Java并发编程 (二) 并发基础
个人博客网:https://wushaopei.github.io/ (你想要这里多有)
一、CPU多级缓存-缓存一致性
1、CPU多级缓存
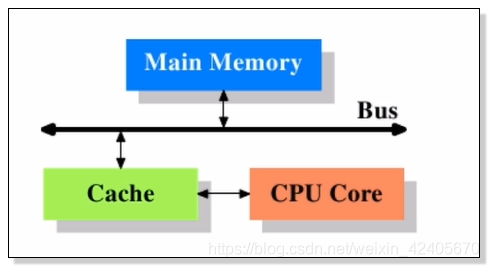

上图展示的是CPU高级缓存的配置,数据的读取和存储都经过高速缓存,CPU核心与高速缓存之间有一条特殊的快速通道;在这个简化的图中,主存和缓存都连接在系统总线上,这条总线同时还用于其他组件的通信。
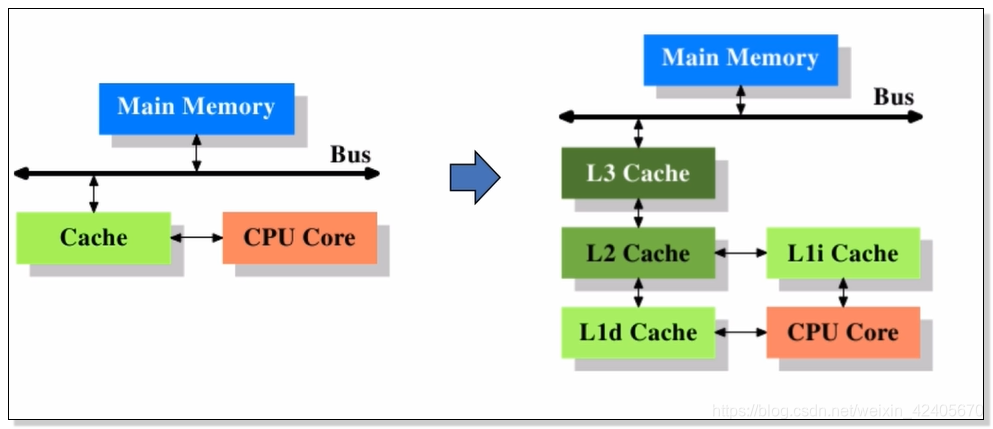
高速缓存出现后不久,系统变得更加复杂,高速缓存和主存之间的速度差异被拉大,直到加入L1d(又叫一级缓存)的缓存,新加入的这一个缓存比高速缓存更大,但是更慢,由于加大一级缓存的做法从经济上是行不通的。所以有了二级缓存。甚至,现在有些系统有了三级缓存。
2、CPU cache:
为什么需要CPU cache?
CPU的频率太快了,快到主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,浪费资源。所以cache的出现,是为了缓解CPU和内存之间速度的不匹配问题(结构: CPU -> cache - >memory ).
CPU cache 有什么意义?
1)时间局部性: 如果某个数据被访问,那么在不久的将来它很可能被再次访问;
2)空间局部性: 如果某个数据被访问,那么与它相邻的数据很快也可能被访问;
3、CPU多级缓存 - 缓存一致性(MESI)
- 用于保证多个CPU cache之间缓存共享数据的一致
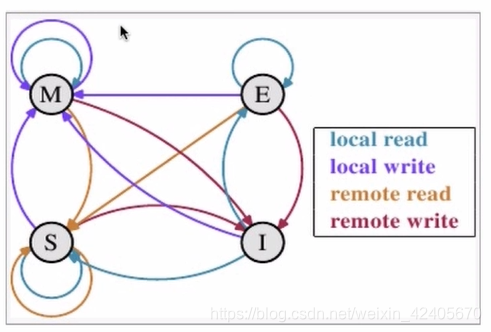
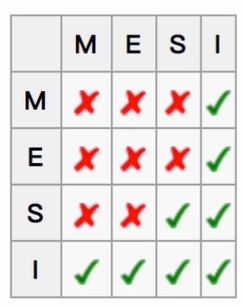
M代表modify,表示被修改;指的是该缓存行只被缓存在该CPU的缓存中,并且是被修改过的,因此,它与主存中的数据是不一致的,改缓存中的内存需要在未来的某个时间点写回主存;这个时间点我们是允许其他CPU读取主存中相应的内存之间,当这里的值被写回主存之后,该缓存行的状态会变成E的状态;
E 代表 Exclusive,表示独享状态;该状态下的缓存行只被缓存在该CPU的缓存中,它是未被修改过的,是与主存中的数据一直的,这个状态可以在任意时刻,当有其他读取该内存时,变成共享状态,即S;
同样,当CPU修改该缓存行时,该缓存行状态可以被修改为M 的状态。
S 代表 share,代表共享的意思;该状态意味着该缓存行可能被多个CPU进行缓存,并且各个缓存数据和主存数据是一致的,当有一个CPU修改该缓存行时,其他CPU所有的缓存行是可以被作废的,变成I 的状态;
I 代表 invalid,表示无效的;代表该缓存行是无效的,有其他CPU修改了该缓存行。
四种操作:
local read 代表读本地缓存中的数据
local write 代表将数据写到本地缓存中
remote read 代表将内存中的数据读取过来,
remote write 代表将数据写回到主存中
状态转换示意图:
二、CPU多级缓存 - 乱序执行优化
意义:
- 处理器为提高运算速度而做出违背代码原有顺序的优化
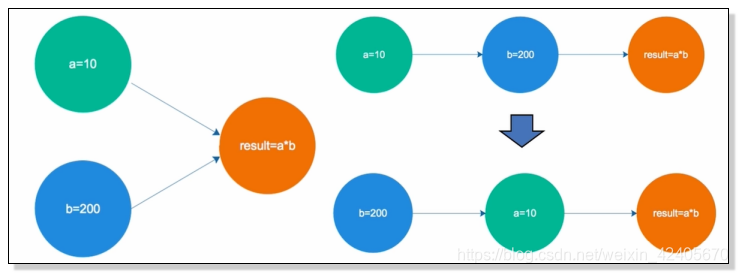
a : 数据写入顺序,先写入a=10,再写入b=200,最后计算a*b的值
b : 乱序执行的执行顺序:先执行b=200,再执行a=10,单核情况下不做任何影响。
多核心的情况下,可能由于乱序而导致各个核所写入数据的最终计算结果与预想的结果不一致。
三、 JAVA内存模型
1、Java内存模型(Java Memory Model,JMM)
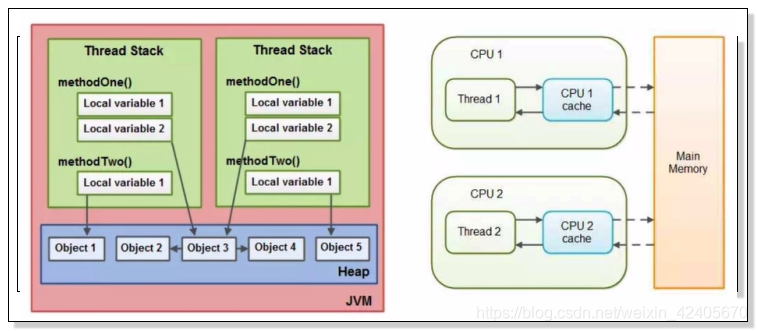
Java内存模型规范:规定了一个线程如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。
Java内存模型:Java里的堆是一个运行时数据区,堆是由垃圾回收来负责的,堆的优势是可以动态的分配内存大小,生成期也不必告诉编译器。因为它是在运行时动态分配内存的。Java收集器会自动搜索这些不再使用的数据。
其缺点是,由于是在运行时动态分配内存,因此它的存取速度相对慢一些.
Java的栈(stack),优势是存取数据的速度要比堆快,仅次于计算机里的寄存器,栈的数据是可以共享的;
缺点是存在栈中的数据大小与生存期必须是确定的,缺乏一些灵活性,栈中主要存放一些基本类型的变量,比如int、short、float、double、char和对象句柄
Java内存模型要求调用栈和本地变量存放在线程栈上,而Thread stack对象则存放在堆上。
一个本地变量有可能指向一个对象的引用,这种情况下,引用这个本地变量是存放在这个线程栈上,但是对象本身是存放在堆上的;一个对象,它可能包含方法(methodOne()、method Two()),
2、Java内存模型抽象结构图
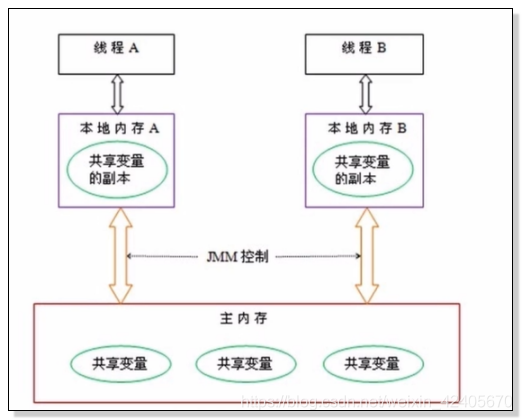
线程A在操作共享变量时,是从主存中复制共享变量的副本到本地内存中,进行逻辑修改后,再将副本同步到主存中;并发环境下,线程A将副本修改后要同步到主存中时,线程B可能刚好将主存的共享变量同步到本地内存B中进行逻辑修改。而这是很不安全的。因为线程B所操作的共享变量相对线程A来说是已经过期的值,这会导致后续的一系列运算都是基于错误的基础上执行的。
解决思路: 对线程A和线程B进行加锁,在主存共享变量进行副本复制后就不再允许其他线程操作,即实现线程的同步操作。从而解决并发线程的读写安全问题。
3、Java内存模型 - 同步八种操作
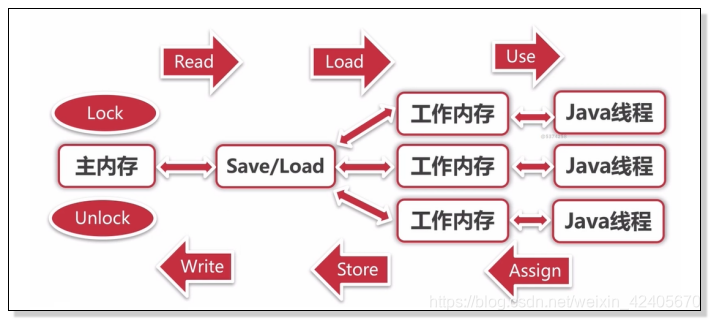
- lock (锁定):作用域主内存的变量,把一个变量标识为一条线程独占状态
- unlock (解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read(读取):作用域主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中
- use (使用):作用域工作内存的变量,把工作内中的一个变量值传递给执行引擎
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量
- store (存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
- write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中
4、Java内存模型 - 同步规则
① 如果要把一个变量从主内存中复制到工作内存,就需要按顺序地执行read和load操作,如果把变量从工作内存中同步回主内存中,就要按顺序地执行store和write操作。但Java内存模型值要求上述操作必须按顺序执行,而没有保证必须是连续执行;
② 不允许read和load、store和write操作之一单独出现;
③ 不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中;
④ 不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中;
⑤ 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign的)变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作;
⑥ 一个变量在同一时刻只允许一条线程对其进行lock操纵,但lock操作可以被同一条线程重复执行富哦次,多次执行lock后,只有执行相同次数的unlock操作,变量才会被解锁。lock和unlock必须成对出现;
⑦ 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值;
⑧ 如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量;
对一个变量执行unlock操作之前,必须先把次变量同步到主内存中(执行store和write操作)
5、Java内存模型 - 执行流程图:
四、 并发的优势与风险

小结:
- CPU多级缓存:缓存一致性、乱序执行优化
- Java内存模型: JMM规定、抽象结构、同步八种操作及规则
- Java并发的优势与风险
Java并发编程 (二) 并发基础的更多相关文章
- Java并发编程二三事
Java并发编程二三事 转自我的Github 近日重新翻了一下<Java Concurrency in Practice>故以此文记之. 我觉得Java的并发可以从下面三个点去理解: * ...
- Java并发编程:并发容器之CopyOnWriteArrayList(转载)
Java并发编程:并发容器之CopyOnWriteArrayList(转载) 原文链接: http://ifeve.com/java-copy-on-write/ Copy-On-Write简称COW ...
- Java并发编程:并发容器之ConcurrentHashMap(转载)
Java并发编程:并发容器之ConcurrentHashMap(转载) 下面这部分内容转载自: http://www.haogongju.net/art/2350374 JDK5中添加了新的concu ...
- Java并发编程:并发容器之ConcurrentHashMap
转载: Java并发编程:并发容器之ConcurrentHashMap JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的 ...
- Java并发编程:并发容器之CopyOnWriteArrayList
转载: Java并发编程:并发容器之CopyOnWriteArrayList Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个 ...
- Java并发编程:并发容器ConcurrentHashMap
Java并发编程:并发容器之ConcurrentHashMap(转载) 下面这部分内容转载自: http://www.haogongju.net/art/2350374 JDK5中添加了新的concu ...
- 【Java并发编程】并发编程大合集-值得收藏
http://blog.csdn.net/ns_code/article/details/17539599这个博主的关于java并发编程系列很不错,值得收藏. 为了方便各位网友学习以及方便自己复习之用 ...
- 【转】Java并发编程:并发容器之CopyOnWriteArrayList
Copy-On-Write简称COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改, ...
- 【转】Java并发编程:并发容器之ConcurrentHashMap
JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全性,所以这种方法的代价就是严重降低了 ...
随机推荐
- java1.8新特性之stream
什么是Stream? Stream字面意思是流,在java中是指一个来自数据源的元素队列并支持聚合操作,存在于java.util包中,又或者说是能应用在一组元素上一次执行的操作序列.(stream是一 ...
- FOC: Park变换电角度误差带来的影响
关于坐标变换已经在这篇博客中提到<FOC中的Clarke变换和Park变换详解>,在FOC算法的实际调试过程中会遇到很多与理论有所偏差的问题,往往这些情况下,需要对理论有较深刻的理解,才能 ...
- Spark Streaming 基本操作
Spark Streaming 基本操作 一.案例引入 3.1 StreamingContext 3.2 数据源 3.3 服务的启动与停止二.Transf ...
- 五一以来,国产手机受到cmtwg, nkvhu, qhsz等几款恶意软件肆虐。
受影响手机包括魅族,中国移动等国产手机. 5月12日开始有人在百度知道提问cmtwg,5月13日mx吧也有人在发贴. 我接到有问题的手机时间更早,大约就是五一之后. 出现问题的几个牌子的国产手机,似乎 ...
- AT命令集详解
1.2 AT的优点. 命令简单易懂,并且采用标准串口来收发AT命令,这样对设备控制大大简化了,转换成简单串口编程了. AT命令提供了一组标准的硬件接口--串口.这个简化的硬件设计.较新的电信网络模块, ...
- 7、会话框添加查看get与post请求类型
前言 在使用fiddler抓包的时候,查看请求类型get和post每次只有点开该请求,在Inspectors才能查看get和post请求,不太方便.于是可以在会话框直接添加请求方式. 一.添加会话框菜 ...
- 黑马程序员_毕向东_Java基础视频教程——位运算练习(随笔)
位运算(练习) 最有效率的方式算出 2乘以 8等于几 2 << 3 = 2 * 2^3 = 2 * 8 = 16 对于两个整数变量的值进行互换(不需要第三方变量) class Test { ...
- .Net Core3.0 WebApi 项目框架搭建 二:API 文档神器 Swagger
.Net Core3.0 WebApi 项目框架搭建:目录 为什么使用Swagger 随着互联网技术的发展,现在的网站架构基本都由原来的后端渲染,变成了:前端渲染.后端分离的形态,而且前端技术和后端技 ...
- PAT 1007 Maximum Subsequence Sum (25分)
题目 Given a sequence of K integers { N1 , N2 , ..., NK }. A continuous subsequence is define ...
- zabbix配置主动式监控的步骤(原创)
步骤如下: 1.克隆模板.命名新的模板名,并点击"监控项",全选,批量更新时第一个“类型”打勾,客户端改为主动式: 2.添加客户端或更改原有的模板为新模板(服务器端添加客户端时的配 ...