R与金钱游戏:美股与ARIMA模型预测
似乎突如其来,似乎合情合理,我们和巴菲特老先生一起亲见了一次,又一次,双一次,叒一次的美股熔断。身处历史的洪流,渺小的我们会不禁发问:那以后呢?还会有叕一次吗?于是就有了这篇记录:利用ARIMA模型来预测美股的走势。
1. Get Train Dataset and Test Dataset
本例子简单地以2020年第一季度的道指的收盘价为数据集(数据来源雅虎财经),将前面95%的数据用作本次预测的训练集,后面5%的数据用作本次预测的测试集。
library(quantmod)
stock <- getSymbols("^DJI", from="2020-01-01", from="2020-03-31", auto.assign=FALSE)
names(stock) <- c("Open", "High", "Low", "Close", "Volume", "Adjusted")
stock <- stock$Close
stock <- na.omit(stock)
train.id <- 1: (0.95*length(stock))
train <- stock[train.id]
test <- stock[-train.id]
2. Stationarity Test
由于ARIMA预测要求输入数据为平稳时间序列。如果输入数据为非平稳时间序列,则需要对数据进行平稳化处理。识别数据集是否为平稳时间序列,本例子用了两种方法:1)简单粗暴的观察法;2)白噪声检验。
其实对于多次熔断向下再向下的道指来说,撇开各种观察和检验的方法,我们都知道他一定是非平稳时间序列了。下面两种方法就是打个版:当我们遇到不太明显的时间序列时可以怎么做?
2.1 Observational Method
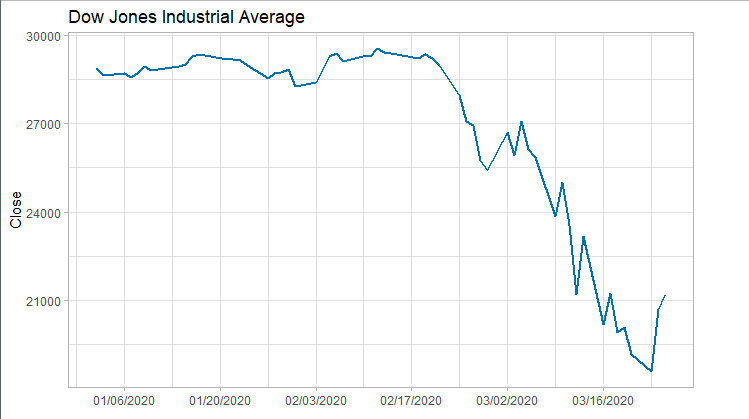
下图断崖式下降的曲线表明训练集为非平稳时间序列。
library(ggplot2)
library(scales)
plot<-ggplot(data=train) +
geom_line(aes(x=as.Date(Index), y=Close), size=1, color="#0072B2")+
scale_x_date(labels=date_format("%m/%d/%Y"), breaks=date_breaks("2 weeks"))+
ggtitle("Dow Jones Industrial Average") +
xlab("")+
theme_light()
print(plot)
2.2 Ljung‐Box Statistics Test
利用 Ljung–Box test 得到 p-value = 2.2e-16 < 0.05, 由此拒绝时间序列为白噪声的假设。
Box.test(train, lag=1, type = "Ljung-Box")
3. Differencing
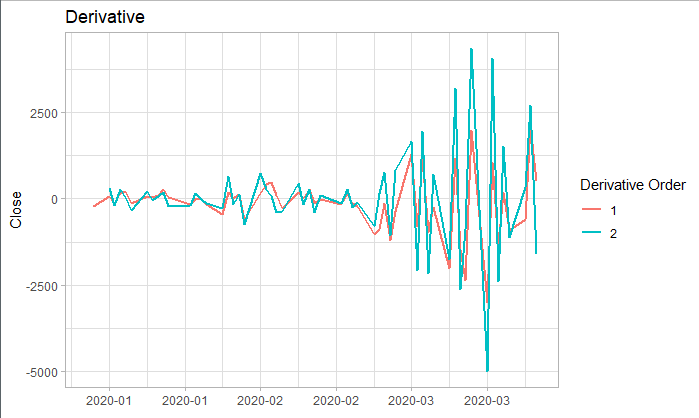
上述我们可知本训练集为非平稳时间序列,所以我们利用差分对它进行平稳化处理。对训练集分别进行一阶差分和二阶差分后,从下图其实并不能很容易看出一阶差分以及二阶差分是否为平稳序列。于是我们对其进行了ADF检验。从检验结果可知:
原序列:p-value = 0.5336 > 0.05,拒绝它是平稳序列的假设;
一阶差分:p-value = 0.4495 > 0.05,拒绝它是平稳序列的假设;
二阶差分:p-value = 0.01 所以我们将利用其二阶差分序列进行ARIMA预测。
library("tseries")
train.diff1 <- diff(train, lag = 1, differences = 1)
train.diff2 <- diff(train, lag = 1, differences = 2)
adf.test(train)
adf.test(na.exclude(train.diff1))
adf.test(na.exclude(train.diff2))
4. ARIMA Model
4.1 Choosing the order
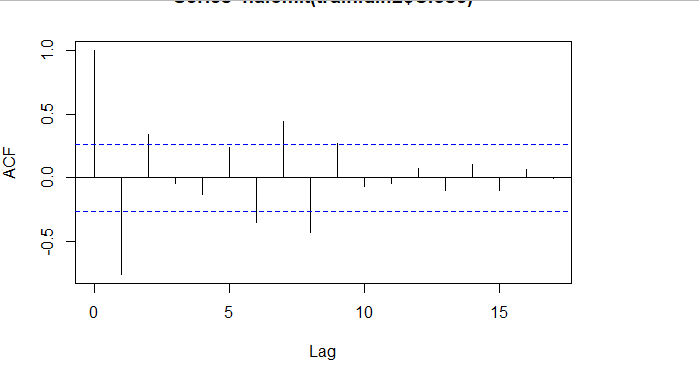
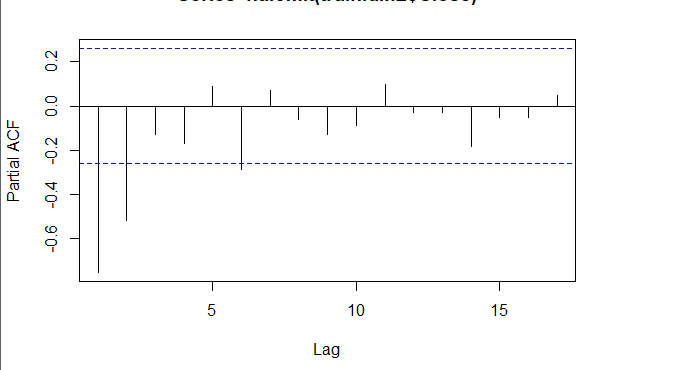
当我们确定用二阶差分序列进行预测后,则需要对模型进行定阶。如下图所示,对于ACF,滞后1-2阶在2倍标准差外,所以q=2;对于PACF,同样也是滞后1-2阶都在2倍标准差外,所以p=2,所以将会选择模型ARIMA(2,2,2)。
acf <- acf(na.omit(train.data.diff2$Close), plot=TRUE)
pacf <- pacf(na.omit(train.data.diff2$Close), plot=TRUE)
为了保证选择的模型是最优的,建议可以多选择接近的模型,然后根据AIC准则或者BIC准则选取最优的模型。比如利用自动定阶的方法,得出一个模型ARIMA(1,1,0)
library(forecast)
auto.arima(train.data,trace=TRUE) #Best model is ARIMA(1,1,0)
经过比较发现还是模型ARIMA(2,2,2)较优:
data.autofit<-arima(train.data,order=c(1,1,0))
AIC(data.autofit)
BIC(data.autofit)
data.fit<-arima(train.data,order=c(2,2,2))
AIC(data.fit)
BIC(data.fit)
| Model | AIC | BIC |
|---|---|---|
| ARIMA(1,1,0) | 930.5894 | 934.6755 |
| ARIMA(2,2,2) | 919.8881 | 930.0149 |
4.2 Model Validation
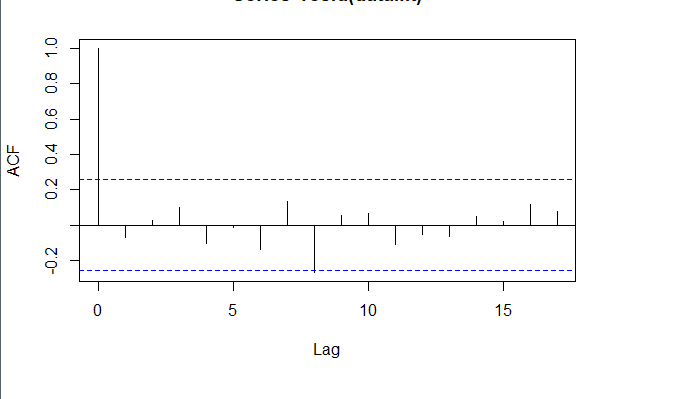
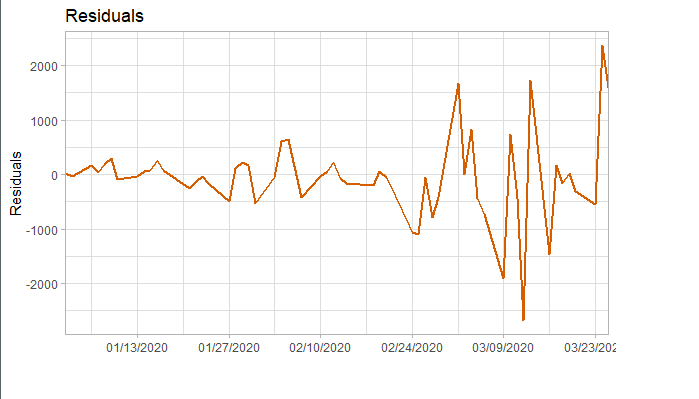
对拟合残差进行白噪声检验,得到p-value = 0.8221 > 0.05,而且acf在lag=1后迅速减小,可得残差为白噪声。
forecast <-forecast(data.fit, h=4, level=c(99.5))
forecast.data <- data.frame("Date"=index(train), "Input"=forecast$x, "Fitted"=forecast$fitted, "Residuals"=forecast$residuals)
acf(forecast.data$Residuals)
Box.test(forecast.data$Residuals, lag=sqrt(length(forecast.data$Residuals)), type = "Ljung-Box")
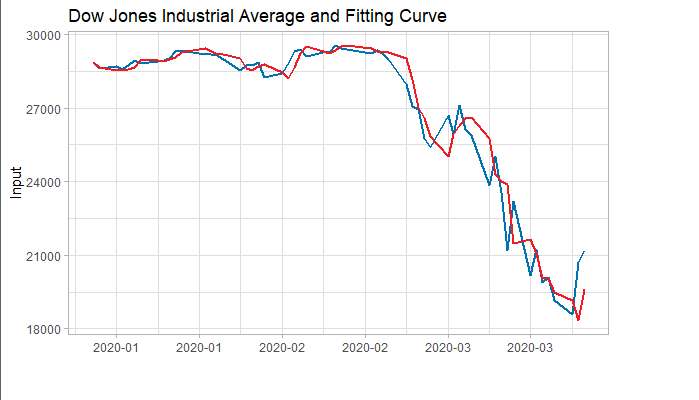
我们将训练集数据和拟合数据同时画在图上,可以看到两者的差别是在可接受范围的。
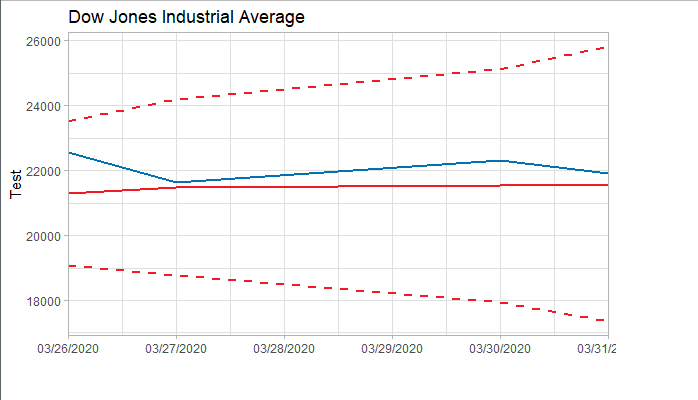
4.3 Forecast and Test Data
将预测结果与测试集对比,两者的最大相对误差为 0.056,可见模型是表达充分的,预测结果良好。
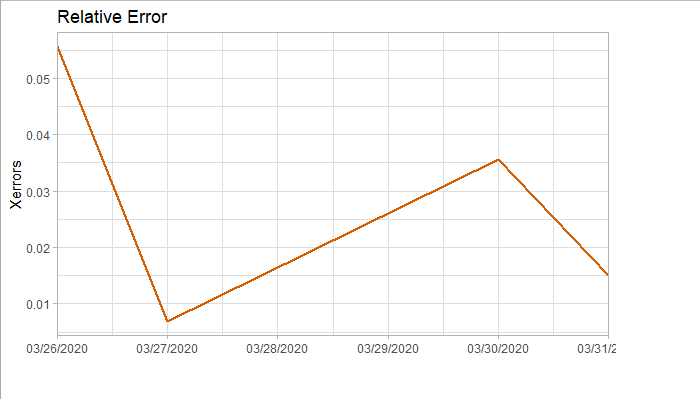
5. Forecast
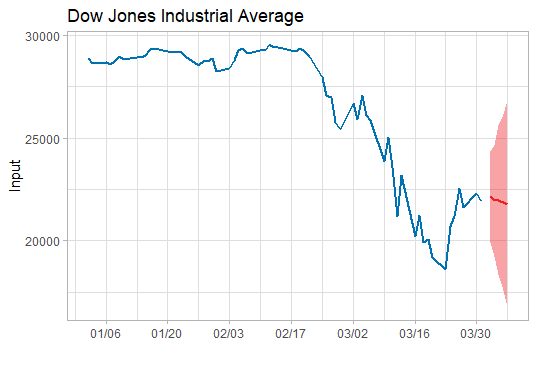
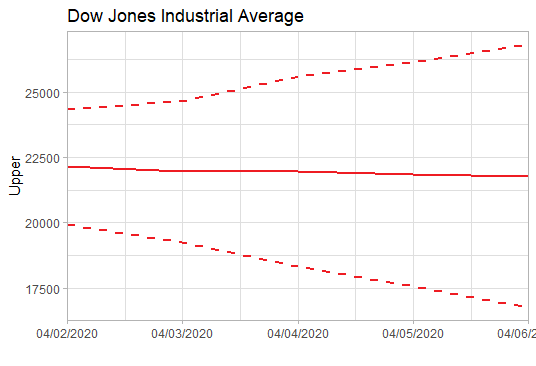
上述已经找到合适的预测模型了, 于是就可以用这个模型ARIMA(2,2,2)来预测未来5天的道指走势了。预测未来道指将在22000波动,均值微跌(呈下跌趋势),波动范围为16000-26000左右。简单说,这个模型的预测是前景不容乐观。
data.forecast<-arima(stock,order=c(2,2,2))
newforecast<-forecast(data.forecast, h=5, level=c(99.5))
R与金钱游戏:美股与ARIMA模型预测的更多相关文章
- 【R实践】时间序列分析之ARIMA模型预测___R篇
时间序列分析之ARIMA模型预测__R篇 之前一直用SAS做ARIMA模型预测,今天尝试用了一下R,发现灵活度更高,结果输出也更直观.现在记录一下如何用R分析ARIMA模型. 1. 处理数据 1.1. ...
- R与金钱游戏:均线黄金交叉2
从上一篇分析已经得知均线黄金交叉原则并不适用于震荡期,那有什么办法可以规避震荡期呢或者说有什么办法可以减少无脑跟的损失?我们继续玩一下. Required Packages library(quant ...
- 用R做时间序列分析之ARIMA模型预测
昨天刚刚把导入数据弄好,今天迫不及待试试怎么做预测,网上找的帖子跟着弄的. 第一步.对原始数据进行分析 一.ARIMA预测时间序列 指数平滑法对于预测来说是非常有帮助的,而且它对时间序列上面连续的值之 ...
- R与金钱游戏:均线黄金交叉1
双11临近的我发现自己真的很穷很穷很穷(重要的问题说三遍)-- 贫穷催人上进.于是我就寻思着在空闲时间自己捣鼓一下钱生钱的游戏是怎么玩的,毕竟就算注定做韭菜也要做一根有知识有理想的韭菜. 第一个要玩的 ...
- R语言的ARIMA模型预测
R通过RODBC连接数据库 stats包中的st函数建立时间序列 funitRoot包中的unitrootTest函数检验单位根 forecast包中的函数进行预测 差分用timeSeries包中di ...
- 不知道怎么改的尴尬R语言的ARIMA模型预测
数据还有很多没弄好,程序还没弄完全好. > read.xlsx("H:/ProjectPaper/论文/1.xlsx","Sheet1") > it ...
- Redhat 5.8系统安装R语言作Arima模型预测
请见Github博客:http://wuxichen.github.io/Myblog/timeseries/2014/09/02/RJavaonLinux.html
- 时间序列分析之ARIMA模型预测__R篇
http://www.cnblogs.com/bicoffee/p/3838049.html
- ARIMA模型——本质上是error和t-?时刻数据差分的线性模型!!!如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理!ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数
https://www.cnblogs.com/bradleon/p/6827109.html 文章里写得非常好,需详细看.尤其是arima的举例! 可以看到:ARIMA本质上是error和t-?时刻 ...
随机推荐
- 奉上简单的.Net后端开发模板
假定一个场景,开始做开发的你,领导走到你的面前说道:"小伙子,看了简历和最近的工作表现,很不错,现在交给一个任务,开发一个简单的CMS后端接口吧,前端有人配合你",当时你内心读白: ...
- 先导篇:SpringCloud介绍篇
1.什么是SpringCloud Spring Cloud是一系列框架的有序集合.它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册.配置中心.消息总线.负载 ...
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
- 报错: raise ImproperlyConfigured('mysqlclient 1.3.13 or newer is required; you have %s.' % Database.__version__)
Django2.0同步Mysql数据库时出现的问题 执行 python manage.py makemigrations 报错 # 报错位置 File "G:\python\lib\site ...
- go结构体继承组合和匿名字段
1.结构体方法 go不是纯粹的面向对象的,在go里面函数是一等公民,但是go也有结构体实现类似java一样类的功能来提供抽象.结构体的方法分为值方法和指针方法,前者在方法中做的改变不会改变调用的实例对 ...
- 测试 - 某网站ACCESS数据库注入漏洞
元宵节 团团圆圆总少不了一篇文 测试是否有注入 测试数据库类型 后面不用注释猜到可能是access 验证一下 这里说一下MySQL和ACCESS以及MSSQL的判断语句 MySQL:and len ...
- 安卓 打飞机 app 开发 第一篇
先上效果图 其实,当时刚买 htc G8 的时候(那时北京的房价还是6千一平),安卓2.1 ,2.3 的时候就已经有安卓方面的开发的兴趣,但后来就没有弄过... today 突然想起来,手机上连个游戏 ...
- RStudio终端操作
转于:https://support.rstudio.com/hc/en-us/articles/115010737148-Using-the-RStudio-Terminal#send 原文是英文版 ...
- python常用软件包
redis数据库: 链接:https://pan.baidu.com/s/1X_ndCj0scF2WZd2FPLRKag 提取码:e3zm git安装包: 链接:https://pan.baidu.c ...
- burpsuit之Spider、Scanner、Intruder模块
1.spider模块 1.spider模块介绍 被动爬网:(被动爬网获得的链接是手动爬网的时候返回页面的信息中分析发现超链接) 对于爬网的时候遇到HTML表单如何操作: 需要表单身份认证时如何操作(默 ...