【R实践】时间序列分析之ARIMA模型预测___R篇
时间序列分析之ARIMA模型预测__R篇
之前一直用SAS做ARIMA模型预测,今天尝试用了一下R,发现灵活度更高,结果输出也更直观。现在记录一下如何用R分析ARIMA模型。
1. 处理数据
1.1. 导入forecast包
forecast包是一个封装的ARIMA统计软件包,在默认情况下,R没有预装forecast包,因此需要先安装该包
> install.packages("forecast')
导入依赖包zoo,再导入forecast包
> library("zoo")
> library("forecast")
1.2. 导入数据
博主使用的数据是一组航空公司的销售数据,可在此下载数据:airline.txt,共有132条数据,是以月为单位的销售数据。

> airline <- read.table("airline.txt")
> airline
V1 V2
1 1 112
2 2 118
3 3 132
4 4 129
5 5 121
6 6 135
7 7 148
8 8 148
9 9 136
10 10 119
(........)
1.3. 将数据转化为时间序列格式(ts)
由于将数据转化为时间序列格式,我们并不需要时间字段,因此只取airline数据的第二列,即销售数据,又因为该数据是以月为单位的,因此Period是12。
> airline2 <- ariline[2]
> airts <- ts(airline2,start=1,frequency=12)
2. 识别模型
2.1. 查看趋势图
> plot.ts(airts)
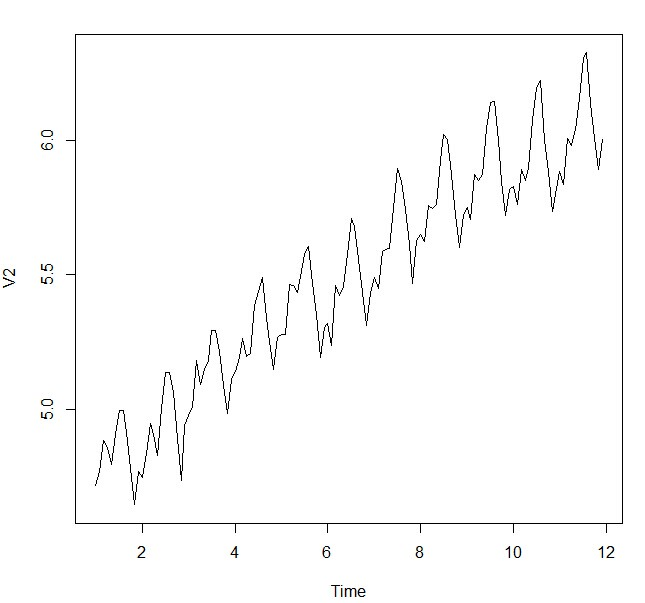
由图可见,该序列还不平稳,先做一次Log平滑,再做一次差分:
> airlog <- log(airts)
> airdiff <- diff(airlog, differences=1)
> plot.ts(airdiff)
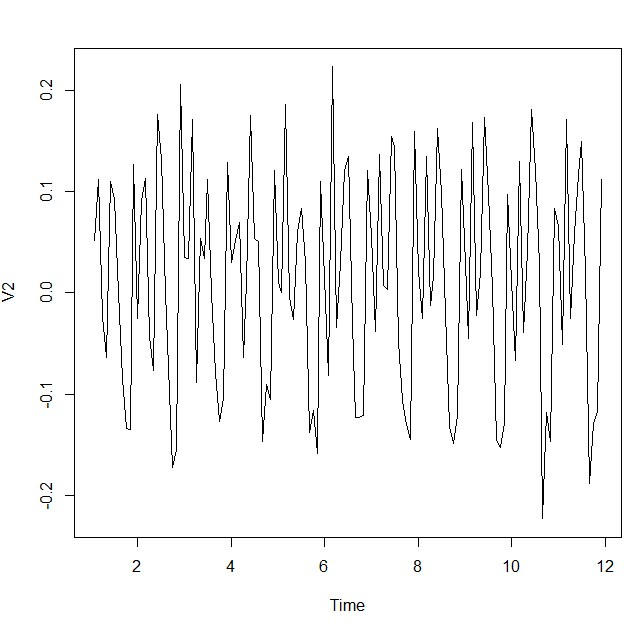
这次看上去就比较平稳了,现在看看ACF和PACF的结果
2.2. 查看ACF和PACF
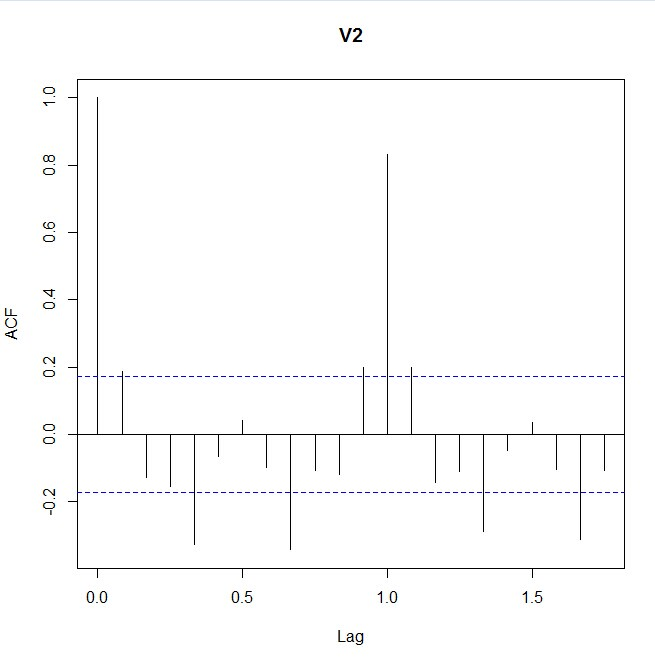
> acf(airdff, lag.max=30)
> acf(airdff, lag.max=30,plot=FALSE)
Autocorrelations of series ‘airdiff’, by lag
0.0000 0.0833 0.1667 0.2500 0.3333 0.4167 0.5000 0.5833 0.6667 0.7500 0.83331.000 0.188 -0.127 -0.154 -0.326 -0.066 0.041 -0.098 -0.343 -0.109 -0.1200.9167 1.0000 1.0833 1.1667 1.2500 1.3333 1.4167 1.5000 1.5833 1.6667 1.75000.199 0.833 0.198 -0.143 -0.110 -0.288 -0.046 0.036 -0.104 -0.313 -0.1061.8333 1.9167 2.0000 2.0833 2.1667 2.2500 2.3333 2.4167 2.5000
-0.085 0.185 0.714 0.175 -0.126 -0.077 -0.214 -0.046 0.029
> pacf(airdff, lag.max=30)
> pacf(airdff, lag.max=30,plot=FALSE)
Partial autocorrelations of series ‘airdiff’, by lag
0.0833 0.1667 0.2500 0.3333 0.4167 0.5000 0.5833 0.6667 0.7500 0.8333 0.91670.188 -0.169 -0.101 -0.317 0.018 -0.072 -0.199 -0.509 -0.171 -0.553 -0.3001.0000 1.0833 1.1667 1.2500 1.3333 1.4167 1.5000 1.5833 1.6667 1.7500 1.83330.551 0.010 -0.200 0.164 -0.052 -0.037 -0.108 0.094 0.005 -0.095 -0.0011.9167 2.0000 2.0833 2.1667 2.2500 2.3333 2.4167 2.50000.057 -0.074 -0.048 0.024 0.073 0.047 0.010 0.033
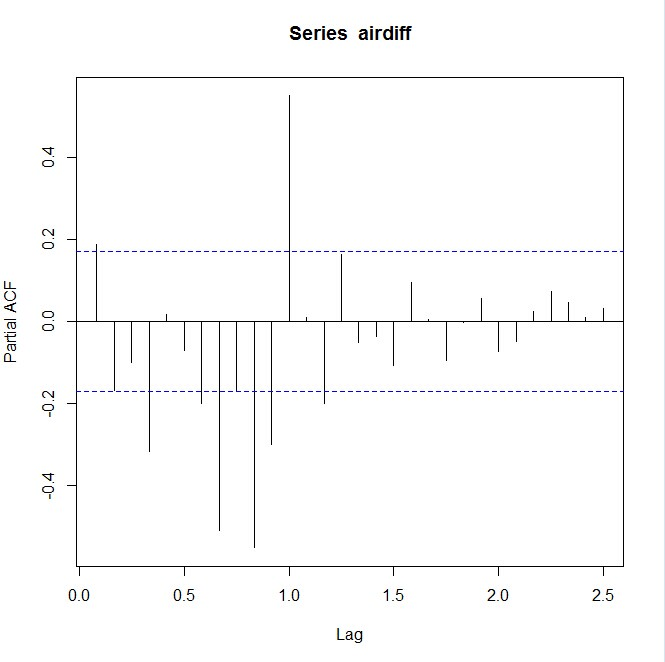
从ACF和PACF可以看出来,该序列在lag=12和lag=24处有明显的spike,说明该序列需要再做一次diff=12的差分。且PACF比ACF呈现更明显的指数平滑的趋势,因此先猜测ARIMA模型为:ARIMA(0,1,1)(0,1,1)[12].
2.3. 利用auto.arima
> auto.arima(airlog,trace=T) ARIMA(2,1,2)(1,1,1)[12] : -354.4719
ARIMA(0,1,0)(0,1,0)[12] : -316.8213
ARIMA(1,1,0)(1,1,0)[12] : -356.4353
ARIMA(0,1,1)(0,1,1)[12] : -359.7679
ARIMA(0,1,1)(1,1,1)[12] : -354.9069
ARIMA(0,1,1)(0,1,0)[12] : -327.5759
ARIMA(0,1,1)(0,1,2)[12] : -357.6861
ARIMA(0,1,1)(1,1,2)[12] : -363.2418
ARIMA(1,1,1)(1,1,2)[12] : -359.6535
ARIMA(0,1,0)(1,1,2)[12] : -346.1537
ARIMA(0,1,2)(1,1,2)[12] : -361.1765
ARIMA(1,1,2)(1,1,2)[12] : 1e+20
ARIMA(0,1,1)(1,1,2)[12] : -363.2418
ARIMA(0,1,1)(2,1,2)[12] : -368.8244
ARIMA(0,1,1)(2,1,1)[12] : -368.1761
ARIMA(1,1,1)(2,1,2)[12] : -367.0903
ARIMA(0,1,0)(2,1,2)[12] : -363.7024
ARIMA(0,1,2)(2,1,2)[12] : -366.6877
ARIMA(1,1,2)(2,1,2)[12] : 1e+20
ARIMA(0,1,1)(2,1,2)[12] : -368.8244 Best model: ARIMA(0,1,1)(2,1,2)[12] Series: airlog
ARIMA(0,1,1)(2,1,2)[12] Coefficients:
ma1 sar1 sar2 sma1 sma2
-0.2710 -0.4764 -0.1066 -0.0098 -0.1987
s.e. 0.0995 0.1432 0.1087 0.1567 0.1130 sigma^2 estimated as 0.001188: log likelihood=231.88
AIC=-369.57 AICc=-368.82 BIC=-352.9
auto.arima提供的最佳模型为ARIMA(0,1,1)(2,1,2)[12],我们可以同时测试两个模型,看看哪个更适合。
3. 参数估计
> airarima1 <- arima(airlog,order=c(0,1,1),seasonal=list(order=c(0,1,1),period=12),method="ML")
> airarima1
Series: airlog
ARIMA(0,1,1)(0,1,1)[12] Coefficients:
ma1 sma1
-0.3484 -0.5622
s.e. 0.0943 0.0774 sigma^2 estimated as 0.001313: log likelihood=223.63
AIC=-441.26 AICc=-441.05 BIC=-432.92
> airarima2 <- arima(airlog,order=c(0,1,1),seasonal=list(order=c(2,1,2),period=12),method="ML")
> airarima2
Series: airlog
ARIMA(0,1,1)(2,1,2)[12] Coefficients:
ma1 sar1 sar2 sma1 sma2
-0.3546 1.0614 -0.1211 -1.9130 0.9962
s.e. 0.0995 0.1094 0.1844 0.3887 0.3812 sigma^2 estimated as 0.0009811: log likelihood=225.56
AIC=-439.12 AICc=-438.37 BIC=-422.44
两个ARIMA模型都采用极大似然方法估计,计算系数对应的t值:
ARIMA(0,1,1)(0,1,1)[12] :t(ma1)=-39.1791, t(sma1)=-93.8445
ARIMA(0,1,1)(2,1,2)[12] : t(ma1)=-35.8173,t(sar1)=88.68383,t(sar2)=-3.56141,t(sma1)=-12.6615,t(sma2)= 6.855526
可见两个模型的系数都是显著的,而ARIMA(0,1,1)(0,1,1)[12]的AIC和BIC比ARIMA(0,1,1)(2,1,2)[12]的要小,因此选择模型ARIMA(0,1,1)(0,1,1)[12]。
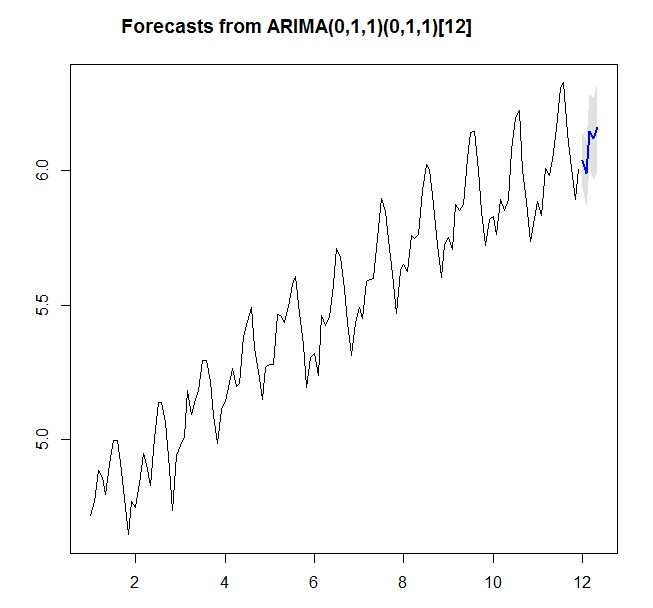
4. 预测
预测五年后航空公司的销售额:
> airforecast <- forecast.Arima(airarima1,h=5,level=c(99.5))
> airforecast
Point Forecast Lo 99.5 Hi 99.5
Jan 12 6.038649 5.936951 6.140348
Feb 12 5.988762 5.867380 6.110143
Mar 12 6.145428 6.007137 6.283719
Apr 12 6.118993 5.965646 6.272340
May 12 6.159657 5.992605 6.326709 > plot.forecast(airforecast)
【R实践】时间序列分析之ARIMA模型预测___R篇的更多相关文章
- 用R做时间序列分析之ARIMA模型预测
昨天刚刚把导入数据弄好,今天迫不及待试试怎么做预测,网上找的帖子跟着弄的. 第一步.对原始数据进行分析 一.ARIMA预测时间序列 指数平滑法对于预测来说是非常有帮助的,而且它对时间序列上面连续的值之 ...
- 时间序列分析之ARIMA模型预测__R篇
http://www.cnblogs.com/bicoffee/p/3838049.html
- R与金钱游戏:美股与ARIMA模型预测
似乎突如其来,似乎合情合理,我们和巴菲特老先生一起亲见了一次,又一次,双一次,叒一次的美股熔断.身处历史的洪流,渺小的我们会不禁发问:那以后呢?还会有叕一次吗?于是就有了这篇记录:利用ARIMA模型来 ...
- [python] 时间序列分析之ARIMA
1 时间序列与时间序列分析 在生产和科学研究中,对某一个或者一组变量 进行观察测量,将在一系列时刻 所得到的离散数字组成的序列集合,称之为时间序列. 时间序列分析是根据系统观察得到的时间序列数据, ...
- 基于 Keras 的 LSTM 时间序列分析——以苹果股价预测为例
简介 时间序列简单的说就是各时间点上形成的数值序列,时间序列分析就是通过观察历史数据预测未来的值.预测未来股价走势是一个再好不过的例子了.在本文中,我们将看到如何在递归神经网络的帮助下执行时间序列分析 ...
- R语言--时间序列分析步骤
大白. (1)根据趋势定差分 plot(lostjob,type="b") 查看图像总体趋势,确定如何差分 df1 = diff(lostjob) d=1阶差分 s4_df1=d ...
- R语言的ARIMA模型预测
R通过RODBC连接数据库 stats包中的st函数建立时间序列 funitRoot包中的unitrootTest函数检验单位根 forecast包中的函数进行预测 差分用timeSeries包中di ...
- 不知道怎么改的尴尬R语言的ARIMA模型预测
数据还有很多没弄好,程序还没弄完全好. > read.xlsx("H:/ProjectPaper/论文/1.xlsx","Sheet1") > it ...
- Redhat 5.8系统安装R语言作Arima模型预测
请见Github博客:http://wuxichen.github.io/Myblog/timeseries/2014/09/02/RJavaonLinux.html
随机推荐
- Centos系统修改hostname
1.用命令临时修改 hostname oier 这样,服务器的hostname就变成oier了,但是重启之后会变回去 2.编辑配置文件永久修改 vi /etc/sysconfig/network HO ...
- jquery中:input和input的区别
:input表示选择表单中的input,select,textarea,button元素, input仅仅选择input元素. <button>和<input type=" ...
- Python 入门学习笔记
安装和运行 官网下载安装包https://www.python.org/downloads/mac-osx/下载完直接安装即可 运行打开 terminal,输入命令 python,进入 python ...
- Python基础(9)三元表达式、列表解析、生成器表达式
一.三元表达式 三元运算,是对简单的条件语句的缩写. # if条件语句 if x > f: print(x) else: print(y) # 条件成立左边,不成立右边 x if x > ...
- AtCoder Regular Contest 075 D Widespread
题目传送门 这道题其实二分一下答案就okay了的 不过LL什么的有时候忘了加 被卡了下 #include<cstdio> #include<cstring> #include& ...
- python3 time、random、hashlib模块
一.时间模块时间的几种形式:时间戳,结构化时间,字符串时间 import time print(time.time()) # 仅仅是当前时间的时间戳 float print(time.localtim ...
- 最简单的DLL
静态链接库与动态链接库都是共享代码的方式,如果采用静态链接库,则无论你愿不愿意,lib 中的指令都全部被直接包含在最终生成的 EXE 文件中了.但是若使用 DLL,该 DLL 不必被包含在最终 EXE ...
- Java坦克大战 (六) 之增加可玩性
本文来自:小易博客专栏.转载请注明出处:http://blog.csdn.net/oldinaction 在此小易将坦克大战这个项目分为几个版本,以此对J2SE的知识进行回顾和总结,希望这样也能给刚学 ...
- springboot 全局异常处理
springboot 全局异常处理 研究了半天springboot的全局异常处理,虽然还是需要再多整理一下,但是对于常见的404和500足以可以区分开,能够根据这两个异常分别处理 首先配置视图解析路径 ...
- Javascript传参参考
可参考的细节: <!doctype html> <html lang="en"> <head> <meta charset="U ...