同一条sql insert 有时快有时慢 引发的血案
同一条sql语句,为什么有时插入块,有时插入慢原因剖析
背景:同一条sql ,有时插入时间几毫秒,有时插入时间几十毫秒,为什么?
Sql角度:简单insert
表角度: 一个主键
系统参数角度:
开启了双1 策略。
也就意味着每次事物就会有刷新磁盘
关闭双1 ,设置为 0 100 ,或者 2 100 ,会极大提升性能。这是因为不刷硬盘了,但不能解决为什么时快时慢问题
操作系统角度
iostat -xmd 1 看磁盘

磁盘 不够快啊。 读写0.15M 就使用了7%

来个顺序文件拷贝, 30M 使用 100%。 离散读写更慢了
使用sar -B 1 可以查看页面交换
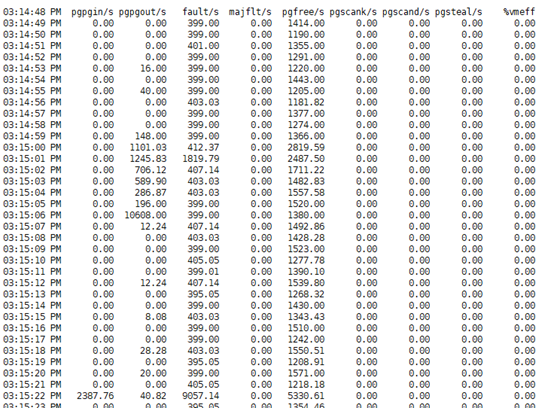
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
majflt/s:每秒钟产生的主缺页数.
pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被kswapd扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
这表示 内存和 swap 或者硬盘 有频繁的数据交换
2 哪个进程使用swap 呢
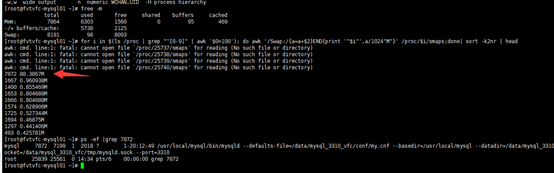

for i in $(ls /proc | grep "^[0-9]" | awk '$0>100'); do awk '/Swap:/{a=a+$2}END{print '"$i"',a/1024"M"}' /proc/$i/smaps;done| sort -k2nr | head

在经过 几个小时后 ,mysql 使用 swap 由 88M 变成了104M , 说明一直在使用和增加的。
问题基本定位
- 首先是磁盘性能不高,顺序写才30M ,离散写会降低10倍
- 其次是mysql又使用了swap 空间,这就使得性能更差
- Mysql 开启了双1 验证,就会等待数据刷磁盘,
磁盘使用频率不稳定,导致了mysql的插入时间会时快时慢
如何解决
- 减少mysql使用swap 方式
把swapness 降为1
sysctl vm.swappiness=1 并且 /etc/sysctl.conf 中设置为1
2 降低内存 innodb_buffer_pool_size =4G 原来6G ,节约一部分内存空
3 开启innodb_numa_interleave = ON 来操作numa
4 更换SSD 或者不用开启双1,改成 2 100
只调整操作系统参数,不更换硬件,依然开启双一,重启mysql之后呢
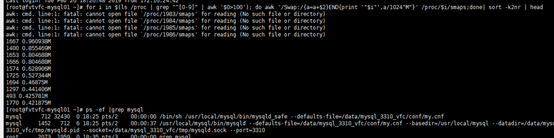
可以看到mysql已经不再使用 swap 空间了
但是因为双一参数的使用,每次事物都会刷磁盘,而这个机械磁盘的性能在随机读写的情况下不稳定。会依然存在时快时慢的问题。
同一条sql insert 有时快有时慢 引发的血案的更多相关文章
- Oracle一条SQL语句时快时慢
今天碰到一个非常奇怪的问题问题,一条SQL语句在PL/SQL developer中很慢,需要9s,问题SQL: SELECT * FROM GG_function_location f WHERE f ...
- 【MySQL】10条SQL优化语句,让你的MySQL数据库跑得更快!
慢SQL消耗了70%~90%的数据库CPU资源: SQL语句独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低: SQL语句可以有不同的写法: 1 不使用子 ...
- 10条SQL优化语句,让你的MySQL数据库跑得更快!
慢SQL消耗了70%~90%的数据库CPU资源: SQL语句独立于程序设计逻辑,相对于对程序源代码的优化,对SQL语句的优化在时间成本和风险上的代价都很低: SQL语句可以有不同的写法: 1 不使用子 ...
- Oracle是如何工作的?实例是如何响应用户请求?一条SQL的执行过程~
Oracle 是如何工作的? Select id,name from t order by id ; – SQL 解析(查看语法是否错误,如果没有错误,分析语意,执行此语句的权限) – 执行计划(OR ...
- MySQL中一条SQL的加锁分析
MySQL中一条SQL的加锁分析 id主键 + RC id唯一索引 + RC id非唯一索引 + RC id无索引 + RC id主键 + RR id唯一索引 + RR id非唯一索引 + RR id ...
- 一条 sql 的执行过程详解
写操作执行过程 如果这条sql是写操作(insert.update.delete),那么大致的过程如下,其中引擎层是属于 InnoDB 存储引擎的,因为InnoDB 是默认的存储引擎,也是主流的,所以 ...
- Mysql 52条SQL语句性能优化策略汇总
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引. 2.应尽量避免在where子句中对字段进行null值判断,创建表时NULL是默认值,但大多数时候应 ...
- 阿里一面,给了几条SQL,问需要执行几次树搜索操作?
前言 有位朋友去阿里面试,他说面试官给了几条查询SQL,问:需要执行几次树搜索操作?我朋友当时是有点懵的,后来冷静思考,才发现就是考索引的几个基础知识点~~ 本文我们分九个索引知识点,一起来探讨一下. ...
- 52 条 SQL 语句性能优化策略,建议收藏
本文会提到 52 条 SQL 语句性能优化策略. 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引. 2.应尽量避免在where子句中对字段进行nul ...
随机推荐
- c#常用控件及简写
c#常用控件及简写
- 【PAT甲级】1112 Stucked Keyboard (20分)(字符串)
题意: 输入一个正整数K(1<K<=100),接着输入一行字符串由小写字母,数字和下划线组成.如果一个字符它每次出现必定连续出现K个,它可能是坏键,找到坏键按照它们出现的顺序输出(相同坏键 ...
- 前端之js基础篇
JavaScript概述 ECMAScript和JavaScript的关系 1996年11月,JavaScript的创造者--Netscape公司,决定将JavaScript提交给国际标准化组织ECM ...
- EFCore.BulkExtensions Demo
最近做了一个项目,当用EF传统的方法执行时,花时4小时左右,修改后,时间大大减少到10分钟,下面是DEMO实例 实体代码: public class UserInfoEntity { [Key] pu ...
- Hadoop架构: 流水线(PipeLine)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 流水线(PipeLine),简单地理解就是客户端向DataNode传输数据(Packet)和接收Dat ...
- CSS-文本溢出省略号表示
前提条件是所引用的元素是块级元素,因为使用了WebKit的CSS扩展属性,该方法适用于WebKit浏览器及移动端 单行溢出处理: .text-overflow{ overflow: hidden; t ...
- Java中正负数的存储方式-正码 反码和补码
Java中正负数的存储方式-正码 反码和补码 正码 我们以int 为例,一个int占用4个byte,32bits 0 存在内存上为 00000000 00000000 00000000 0000000 ...
- Java开发中使用模拟接口moco响应中文时乱码
场景 在开发中需要依赖一些接口,比如需要请求一个返回Json数据的接口,但是返回Json数据的接口要么是没搭建,要么是交互比较复杂. 此时,就可以使用moco来模拟接口返回接口数据,以便开发和测试工作 ...
- 开源分布式系统Druid简谈
介绍 Druid是一个拥有大数据实时查询和分析的高容错.高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析.尤其是当发生代码部署.机器故障以及其他产品系统遇到宕机等情况时,Dru ...
- 【代码学习】PYTHON迭代器
一.迭代器 迭代是访问集合元素的一种方式.迭代器是一个可以记住遍历的位置的对象.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 二.可迭代对象 以直接作用于 ...