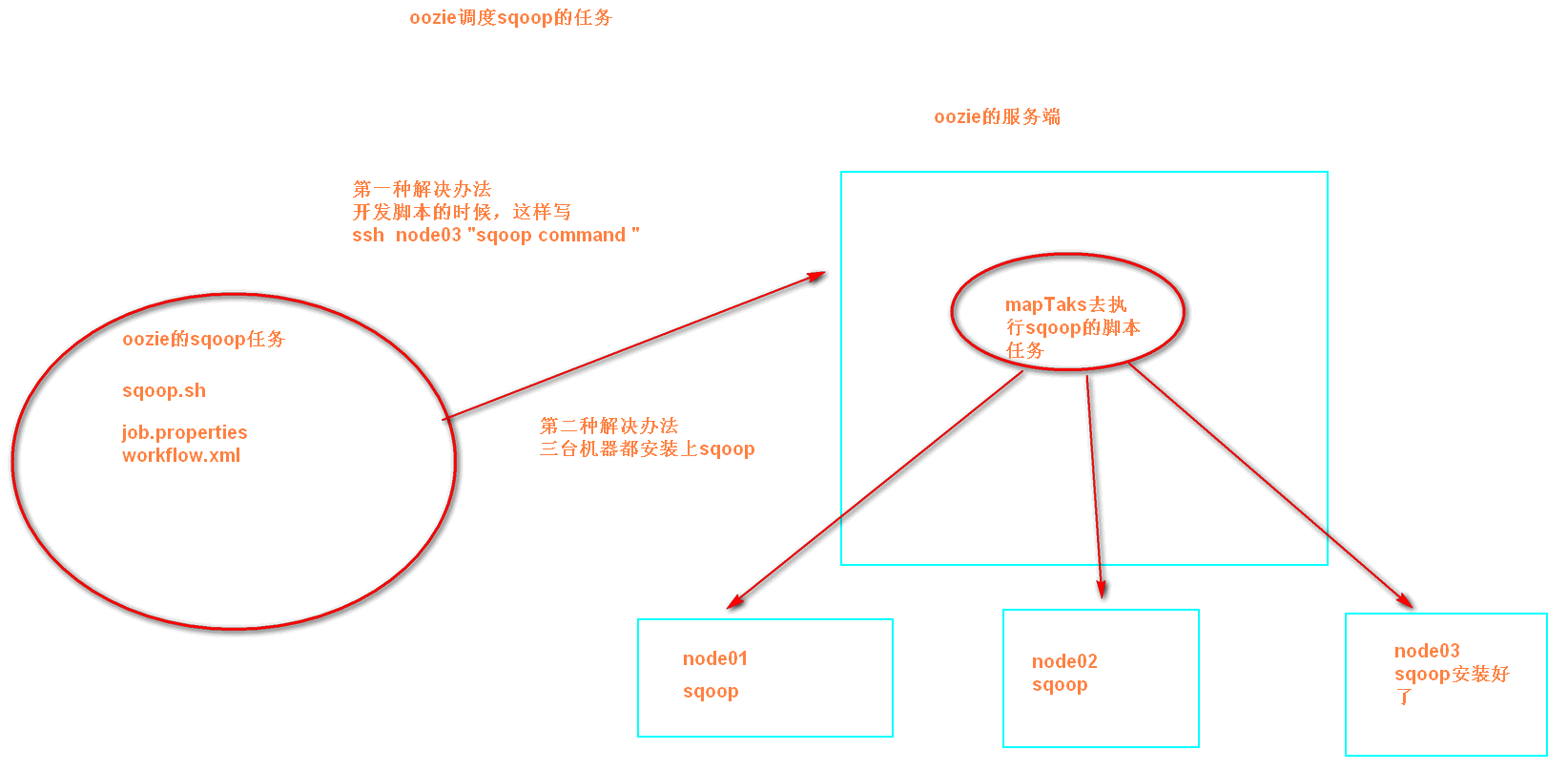
=====================================================
4.3、使用oozie调度MR任务
第一步:准备MR执行的数据
我们这里通过oozie调度一个MR的程序的执行,MR的程序可以是自己写的,也可以是hadoop工程自带的,我们这里就选用hadoop工程自带的MR程序来运行wordcount的示例
准备以下数据上传到HDFS的/oozie/input路径下去
hdfs dfs -mkdir -p /oozie/input
vim wordcount.txt
hello world hadoop
spark hive hadoop
将我们的数据上传到hdfs对应目录
hdfs dfs -put wordcount.txt /oozie/input
第二步:执行官方测试案例
yarn jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar wordcount /oozie/input/ /oozie/output
第三步:准备我们调度的资源
将我们需要调度的资源都准备好放到一个文件夹下面去,包括我们的jar包,我们的job.properties,以及我们的workflow.xml。
拷贝MR的任务模板
cd /export/servers/oozie-4.1.0-cdh5.14.0
cp -ra examples/apps/map-reduce/ oozie_works/
删掉MR任务模板lib目录下自带的jar包
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib
rm -rf oozie-examples-4.1.0-cdh5.14.0.jar
第三步:拷贝我们自己的jar包到对应目录
从上一步的删除当中,我们可以看到我们需要调度的jar包存放在了
/export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib这个目录下,所以我们把我们需要调度的jar包也放到这个路径下即可
cp /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce/lib/
第四步:修改配置文件
修改job.properties
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/map-reduce/workflow.xml

outputDir=/oozie/output
inputdir=/oozie/input
修改workflow.xml
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/map-reduce
vim workflow.xml
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<workflow-app xmlns="uri:oozie:workflow:0.5" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/${outputDir}"/>

</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!--
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>

</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>

</property>
-->
<!-- 开启使用新的API来进行配置 -->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- 指定MR的输出key的类型 -->
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<!-- 指定MR的输出的value的类型-->
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!-- 指定输入路径 -->
<property>
<name>mapred.input.dir</name>
<value>${nameNode}/${inputDir}</value>

</property>
<!-- 指定输出路径 -->
<property>
<name>mapred.output.dir</name>
<value>${nameNode}/${outputDir}</value>
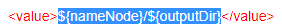
</property>
<!-- 指定执行的map类 -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<!-- 指定执行的reduce类 -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<!-- 配置map task的个数 -->
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
第五步:上传调度任务到hdfs对应目录
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
hdfs dfs -put map-reduce/ /user/root/oozie_works/
第六步:执行调度任务
执行我们的调度任务,然后通过oozie的11000端口进行查看任务结果
cd /export/servers/oozie-4.1.0-cdh5.14.0
bin/oozie job -oozie http://node03:11000/oozie -config oozie_works/map-reduce/job.properties -run
2-10 就业课(2.0)-oozie:6、通过oozie执行mr任务,以及执行sqoop任务的解决思路的更多相关文章
- 2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境
hadoop 的基础环境增强 HA模式 HA是为了保证我们的业务 系统 7 *24 的连续的高可用提出来的一种解决办法,现在hadoop当中的主节点,namenode以及resourceManager ...
- 2-10 就业课(2.0)-oozie:9、oozie与hue的整合,以及整合后执行MR任务
5.hue整合oozie 第一步:停止oozie与hue的进程 通过命令停止oozie与hue的进程,准备修改oozie与hue的配置文件 第二步:修改oozie的配置文件(老版本的bug,新版本已经 ...
- 2-10 就业课(2.0)-oozie:7、job任务的串联
4.4.oozie的任务串联 在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个ac ...
- 2-10 就业课(2.0)-oozie:2、介绍和安装1
oozie的安装及使用 1. oozie的介绍 Oozie是运行在hadoop平台上的一种工作流调度引擎,它可以用来调度与管理hadoop任务,如,MapReduce.Pig等.那么,对于Oozie ...
- 2-10 就业课(2.0)-oozie:8、定时任务的执行
4.5.oozie的任务调度,定时任务执行 在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与我们的workflow类似的,Coordinator 这个模块也是主要通过xml ...
- 2-10 就业课(2.0)-oozie:5、通过oozie执行hive的任务
4.2.使用oozie调度我们的hive 第一步:拷贝hive的案例模板 cd /export/servers/oozie-4.1.0-cdh5.14.0 cp -ra examples/apps/h ...
- 2-10 就业课(2.0)-oozie:13、14、clouderaManager的服务搭建
3.clouderaManager安装资源下载 第一步:下载安装资源并上传到服务器 我们这里安装CM5.14.0这个版本,需要下载以下这些资源,一共是四个文件即可 下载cm5的压缩包 下载地址:htt ...
- 2-10 就业课(2.0)-oozie:12、cm环境搭建的基础环境准备
8.clouderaManager5.14.0环境安装搭建 Cloudera Manager是cloudera公司提供的一种大数据的解决方案,可以通过ClouderaManager管理界面来对我们的集 ...
- 2-10 就业课(2.0)-oozie:4、通过oozie执行shell脚本
oozie的配置文件job.properties:里面主要定义的是一些key,value对,定义了一些变量,这些变量往workflow.xml里面传递workflow.xml :workflow的配置 ...
随机推荐
- FTP-Publisher Plugin
使用 FTP-Publisher Plugin 在 http://wiki.hudson-ci.org/display/HUDSON/FTP-Publisher+Plugin 有详细说明, 需要注意的 ...
- 「JSOI2010」挖宝藏
「JSOI2010」挖宝藏 传送门 由于题目中说道挖一个位置的前提是挖掉它上面的三个,以此类推可以发现,挖掉一个点就需要挖掉这个点往上的整个倒三角,那么也就会映射到 \(x\) 轴上的一段区间(可以发 ...
- SpringBoot 集成JUnit
项目太大,不好直接测整个项目,一般都是切割成多个单元,单独测试,即单元测试. 直接在原项目上测试,会把项目改得乱七八糟的,一般是单独写测试代码. 进行单元测试,这就需要集成JUnit. (1)在pom ...
- IDEA 查看某个class的maven引用依赖&如何展示Diagram Elements
1.打开对应的class,如下图所示,至于具体快捷键就不说了,我是设置的eclipse的快捷键: 2.定位到对应jar,记下jar名称及版本: 3.在右侧栏点击maven,再在展出的视图中找到对应的m ...
- spark-调节executor堆外内存
什么时候需要调节Executor的堆外内存大小? 当出现一下异常时: shuffle file cannot find,executor lost.task lost,out of memory 出现 ...
- 循环语句(while语句和do...while语句)
1.while语句:如果条件成立,就继续循环,直到条件不成立为止.格式如下: while (条件) { 循环体(语句或语句块) } 2.do…while语句:如果条件成立, ...
- win10+anaconda安装tensorflow和keras遇到的坑小结
win10下利用anaconda安装tensorflow和keras的教程都大同小异(针对CPU版本,我的gpu是1050TI的MAX-Q,不知为啥一直没安装成功),下面简单说下步骤. 一 Anaco ...
- 模块学习--OS
1 返回当前目录信息 >>> os.getcwd() 'D:\\7_Python\\S14' 2 改变路径 >>> os.chdir('d:\\')#os.chdi ...
- NB-IoT的介绍最终版 !看明白了吗?(转自 top-iot)
标签: NB-IOT 1 1G-2G-3G-4G-5G 不解释,看图,看看NB-IoT在哪里? 2 NB-IoT标准化历程 3GPP NB-IoT的标准化始于2015年9月,于2016年7月R13 ...
- Android FM模块学习之四源码解析(一)
转自:http://blog.csdn.net/tfslovexizi/article/details/41516149?utm_source=tuicool&utm_medium=refer ...