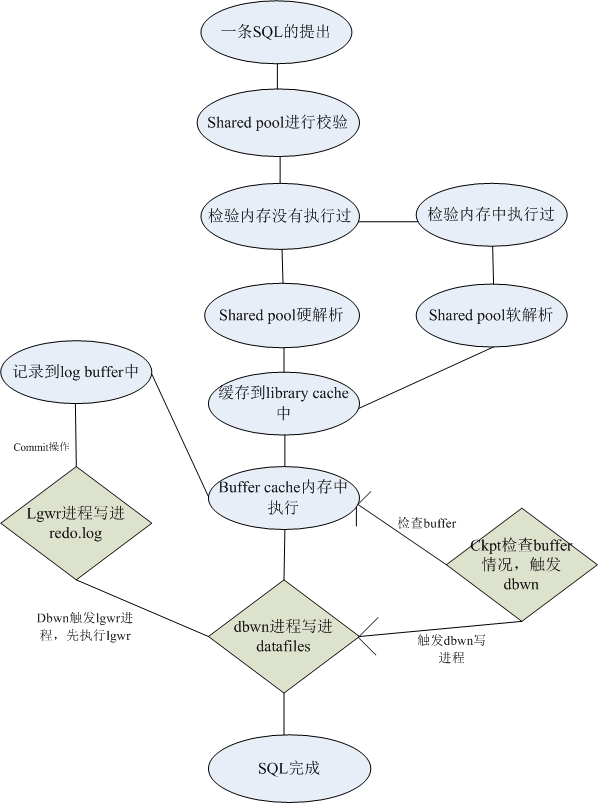
一条SQL在内存结构与后台进程工作机制
oracle服务器由数据库以及实例组成,数据库由数据文件,控制文件等物理文件组成,实例是由内存结构+后台进程组成,实例又可以看做连接数据库的方式,在我看来就好比一家公司,实例就是一个决策的办公室,大大小小的决定都要从这个办公室解决。
实例分成内存结构以及后台进程部分。
内存结构主要可以分为:共享池(shared pool),数据库高速缓冲区(data buffer cache),重做日志缓冲区(Redo Log Buffer Cache)。
三大内存池:
共享池(shared pool):用来存放一些共享的资源,比如sql,pl/sql,数据字典一些信息,一条SQL的执行首先在shared pool中进行校验,解析,然后在执行。它主要由两个内存结构区域构成:Library cache和Data dictionary cache,共享池会对执行的sql进行校验,然后解析,最后执行,这里提到两个概念:
硬解析:没有被执行过的sql,会在shared pool中进行校验,然后解析,最后执行
1.查看语法是否错误
2.查看数据字典,检查SQL语句中涉及的对象和列是否存在
3.通过优化器创建一个最佳的执行计划
4.将该游标所产生的执行计划,SQL文本缓存到Library cache的hash中
软解析:将相同的sql存放在library cache中,减少硬解析一个或多个步骤,从而减少大量的资源使用。
所以写sql最好加上变量,减少硬解析,也就减少了IO的开销。
修改共享池的大小:ALTER SYSTEM SET SHARED_POOL_SIZE = 64M;
数据库高速缓冲区(data buffer cache):SGA的一部分,oracle利用buffer cache来管理data block数据块(8k),及用户使用过的数据,比如用户查询到磁盘上的数据就存储在这,修改数据时,同时保存数据库被修改前(前镜像)和修改后(后镜像),避免了对数据文件的直接操作,cache的最终目的还是减少磁盘的IO。一条SQL的执行,首先要将数据文件中的数据提到buffer cache中来修改,然后在buffer cache中修改完,再将这些脏数据写回数据文件中。
工作机制:假设查询到,或者更改的数据都已放在了buffer cache中,buffer cache的存量就那么大,怎么保证buffer cache不断更新呢?cache利用链表来实现数据块的快速定位,一个数据块8K大小,一次读取会有若干个数据块,缓冲区则是利用LRU(最近最少使用)算法来进行清除以前没用过的数据块,一次来释放内存。从而保证了一致性。
脏数据:一条更新sql,需要把数据文件的数据提到内存中来修改,但是还没有写回数据文件,这时在buffer cache中的这些已经更改过的不一致数据就叫做脏数据。
重做日志缓冲区(Redo Log Buffer Cache):记录一些ddl,dml操作的缓冲区,用来缓存对于数据块的所有修改。如果正在执行一条sql语句,在内存中已经修改完成,但是还没有将这些脏数据写进数据文件中,但是断电了,内存中谢谢东西被释放掉了,这些东西就真的没了,但是有了log buffer,他会先记录,将这些操作记录下来,下次重新开机的时候,这些操作内存可以在log buffer中找到,重新执行一遍,相当于数据没有丢,还是保证了数据的一致性。
后台主要五大进程:
dbwn(写进程):顾名意义,oracle中有很多后台进程,写进程是很重要的,就是把脏数据写进磁盘的一个过程。
1.脏数据阈值达到25%时
2.扫描到整个buffer cache没有空闲时
3.ddl,dml操作时
4.表空间脱机
5.热备命令时
这些都会触发dbwn写进程
lgwr(log日志写进程):将log buffer缓冲区中记录的操作写入物理文件,日志文件中去,所以这个操作必须比较快速切频繁才能保证数据的一致性,同时也必须在dbwn操作之前触发lgwr,否则数据文件已经写进去了,日志文件还没有记录是不行的。
1.commit;
2.log buffer达到内存的三分之一时
3.dbwn写进脏数据之前
4.每隔3秒
ckpt(检查点进程):检查点的主要任务就是督促dbwn刷新脏块,也类似一个scn号,记录一个时间点的行为
1.调度数据写
2.会将自己完成的检查点写到数据文件头
3.把已经完成的检查点写进控制文件中
smon(系统进程):system monitior,系统监控,数据库的主进程,系统可以根据smon进程来判断oracle是否启动
1.系统监控管理,定期合并空闲,回收临时段
2.做实例的恢复,前滚,后滚,释放资源
pmon(监控进程):监控其他非核心进程,释放垃圾进程。如果你的进程卡死了,断掉了,pmon会帮你释放挂掉进程占得资源。
一条SQl的执行过程:
一条SQL在内存结构与后台进程工作机制的更多相关文章
- 巩固java(二)----JVM堆内存结构及垃圾回收机制
前言: 我们在运行程序时,有时会碰到内存溢出(OutOfMemoryError)的问题,为了解决这种问题,我们有必要了解JVM的内存结构和垃圾回收机制. 正文: 1.JVM堆内存结构 ...
- JVM内存结构 JVM的类加载机制
JVM内存结构: 1.java虚拟机栈:存放的是对象的引用(指针)和局部变量 2.程序计数器:每个线程都有一个程序计数器,跟踪代码运行到哪个位置了 3.堆:对象.数组 4.方法区:字节流(字节码文件) ...
- JVM结构、GC工作机制详解
JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知,JVM主要包括四个部分 ...
- JVM结构、GC工作机制详解(转)
原文地址:http://blog.csdn.NET/tonytfjing/article/details/44278233 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JV ...
- 【转载】JVM结构、GC工作机制详解
文章主要分为以下四个部分 JVM结构.内存分配.垃圾回收算法.垃圾收集器.下面我们一一来看. 一.JVM结构 根据<java虚拟机规范>规定,JVM的基本结构一般如下图所示: 从左图可知, ...
- 共享内存shared pool (5):详解一条SQL在library cache中解析
前面介绍的 shared pool,library cache结构,都是为了说明一条SQL是如何被解析的.先看下面的图: 图中涉及的各结构简单介绍 父HANDLE,里面有父游标堆0的地址.. 父游标堆 ...
- Oracle之内存结构(SGA、PGA)
一.内存结构 SGA(System Global Area):由所有服务进程和后台进程共享: PGA(Program Global Area):由每个服务进程.后台进程专有:每个进程都有一个PGA. ...
- oracle 初探内存结构
数据库的存储机构 分为 逻辑存储结构 和 物理存储结构 逻辑存储结构: 数据库.表空间.段.区.块 物理存储结构: 数据库.控制文件.数据文件.初始化参数文件.OS块等. 一个区只能在 ...
- Oracle内存结构:SGA PGA UGA
内存结构是oracle数据库最重要的组成部分之一,在数据库中的操作或多或少都会依赖到内存,是影响数据库性能的重要因素Oracle数据库中包括3个基本的内存结构: 一. 系统全局区 (System G ...
随机推荐
- dbgview 在windows 10 中关闭后再次打开时无法“capture kernel”
DbgView 是一个免费的用于抓取log 的工具,可以捕获并输出OutputDebugString()函数的输出,以及输出windows driver 中dbgprint 的log,对于window ...
- 系统学习Javaweb11----综合案例1
学习内容: 1.综合案例-需求说明 2.综合案例-需求分析 3.综合案例-需求实现-网页顶部部分 4.案例-需求实现-网页导航条 5.综合案例-需求实现-网页主体部分 6.综合案例-需求实现-网页主体 ...
- Flink(三) —— 运行架构
Flink运行时组件 JobManager 作业管理器 TaskManager 任务管理器 ResourceManager 资源管理器 Dispatcher 分发器 任务提交流程 任务调度原理 Job ...
- 【shell】概述
功能简介 批量自动初始化系统(update,软件安装,时区设置,安全策略...) 批量自动部署软件(LAMP,LNMP,Nginx,LVS,Tomcat) 管理应用程序(KVM,集群管理扩容,MySQ ...
- 吴裕雄--天生自然python学习笔记:python安装配置tesseract-ocr-setup-3.05.00dev.exe
下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.00dev.exe 点击安装,记得复制安装的路径,待会 ...
- 2018SEERC Points and Rectangles (CDQ分治)
题:http://codeforces.com/gym/101964/problem/K 分析:https://blog.csdn.net/qq_43202683/article/details/98 ...
- Docker系列六: 使用Docker官方公共仓库和私有仓库
使用公共仓库 登陆官方网站:https://hub.docker.com/ 注册账号和密码 在Docker hub中创建一个资源, create respositories, 创建后会提示 ...
- 3)Framework创建思路
- python数据类型:列表List和Set
python数据类型:列表List, Set集合 序列是Python中最基本的数据结构 序列中每个元素都分配一个数字,表示索引 列表的数据项不需要具有相同的类型 列表中的值可以重复并且有 ...
- SQLserver安装了多个实例,实例端口号也被修改后的代码连接方式
事例说明 IP地址为192.168.1.100的服务器上安装了SQLServer2000,它有两个实例,分别为:默认实例——JLW和另外新建的实例——JLW\TEST SQLServer网络实用工具中 ...