2-10 就业课(2.0)-oozie:7、job任务的串联
4.4、oozie的任务串联
在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个action,实现多个任务之间的相互依赖关系
需求:首先执行一个shell脚本,执行完了之后再执行一个MR的程序,最后再执行一个hive的程序
第一步:准备我们的工作目录
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
mkdir -p sereval-actions
第二步:准备我们的调度文件
将我们之前的hive,shell,以及MR的执行,进行串联成到一个workflow当中去,准备我们的资源文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works
cp hive2/script.q sereval-actions/
cp shell/hello.sh sereval-actions/
cp -ra map-reduce/lib sereval-actions/
第三步:开发调度的配置文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
创建配置文件workflow.xml并编辑
vim workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<!-- <argument>my_output=Hello Oozie</argument> -->
<file>/user/root/oozie_works/sereval-actions/${EXEC}#${EXEC}</file>
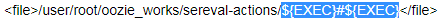
<capture-output/>
</shell>
<ok to="mr-node"/>
<error to="mr-node"/>
</action>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/${outputDir}"/>

</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!--
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
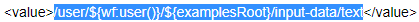
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>

</property>
-->
<!-- 开启使用新的API来进行配置 -->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- 指定MR的输出key的类型 -->
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<!-- 指定MR的输出的value的类型-->
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!-- 指定输入路径 -->
<property>
<name>mapred.input.dir</name>
<value>${nameNode}/${inputDir}</value>

</property>
<!-- 指定输出路径 -->
<property>
<name>mapred.output.dir</name>
<value>${nameNode}/${outputDir}</value>

</property>
<!-- 指定执行的map类 -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<!-- 指定执行的reduce类 -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<!-- 配置map task的个数 -->
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="hive2-node"/>
<error to="fail"/>
</action>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>

<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>

</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>

<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>

</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end">
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
</case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
开发我们的job.properties配置文件
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/sereval-actions
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
EXEC=hello.sh
outputDir=/oozie/output
inputdir=/oozie/input
jdbcURL=jdbc:hive2://node03:10000/default
oozie.use.system.libpath=true
# 配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/sereval-actions这个路径下
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/sereval-actions/workflow.xml

第四步:上传我们的资源文件夹到hdfs对应路径
cd /export/servers/oozie-4.1.0-cdh5.14.0/oozie_works/
hdfs dfs -put sereval-actions/ /user/root/oozie_works/
第五步:执行调度任务
cd /export/servers/oozie-4.1.0-cdh5.14.0/
bin/oozie job -oozie http://node03:11000/oozie -config oozie_works/serveral-actions/job.properties -run
2-10 就业课(2.0)-oozie:7、job任务的串联的更多相关文章
- 2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境
hadoop 的基础环境增强 HA模式 HA是为了保证我们的业务 系统 7 *24 的连续的高可用提出来的一种解决办法,现在hadoop当中的主节点,namenode以及resourceManager ...
- 2-10 就业课(2.0)-oozie:9、oozie与hue的整合,以及整合后执行MR任务
5.hue整合oozie 第一步:停止oozie与hue的进程 通过命令停止oozie与hue的进程,准备修改oozie与hue的配置文件 第二步:修改oozie的配置文件(老版本的bug,新版本已经 ...
- 2-10 就业课(2.0)-oozie:8、定时任务的执行
4.5.oozie的任务调度,定时任务执行 在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与我们的workflow类似的,Coordinator 这个模块也是主要通过xml ...
- 2-10 就业课(2.0)-oozie:5、通过oozie执行hive的任务
4.2.使用oozie调度我们的hive 第一步:拷贝hive的案例模板 cd /export/servers/oozie-4.1.0-cdh5.14.0 cp -ra examples/apps/h ...
- 2-10 就业课(2.0)-oozie:13、14、clouderaManager的服务搭建
3.clouderaManager安装资源下载 第一步:下载安装资源并上传到服务器 我们这里安装CM5.14.0这个版本,需要下载以下这些资源,一共是四个文件即可 下载cm5的压缩包 下载地址:htt ...
- 2-10 就业课(2.0)-oozie:12、cm环境搭建的基础环境准备
8.clouderaManager5.14.0环境安装搭建 Cloudera Manager是cloudera公司提供的一种大数据的解决方案,可以通过ClouderaManager管理界面来对我们的集 ...
- 2-10 就业课(2.0)-oozie:6、通过oozie执行mr任务,以及执行sqoop任务的解决思路
执行sqoop任务的解决思路(目前的问题是sqoop只安装在node03上,而oozie会随机分配一个节点来执行任务): ======================================= ...
- 2-10 就业课(2.0)-oozie:4、通过oozie执行shell脚本
oozie的配置文件job.properties:里面主要定义的是一些key,value对,定义了一些变量,这些变量往workflow.xml里面传递workflow.xml :workflow的配置 ...
- 2-10 就业课(2.0)-oozie:3、安装2
第七步:修改oozie-site.xml cd /export/servers/oozie-4.1.0-cdh5.14.0/conf vim oozie-site.xml 如果没有这些属性,直接添加进 ...
随机推荐
- CSS背景透明设置
style="margin-top:300px;background:rgba(255,255,255,这里设置小于1比如0.6这样); color:black;" style=& ...
- 题解【[Ynoi2012]NOIP2015洋溢着希望】
\[ \texttt{Preface} \] 第二道 Ynoi 的题,纪念一下. 这可能是我唯一可以自己做的 Ynoi 题了. \[ \texttt{Description} \] 维护一个长度为 \ ...
- 对于使用javaweb技术制作简单管理系统的学习
近期在老师的引导下我们学习了利用Javaweb技术制作简单的管理系统,其中涉及到的技术很多,由于大多都是自学 对这些技术的理解还太浅显但能实现一些相关功能的雏形. (一).登录功能 在登陆功能中通过与 ...
- 新手如何配置 Chromedriver 环境变量
有一个不错的链接:https://blog.csdn.net/qq_41429288/article/details/80472064
- vue父孙组件传值($attr及$listeners)的使用
父组件 <template> <div> <!-- 将值传给子组件 子组件可以获取自己想要的值 也可以忽视掉需要传给孙子组件的值 --> <!-- 同时获取通 ...
- mysql cmmand not found
https://www.cnblogs.com/yangzigege/p/8337393.html
- 十五 OGNL的入门
一.访问对象的方法
- 吴裕雄--天生自然 JAVA开发学习:解决java.sql.SQLException: The server time zone value报错
这个异常是时区的错误,因此只你需要设置为你当前系统时区即可,解决方案如下: import java.sql.Connection ; import java.sql.DriverManager ; i ...
- 什么是Socket:
先了解一些前提: 网络由下往上分为 物理层 .数据链路层 . 网络层 . 传输层 . 会话层 . 表现层 和 应用层.通过初步了解,我知道IP协议对应于网络层,TCP协议对应于传输层,而HTTP协议对 ...
- minst.npz下载
keras.datasets.mnist数据集下载地址 下载地址:链接: https://pan.baidu.com/s/1Rr-aHsIIEQx2z6W3qvMmhQ 提取码: 8w15