Apache Hudi在医疗大数据中的应用
本篇文章主要介绍Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考。
1. 建设背景
我们公司主要为医院建立大数据应用平台,需要从各个医院系统中抽取数据建立大数据平台。如医院信息系统,实验室(检验科)信息系统,体检信息系统,临床信息系统,放射科信息管理系统,电子病例系统等等。

在这么多系统中构建大数据平台有哪些痛点呢?大致列举如下。
- 接入的数据库多样化。其中包括很多系统,而系统又是基于不同数据库进行开发的,所以要支持的数据库比较多,例如MySQL,Oracle,Mongo db,SQLServer,Cache等等。
- 统一数据建模。针对不同的医院不同的系统里面的表结构,字段含义都不一样,但是最终数据模型是一定的要应用到大数据产品上的,这样需要考虑数据模型的量化。
- 数据量级差别巨大。不一样的医院,不一样的系统,库和表都有着很大的数据量差异,处理方式是需要考虑兼容多种场景的。
- 数据的时效性。数据应用产品需要提供更高效的实时应用分析,这也是数据产品的核心竞争力。
2. 为什么选择Hudi
我们早期的数据合并方案,如下图所示
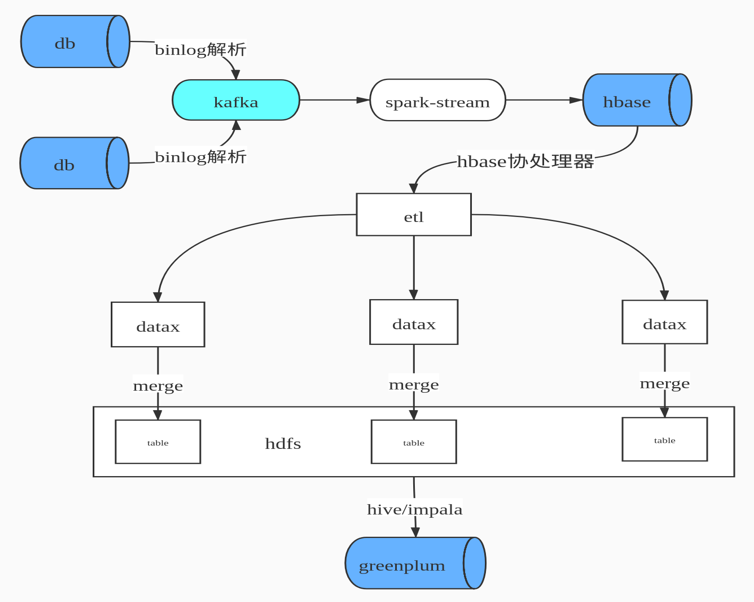
即先通过binlog解析工具进行日志解析,解析后变为JSON数据格式发送到Kafka 队列中,通过Spark Streaming 进行数据消费写入HBase,由HBase完成数据CDC操作,HBase即我们ODS数据层。由于HBase 无法提供复杂关联查询,这对后续的数据仓库建模并不是很友好,所以我们设计了HBase二级索引来解决两个问题:1. 增量数据的快速拉取,2. 解决数据的一致性。然后就是自研ETL工具通过DataX 根据最后更新时间增量拉取数据到Hadoop ,最后通过Impala数据模型建模后写入Greenplum提供数据产品查询。
上述方案面临了如下几个问题
- 数据流程环节复杂,数据要经过Kafka,HBase,Hdfs,Impala。
- 数据校验困难,每层数据质量校验比较麻烦。
- 数据存储冗余,HBase存储一份,Hive Hdfs 也存储一份。
- 查询负载高,HBase表有上限一旦表比较多,维护的Region个数就比较多,Region Server 容易出现频繁GC。
- 时效性不高,流程长不能保证每张表都能在10分钟内同步,有些数据表有滞后现象。

面对上述的问题,我们开始调研开源的实现方案,然后选择了Hudi,选择Hudi 优势如下
- 多种模式的选择。目前Hudi 提供了两种模式:Copy On Write和Merge On Read,针对不同的应用场景,可选择不同模式,并且每种模式还提供不同视图查询,。
- 支持多种查询引擎。Hudi 提供Hive,Spark SQL,presto、Impala 等查询方式,应用选择更多。
- Hudi现在只是Spark的一个库, Hudi为Spark提供format写入接口,相当于Spark的一个库,而Spark在大数据领域广泛使用。
- Hudi 支持多种索引。目前Hudi 支持索引类型HBASE,INMEMORY,BLOOM,GLOBAL_BLOOM 四种索引以及用户自定义索引以加速查询性能,避免不必要的文件扫描。
- 存储优势, Hudi 使用Parquet列式存储,并带有小文合并功能。
3. Hudi 数据同步
Hudi数据同步主要分为两个部分:1. 初始化全量数据离线同步;2. 近实时数据同步。

离线同步方面:主要是使用DataX根据业务时间多线程拉取,避免一次请求过大数据和使用数据库驱动JDBC拉取数据慢问题,另外我们也实现多种datax 插件来支持各种数据源,其中包括Hudi的写入插件。
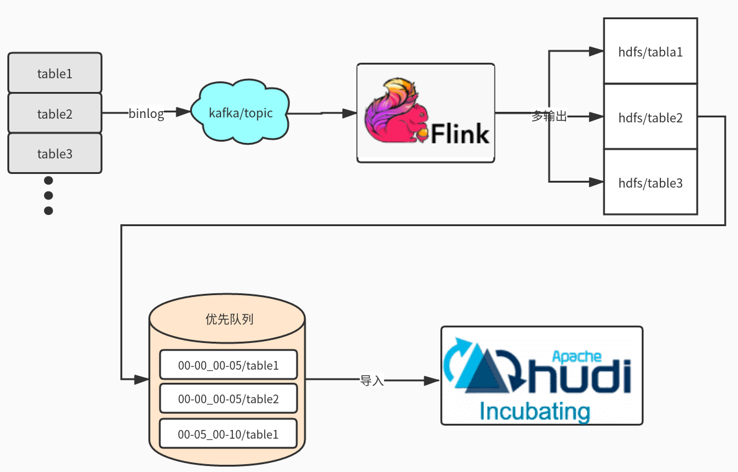
近实时同步方面:主要是多表通过JSON的方式写入Kafka,在通过Flink多输出写入到Hdfs目录,Flink会根据binlog json的更新时间划分时间间隔,比如0点0分到0点5分的数据在一个目录,0点5分到0点10分数据一个目录,根据数据实时要求选择目录时间的间隔。接着通过另外一个服务轮询监控Hdfs是否有新目录生成,然后调用Hudi Merge脚本任务。运行任务都是提交到线程池,可以根据集群的资源调整并合并的数量。
这里可能大家有疑问,为什么不是Kafka 直接写入Hudi ?官方是有这样例子,但是是基于单表的写入,如果表的数据多达上万张时怎么处理?不可能创建几万个Topic。还有就是分流的时候是无法使用Spark Write进行直接写入。
4. 存储类型选择及查询优化
我们根据自身业务场景,选择了Copy On Write模式,主要出于以下两个方面考虑。
- 查询时的延迟,
- 基于读优化视图增量模式的使用。
关于使用Spark SQL查询Hudi也还是SQL拆分和优化、设置合理分区个数(Hudi可自定义分区可实现上层接口),提升Job并行度、小表的广播变量、防止数据倾斜参数等等。
关于使用Presto查询测试比Spark SQL要快3倍,合理的分区对优化非常重要,Presto 不支持Copy On Write 增量视图,在此基础我们修改了hive-hadoop2插件以支持增量模式,减少文件的扫描。
5. 未来发展与思考
离线同步接入类似于FlinkX框架,有助于资源统一管理。FlinkX是参考了DataX的配置方式,把配置转化为Flink 任务运行完成数据的同步。Flink可运行在Yarn上也方便资源统一管理。
Spark消费可以支持多输出写入,避免需要落地Hdfs再次导入。这里需要考虑如果多表传输过来有数据倾斜的问题,还有Hudi 的写入不仅仅只有Parquert数据写入,还包括元数据写入、布隆索引的变更、数据合并逻辑等,如果大表合并比较慢会影响上游的消费速度。
Flink对Hudi的支持,社区正在推进这块的代码合入。
更多参与社区,希望Hudi社区越来越好。
Apache Hudi在医疗大数据中的应用的更多相关文章
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- NoSQL在大数据中的应用
一.序言 NoSQL是Not Only SQL的缩写,而不是Not SQL,指的是非关系型的数据库,它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准.ACID属性.表结构等等.相比传统数据库 ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- 基于简单sql语句的sql解析原理及在大数据中的应用
基于简单sql语句的sql解析原理及在大数据中的应用 李万鸿 老百姓呼吁打土豪分田地.共同富裕,总有一天会实现. 全面了解你所不知道的外星人和宇宙真想:http://pan.baidu.com/s/1 ...
- 日均 6000+ 实例,TB 级数据流量,Apache DolphinScheduler 如何做联通医疗大数据平台的“顶梁柱”?
作者 | 胡泽康 鄞乐炜 作者简介 胡泽康 联通(广东)产业互联网公司 大数据工程师,专注于开源大数据领域,从事大数据平台研发工作 鄞乐炜 联通(广东)产业互联网公司 大数据工程师,主要从事大数据平 ...
- 使用Apache Flink 和 Apache Hudi 创建低延迟数据湖管道
近年来出现了从单体架构向微服务架构的转变.微服务架构使应用程序更容易扩展和更快地开发,支持创新并加快新功能上线时间.但是这种方法会导致数据存在于不同的孤岛中,这使得执行分析变得困难.为了获得更深入和更 ...
- Apache Kylin在4399大数据平台的应用
来自:AI前线(微信号:ai-front),作者:林兴财,编辑:Natalie作者介绍:林兴财,毕业于厦门大学计算机科学与技术专业.有多年的嵌入式开发.系统运维经验,现就职于四三九九网络股份有限公司, ...
- 大数据中必须要掌握的 Flink SQL 详细剖析
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言. 自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 ...
随机推荐
- gVim配置文件分享
前言 直接可以把这个配置覆盖掉现在安装目录Vim底下的"_vimrc"文件 效果图 Code: set number set tabstop=4 set softtabstop=4 ...
- Spring IOC的核心机制:实例化与注入
上文我们介绍了IOC和DI,IOC是一种设计模式,DI是它的具体实现,有很多的框架都有这样的实现,本文主要以spring框架的实现,来看具体的注入实现逻辑. spring是如何将对象加入容器的 spr ...
- JavaWeb开发规范
以下的建议将帮助你更有效地使用本文所描述的 Java 编程标准: ******************************************************* 当你写代码时就应该遵守 ...
- redis系列之5----redis实战(redis与spring整合,分布式锁实现)
本文是redis学习系列的第五篇,点击下面链接可回看系列文章 <redis简介以及linux上的安装> <详细讲解redis数据结构(内存模型)以及常用命令> <redi ...
- P3467(矩形覆盖问题)
描述:https://www.luogu.com.cn/problem/P3467 1.考虑如果整个建筑物链是等高的,一张高为链高,宽为整个建筑物宽的海报即可完全覆盖: 2.若有两个不等高的元素组成建 ...
- 前端自适应样式reset.css
@charset "utf-8"; /* CSS Document */ html, body, ul, li, ol, dl, dd, dt, p, h1, h2, h3, h4 ...
- Django 设置admin后台表和App(应用)为中文名
设置表名为中文 1.设置Models.py文件 class Post(models.Model): name = models.CharField() --省略其他字段信息 class Meta: v ...
- OpenCV Error: Unspecified Error(The Function is not implemented)
Ubuntu 或者 Debian 系统显示窗口的时候遇到了这个问题 error: (-2:Unspecified error) The function is not implemented. Reb ...
- Code Review 常见的5个错误模式
原作者:Trisha Gee Code Review 的时候,每个人都会关心最佳实践,但最坏的实践有时可能会更有启示意义. Code Review是研发团队必不可少的,但并不总是正确的.这篇文章指出了 ...
- [ACdream 1215 Get Out!]判断点在封闭图形内, SPFA判负环
大致题意:在二维平面上,给一些圆形岛屿的坐标和半径,以及圆形船的位置和半径,问能否划到无穷远的地方去 思路:考虑任意两点,如果a和b之间船不能通过,则连一条边,则问题转化为判断点是否在多边形中.先进行 ...