SC.Lab3对于Factory的构建过程(from HIT)
Factory设计模式基本就是通过传入指定的参数/或者不传入参数,通过Factory的某个方法(为了避免实例化Factory对象,一般方法为静态static),来获取一个对象。这个是Factory用的比较多的地方。对于Vertex和Edge的Factory来说,通过传入一些构建对象所需的信息来自动创建一个对象,这样也就避免了重复调用Vertex/Edge自身的方法来为Vertex/Edge对象添加信息/属性。
对于图来说,实例化一个图只需要一个String标签(根据你设计的Graph的构造器来决定),然而如果想要构建一个完整的图,肯定要向图中添加顶点和边。这就要重复调用图的相关方法,对于这种情况,完全可以考虑把构建图需要的信息写到一个文件里,在构建图的时候,读入这个文件来获取信息,从而使得构建图的过程简单化,即避免了很多重复的操作。也就是说,你只需要向图的Factory的createGraph传入一个String filePath,让它按照这个文件的路径去打开文件,从文件中读取信息即可。这个方法的返回值就是图的引用,因此这个方法就实现了构造图的功能。
于是,这个构造图的方法里主要就涉及两个部分,一个是读图的数据,一个是通过调用图的方法来把这些数据利用起来(可能也要判断传入的信息是否合法)。
读数据的时候,用正则表达式来匹配处理,处理方法就和之前的实验的处理方式类似,每当从文件中读入一行数据的时候,就对这行数据进行解析,获得并存储需要的信息。对于Java如何读取文件,可能在课程后面会讲,但书上以及网上都有很多处理方法,当然前两次实验也用到了。总的来说,就是处理Java的读写数据的流,指定某个文件并为其实例化文件对象,创建读入流对象把这个文件对象读入,再创建缓冲区读入流对象,处理读入流对象,最后通过调用缓冲区读入流对象的方法,将读入的数据转换为String型对象。因此对于“Java全部都是对象”的说法可见一斑。
我的读文件的过程就是这样,通过调用缓冲区读入流对象的方法,一行一行地传入数据(String类型),如果读到文件的末尾,这个方法就会传回一个null引用,此时你的临时存储读入的数据的String对象引用也就变成了null,证明此时文件读完了。正常情况下此时要注意把缓冲区对象的读入流关闭(肯定有很多安全性之类的原因,记住就好),即调用缓冲区对象的close方法。
此时已经拿到了文件的一行数据,为了匹配数据,就要设计几种模式来进行匹配传入的串。对于这个文件的格式,样式并不多,可以参见之前的博客链接: http://www.cnblogs.com/stevenshen123/p/8973413.html。
可以看到,读入文件中,格式基本为一个单词加上' = '再加上由""<>界定的信息串,于是乎,就不用太在意第一个单词的匹配,只要用相同的模式匹配就好(即用正则表达式\\w+匹配,\\w是一个字母,可以代指[a-zA-Z0-9],+就表示这样的字母有一个或多个,于是对于第一行串,就可以匹配“GraphType”,读到了那个空格的时候,匹配结束,此时就可以把已经匹配的部分读取,即读取了GraphType,再匹配空格=空格,用英文引号/尖括号来匹配接下来的内容,这时对于一行数据来说,粗略地来讲,就只要=前的部分、=后的部分的数据。于是就考虑最大化地获取=后的串,再细化地对这个串进行处理。于是设计两种用于匹配的正则表达式:
pattern1 = "(\\w+) = (\".+\")", pattern2 = "(\\w+) = <(.+)>";
对于这两个模式,括号是用于后面获取数据用的,也就是说,括号中的数据是要获取的部分。
对于pattern1,它匹配的就是/单词(多个字母) = "串"/,也就是匹配文件的内容有
GraphType = "MovieGraph"
GraphName = "MyFavoriteMovies"
VertexType = "Movie", "Actor", "Director"
EdgeType = "MovieActorRelation", "MovieDirectorRelation", "SameMovieHyperEdge"
观察括号的位置,获取的数据就是
/GraphType/、/"MovieGraph"/
/GraphName/、/"MyFavoriteMovies"/
/VertexType/、/"Movie", "Actor", "Director"/
/EdgeType/、/"MovieActorRelation", "MovieDirectorRelation", "SameMovieHyperEdge"/
即第一个括号内获取的是行首的单词,第二个括号匹配的就是第一个引号到最后的一个引号的串(包括引号自身,第二个括号匹配模式用到的就是之前说的最大化匹配)。
对于pattern2,类似于pattern1,它匹配的就是含有尖括号的数据,它匹配的就是/单词(多个字母) = <串>/,其匹配的文件内容格式就包括:
Vertex = <"TheShawshankRedemption", "Movie", <"1994", "USA", "9.3">>
Edge = <"SRFD", "MovieDirectorRelation", "-1", "TheShawshankRedemption", "FrankDarabont", "No">
HyperEdge = <"ActorsInSR","SameMovieHyperEdge",{"TimRobbins", "MorganFreeman"}>
观察括号的位置,获取的数据就是
/Vertex/、/"TheShawshankRedemption", "Movie", <"1994", "USA", "9.3">/
/Edge/、/"SRFD", "MovieDirectorRelation", "-1", "TheShawshankRedemption", "FrankDarabont", "No"/
/HyperEdge/、/"ActorsInSR","SameMovieHyperEdge",{"TimRobbins", "MorganFreeman"}/
即第一个括号内获取的是行首的单词,第二个括号匹配的就是第一个尖括号到最后的一个尖括号的串(不包括尖括号自身,第二个括号匹配模式用到的就是之前说的最大化匹配)。
此时已经拿到了每行的第一个单词,并可以根据这个单词的具体内容来判断应该如何对这个单词后面匹配的串进行操作。
考虑到每行第二个括号内的数据,要获取的部分都是在""里面的(不用在意<>,因为要获取的具体数据就是一个“单词”),于是还要构造一个pattern3,用来获取每个单词,于是
pattern3 = ",? ?\"([^\"]+)\"";
这里为了便于解读,有,? ?部分,表示是否有,或空格都进行匹配,当然,这个是没用的,即pattern3也可以这样写,pattern3 = "\"([^\"]+)\"";
^表示非,这里^\"就表示不是"的符号,[^\"]就是表示一个不是"的字符,[^\"]+就表示一个或多个不是"的字符,即这个匹配在匹配一个"后开始匹配,当再遇到"时,就会匹配结束,这时就截取括号()中间的串,对于pattern3,用它来处理上面说过的每行第二个括号获取的串,也就是
/"MovieGraph"/ --> /MovieGraph/ *注意一下pattern3里括号的位置,它匹配的内容并不包括单词两侧的引号。
/"MyFavoriteMovies"/ -->/MyFavoriteMovies/
/"MovieActorRelation", "MovieDirectorRelation", "SameMovieHyperEdge"/ --> /MovieActorRelation/
*注意此时是只匹配一次,每次匹配只负责匹配两个引号,并截取引号中间的串。对于这行数据,再一次匹配,进行判断是否有下一个匹配项,此时就会发生匹配,并进行截取, /"MovieDirectorRelation"/ --> /MovieDirectorRelation/,再匹配截取,就有/"SameMovieHyperEdge"/ --> /SameMovieHyperEdge/
当然,用这个pattern3对另一组串进行匹配,重复循环寻找匹配,就得到了
/"TheShawshankRedemption", "Movie", <"1994", "USA", "9.3">/ --> /TheShawshankRedemption/ /Movie/ /1994/ /USA/ /9.3/
/"SRFD", "MovieDirectorRelation", "-1", "TheShawshankRedemption", "FrankDarabont", "No"/ --> /SRFD/ /MovieDirectorRelation/ /-1/ /TheShawshankRedemption/ /FrankDarabont/ /No/
/"ActorsInSR","SameMovieHyperEdge",{"TimRobbins", "MorganFreeman"}/ --> /ActorsInSR/ /SameMovieHyperEdge/ /TimRobbins/ /MorganFreeman/
由于是按照一行一行的数据进行读入处理的,所以对于每行数据,就可以根据句首的单词来确定应该对=后的串匹配多少次,例如单词是Vertex时,就匹配5次,前两次匹配用于构造一个Vertex(或它的子类)对象,剩下的三次匹配的内容就是这个顶点的属性。这个部分就主要是根据匹配的单词来具体判断,比如匹配到了单词Movie,就可以创建一个Movie对象,它的标签就是TheShawshankRedemption,它的属性就是1994,USA,9.3。通过调用相关的方法即可把这个顶点实例化并加入到图中。类似地即可处理类似的行,只是要注意通过匹配到的字符串来确定该匹配几次,该如何处理这些匹配。这里也可以看到,因为pattern3只是最小化地匹配"单词",所以它对于<>{}这样的字符并不敏感,也就是说这些字符并不会影响pattern3的匹配过程。
下面就说一下如何匹配以及截取字符串。
Pattern p = Pattern.compile(pattern1);
Matcher parse1 = p.matcher("");
p = Pattern.compile(pattern2);
Matcher parse2 = p.matcher("");
会创建模式p,第一行,让p按照pattern1进行设计匹配,第二行,parse1就是按照这样的匹配模式进行匹配,也就是说这时的parse1能够对字符串按照pattern1的格式进行匹配。同理,第三行、第四行使得parse2能够按照pattern2的格式进行匹配。对于让parse1/parse2来匹配指定的字符串,就调用它的reset方法,即parse1.reset(line),就让parse1来匹配字符串line。判断是否匹配到,就用parse.find()方法,如果匹配到了,这个方法就会返回true,否则就返回fasle。如果发生了匹配,可以通过parse1.groupCount()方法来得知这个串能匹配几个括号的内容,即我们需要截取的部分,对于parse1来说,它的格式pattern1包含两个括号,故这个值就是2,group就对应于一个括号,于是要获得第一个括号中的内容,就调用parse1.group(1),这个方法会返回第一个括号里的串,parse1.group(2)就得到第二个括号里的串,类似地,就可以截取到需要的串了。
这里要注意的就是find()方法一定要作为条件判断,因为如果未找到匹配的字符串,parse1就是一个null,如果对parse1调用了group的方法,就会发生异常...你懂的,类似于C/C++使用了空指针。
总的来说,这部分就是注意细节吧,每行数据该如何匹配,以及匹配多少次,以及如何进行字符串的处理,来获得自己需要的数据。熟练使用if/else甚至是switch,就显得格外重要了,滑稽。
为便于对比这部分所说的模式过程,以及防止copy代码,下面附上图(机智脸):



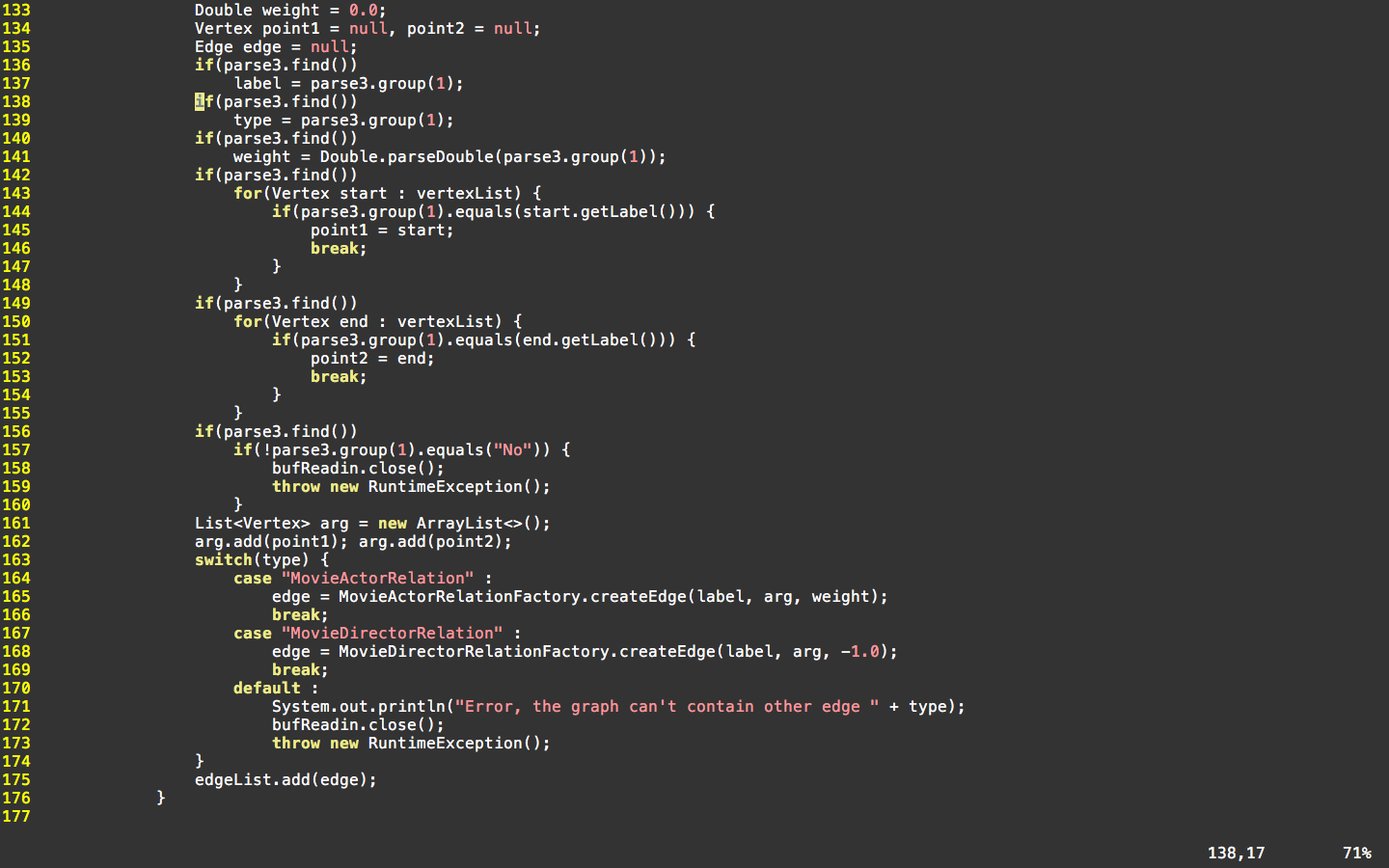

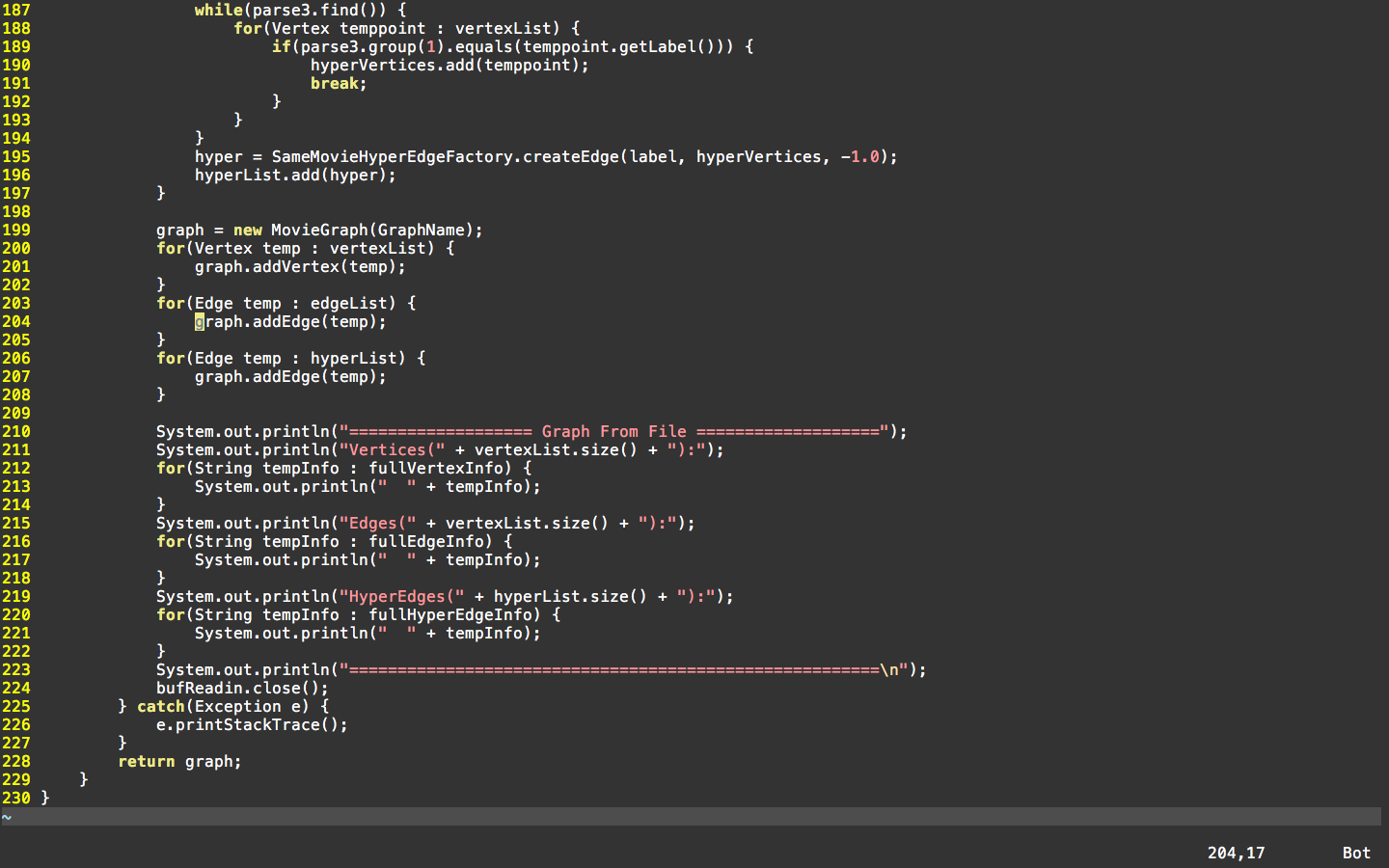
SC.Lab3对于Factory的构建过程(from HIT)的更多相关文章
- (转)Maven学习总结(二)——Maven项目构建过程练习
孤傲苍狼 只为成功找方法,不为失败找借口! Maven学习总结(二)——Maven项目构建过程练习 上一篇只是简单介绍了一下maven入门的一些相关知识,这一篇主要是体验一下Maven高度自动化构建项 ...
- Feign详细构建过程及自定义扩展
探究清楚 feign 的原理,自定义 feign 功能 **spring-cloud-openfeign-core-2.1.1.RELEASE.jar** 中 **HystrixFeign** 的详细 ...
- Qt事件分发机制源码分析之QApplication对象构建过程
我们在新建一个Qt GUI项目时,main函数里会生成类似下面的代码: int main(int argc, char *argv[]) { QApplication application(argc ...
- Gradle的构建过程都不会?带你全面了解Android如何自定义Gradle 插件
目前 Android 工程的默认构建工具为 Gradle,我们在构建 APK 的时候往往会执行 ./gradlew assembleDebug 这样的命令.. 那么这个命令到底代表着什么含义呢?命令的 ...
- 源码解析.Net中Host主机的构建过程
前言 本篇文章着重讲一下在.Net中Host主机的构建过程,依旧延续之前文章的思路,着重讲解其源码,如果有不知道有哪些用法的同学可以点击这里,废话不多说,咱们直接进入正题 Host构建过程 下图是我自 ...
- Mysql主从复制,读写分离(mysql-proxy),双主结构完整构建过程
下面介绍MySQL主从复制,读写分离,双主结构完整构建过程,不涉及过多理论,只有实验和配置的过程. Mysql主从复制(转载请注明出处,博文地址:) 原理是master将改变记录到二进制日志(bina ...
- Android分析应用程序的构建过程
为了方便Android应用开发要求我们Androidproject编制和包装有了更深入的了解,例如,我们知道这是做什么的每一步,境和工具.输入和输出是什么.等等. 在前文<命令行下Android ...
- vue 源码学习(一) 目录结构和构建过程简介
Flow vue框架使用了Flow作为类型检查,来保证项目的可读性和维护性.vue.js的主目录下有Flow的配置.flowconfig文件,还有flow目录,指定了各种自定义类型. 在学习源码前可以 ...
- DOM 操作成本究竟有多高,HTML、CSS构建过程 ,从什么方向出发避免重绘重排)
前言: 2019年!我准备好了 正文:从我接触前端到现在,一直听到的一句话:操作DOM的成本很高,不要轻易去操作DOM.尤其是React.vue等MV*框架的出现,数据驱动视图的模式越发深入人心,jQ ...
随机推荐
- 1、MyBatis框架底层初涉
1.拜年 哈哈,现在是过年了,祝大家新年好. 本来大过年的是不打算碰电脑的,(抢票除外,三疯同学现在还没抢到票,然后突然又延长假期了).现在疫情严重,被堵家里不能出去了.不能为国家做贡献,但是起码不能 ...
- 带你了解MyBatis一二级缓存
在对数据库进行噼里啪啦的查询时,可能存在多次使用相同的SQL语句去查询数据库,并且结果可能还一样,这时,如果不采取一些措施,每次都从数据库查询,会造成一定资源的浪费,所以Mybatis中提供了一级缓存 ...
- docker安装-单机/多机安装
操作系统ubuntu14.04 16.04 v单机安装步骤: #安装httpsca证书 apt-get install apt-transport-https ca-certificates #添 ...
- Spring Boot 使用 CXF 调用 WebService 服务
上一张我们讲到 Spring Boot 开发 WebService 服务,本章研究基于 CXF 调用 WebService.另外本来想写一篇 xfire 作为 client 端来调用 webservi ...
- yaml服务部署示例
apiVersion: apps/v1kind: Deploymentmetadata: name: igirl namespace: chaolai labels: app: igirl ...
- 实际中可能遇到的NAT问题(IPsec)
一.背景介绍:一般我们在实际网络中不是IPSec VPN的时候,都是边界设备连接Internet,然后两个边界设备通过Internet去实现互通,建立VPN,但是,有的运营商在分配IP地址的时候,给我 ...
- Jedis实现频道的订阅,取消订阅
第一步:创建一个发布者 package work; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; i ...
- FTP 上传下载 进度条
11 /// <summary> /// 文件上传 /// </summary> /// <param name="filePath">原路径( ...
- mcast_get_if函数
#include <errno.h> int sockfd_to_family(int); int mcast_get_if(int sockfd) { switch (sockfd_to ...
- linux命令行大全第四章[通配符的使用]
通配符示例 1.创建几个文件及目录 补充创建一个以大写字母开头的文件. 2.1显示所有文件及目录 2.2显示所有以1开头的文件及目录 2.3显示以a开头.txt结尾的文件 2.4显示以e开头,后跟任意 ...