数据结构( Pyhon 语言描述 ) — — 第4章:数据和链表结构
- 数据结构是表示一个集合中包含的数据的一个对象
- 数组数据结构
- 数组是一个数据结构
- 支持按照位置对某一项的随机访问,且这种访问的时间是常数
- 在创建数组时,给定了用于存储数据的位置的一个数目,并且数组的长度保持固定
- 插入和删除需要移动数据元素
- 创建一个新的、较大的或较小的数组,可能也需要移动数据元素
- 支持的操作
- 在给定位置访问或替代数组的一个项
- 查看数组的长度
- 获取数组的字符串表示
- 数组操作及Arrary 类方法
用户的数组操作
Array类中的方法
a = Array(10)
__init__( capacity, fillValue = None )
len(a)
__len__()
str(a)
__str__()
for item in a:
__iter__()
a[index]
__getitem__(index)
a[index] = newItem
__setitem__( index, newItem )
- 代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: arrays.py
An array is like a list, but the client can use only [], len, iter, and str
To instantiate, use
<Varialbe> = Array( <capacity>, <optional fill value> )
The fill value is None by default.
"""
class Array( object ):
""" Represents an array """
def __init__( self, capacity, fillValue = None ):
""" Capacity is the static size of the array. fillValue is placed at each position. """
self._items = list()
for count in range( capacity ):
self._items.append( fillValue )
def __len__( self ):
""" -> The capacity of the array. """
return len( self._items )
def __str__( self ):
""" -> The string representation of the array """
return str( self._items )
def __iter__( self ):
"""Supports traversal with for loop."""
return iter( self._items )
def __getitem__( self, index ):
""" Subscript operator for access at index. """
return self._items[ index ]
def __setitem__( self, index, newItem ):
"""Subscript operator for replacement at index."""
self._items[index] = newItem
- 随机访问与连续内存
- 数组索引是一个随机访问操作,这种访问的时间是常数
- 计算机为数组项分配的是一段连续的内存单元
- 数组是一个数据结构

- Python数组索引操作的步骤
- 获取数组内存块的基本地址
- 给这个地址加上索引,返回最终的结果
- 常量时间的随机访问,可能是数组最想要功能,但是这要求数组必须用一段连续的内存来表示,这样会导致数组实现其它操作时,需要付出代价
- 静态内存与动态内存
- 可以根据应用程序的数据需求来调整数组长度
- 在程序开始的时候创建一个具有合理默认大小的数组
- 当数组大小不能保存更多的数据时,创建一个新的,更大的数组,并且从原数组转移数据项
- 当数组似乎存在浪费内存的时候,以一种类似的方式减小数组的长度
- 可以根据应用程序的数据需求来调整数组长度
- 物理大小与逻辑大小
- 物理大小
- 数组单元的总数,或者指创建数组时,用来指定其容量的数字
- 逻辑大小
- 数组当前可供应用程序使用的项的数目

- 物理大小
- 数组的操作
- 数据设置
DEFAULT_CAPACITY
logicalSize
a = Array[DEFAULT_CAPACITY]
- 增加数组的大小
- 步骤
- 创建一个新的,更大的数组
- 将旧的数组复制到新的数组
- 将旧的数组变量重新设置为新的数组对象
- 代码
if logicalSize == len( a ):
temp = Array( len( a ) + 1 )
for i in range( logicalSize ):
temp[i] = a[i]
a = temp
- 时间性能
- 当给数组添加 n 项时,其整体性能:
- 每次增加数组大小时,可以将数组的大小加倍,以提升时间性能,但是是以一定的内存浪费为代价的
temp = Array( len( a ) * 2 )
- 当给数组添加 n 项时,其整体性能:
- 空间性能
- 线性
- 步骤
- 减小数组的大小
- 步骤
- 创建一个新的,更小的数组
- 将旧的数组复制到新的数组中
- 将旧数组变量设置为新的数组对象
- 代码
- 触发及操作
- 数组的逻辑大小小于或等于其物理大小的四分之一,并且物理大小至少是创建数组时的默认容量两倍的时候,将数组的大小减小至其原来的二分之一
:
temp = Array( len(a) // 2 )
for i in range( logicalSize ):
temp[i] = a[i]
a = temp
- 触发及操作
- 步骤
- 在数组中插入一项
- 步骤
- 检查可用空间,以判断是否需要增加数组大小
- 从数组的逻辑未尾开始,直到目标索引,每一项向后移动一个单元
- 将新的项赋值给目标索引位置
- 逻辑大小增加1
- 代码
#Increase physical size of array if necessary
#shift items by one position
while index in range( logicalSize, targetIndex, -1 ):
a]
#Add new item, and increase logical size
a[targetIndex] = newItem
logicalSize
- 插入操作是线性的
- 步骤
- 从数组中删除一项
- 步骤
- 从紧跟目标索引的位置开始,直至逻辑未尾,将每一项都往前移一位
- 将逻辑大小减1
- 检查浪费空间,看是否有必要,更改数组的物理大小
- 代码
#shift items by one position
while index in range( targetIndex, logicalSize ):
a]
#decrease logical size
logicalSize
#decrease physical size of array if necessary
- 时间性能为线性
- 步骤
- 复杂度权衡:时间、空间和数组
- 数组操作的运行时间
操作
运行时间
从第 i 个位置访问
O(1),最好情况和最坏情况
在第 i 个位置访问
O(1),最好情况和最坏情况
在逻辑未尾插入
O(1),平均情况
在逻辑未尾删除
O(1),平均情况
在第 i 个位置插入
O(n),平均情况
在第 i 个位置删除
O(n),平均情况
增加容量
O(n),最好情况和最差情况
减小容量
O(n),最好情况和最差情况
- 装载因子
- 数组的装载因子等于其逻辑大小除以物理大小
- 数组操作的运行时间
- 数据设置
- 二维数组 - - 网格
- 使用数组的数组可以表示网格
- 顶层的数组长度等于网格中行的数目,顶层数组的每一个单元格也是数组,数组的长度即为网格中列的长度
- 要支持用户使用双下标,需要使用 __getitem__方法
- Grid 类的定义
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
Defines a two-dimensional array
"""
from arrays import Array
class Grid( object ):
"""Represent a two dimensional array."""
def __init__( self, rows, columns, fillValue = None ):
self._data = Array( rows )
for row in range( rows ):
self._data[row] = Array( columns, fillValue )
def getHeight( self ):
"""Return the number of rows"""
return len( self._data )
def getWidth( self ):
"""Return the number of columns."""
] )
def __getitem__( self, index ):
"""Supports two-dimensional indexing with [row][column]"""
return self._data[index]
def __setitem__( self, index, newItem ):
"""Supoort two dimensional replacement by index."""
self._data[index] = newItem
def __str__( self ):
"""Return a string represention of a grid."""
result = ""
for row in range( self.getHeight() ):
for column in range( self.getWidth() ):
result += str( self._data[row][column] ) + " "
result += "\n"
return result
- 杂乱的网格和多维数组
- 杂乱的网格有固定的行,但是每一行中列的数目不同
- 需要时候,可以在网格的定义中添加维度
- 使用数组的数组可以表示网格
- 链表结构
- 链表结构是一个数据结构,它包含0个或多个节点。一个节点包含了一个数据项,以及到其它节点的一个或多个链接
- 单链表结构和双链表结构
- 单链表结构的节点包含了一个数据项和到下一个节点的一个链接。双链表结构中的结点还包括了到前一个节点的一个链接。
- 单链表结构示意图
- 双链表结构示意图
- 与数组对比
- 和数组相同,链接结构表示了项的线性序列
- 但是链表结构无法通过指定索引,立即访问某一项。而是必须从结构的一段开始,沿着链表进行,直到达到想要的位置(或项)
- 插入和删除与数组有很大不同
- 一旦找到插入点或删除点,就可以进行删除与插入操作,而不需要在内存中移动数据项
- 在每一次插入和删除的过程中,链表结构会调整大小,并不需要额外的内存代价,也不需要复制数据项
- 非连续性内存和节点
- 数组中的项必须存储在连续的内存中,即数组中项的逻辑顺序是和内存中的物理单元序列紧密耦合的。
- 链表结构将结构中的项的逻辑顺序和内存中的顺序解耦了,即计算机只要遵循链表结构中一个给定项的地址和位置的链接,就能在内存中找到它的单元在何处。这种内存表示方案,即叫做非连续性内存
- 链表结构中的基本单元表示的是节点
- 单链表结点
- 双链表结点
- 单链表结点
- 单链表结点类
- 类代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
linked node structure
"""
class Node( object ):
"""Represent a singly linked node."""
def __init__( self, data, next = None ):
"""Instantiates a Node with default next of None."""
self.data = data
self.next = next
- 测试代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: testnode.py
Tests the Node class
"""
from node import Node
head = None
#Add five nodes to the beginning of the linked structrue
):
head = Node( count, head )
#Print the contents of the structrue
while head != None:
print( head.data )
head = head.next
- 代码分析
- 插入的项总是位于结构的开始处
- 显示数据的时候,按照与插入项相反的顺序出现
- 显示完数据后,head 指针指向了None,节点实际上从链表结构中删除了,对于程序来说,节点不再可用,并会在下一次垃圾回收的时候回收
- 为了避免这种情况,遍历链表时,可以使用一个临时指针
- 类代码


- 单链表结构上的操作
- 遍历
- 使用临时指针,进行遍历
probe = head
while probe != None:
#<use or modify probe.data>
probe = probe.next
- 遍历在时间上是线性的,不需要额外的开销
- 使用临时指针,进行遍历
- 搜索
- 一个链表的顺序搜索和遍历类似,都是从第1个节点开始并且沿着链接,直到遇到哨兵
- 搜索给定的项
probe = head
while probe != None and targetItem != probe.data:
#<use or modify probe.data>
probe = probe.next
if probe != None:
<targetItem has been found>
else:
<targetItem is not in the linked structure>
- 对于单链表结构,顺序搜索是线性的
- 访问链表中的第 i 项
#Assums 0 <= index < n
probe = head
:
probe = probe.next
index
return probe.data
- 替换
- 替换操作也需要使用遍历模型,包括替换一个给定的项,或替换一个给定的位置
- 替换给定的项
probe = head
while probe != None and targetItem != probe.data:
#<use or modify probe.data>
probe = probe.next
if probe != None:
probe.data = newItem
return True
else:
return False
- 替换第 i 项
#Assums 0 <= index < n
probe = head
:
probe = probe.next
index
probe.data = newItem
- 在开始处插入
- 代码
head = Node( newItem, head )
- 此操作的时间和内存都是常数
- 代码
- 在末尾插入
- 考虑两情况
- head指针为None,此时,将head指针设置为新的节点
- head指针不为None,此时,代码将检索最后一个节点,并将其next指针指向新的节点
- 代码
newNode = Node( newItem )
if head is None:
head = newNode
else:
probe = head
while probe.next != None:
probe = probe.next
probe.next = newNode
- 考虑两情况
- 从开始处删除
- 假设结构中至少有一个节点
- 代码
#Assume at least one node in the structure
removedItem = head.data
head = head.next
return removedItem
- 从末尾处删除
- 假设至少有一个节点
- 考虑两种情况
- 只有一个节点,head 指针设置为None
- 在最后一个节点前有其它节点。代码搜索倒数第2个节点,并将其 next 指针设置为None
- 代码
#Assume at least one node in the structure
removedItem = head.data
if head.next is None:
head = None
else:
probe = head
while probe.next.next != None:
probe = probe.next
removedItem = probe.data
probe.next = None
return removedItem
- 在任何位置插入
- 在一个链表的第 i 个位置插入一项,必须先找到位置为 i - 1 ( i < n)或者 n - 1 ( i >= n )的节点。然后,需要考虑如下两种情况。此处,还需要考虑 head 为空或者插入位置小于等于0的情况
- 该节点的 next 指针为 None,因此,应将该项放在链表结构的未尾
- 该节点的 next 指针不为None,因此,直接将新的项放在位置 i - 1 和 i 的节点之间
- 代码
:
head = Node( newItem, head )
else:
#Serach for node at position index - 1 or the last position
probe = head
while index > 1 and probe.next != None:
probe = probe.next
index
#Insert new node after node at position index - 1 or last position
probe.next = Node( newItem, probe.next )
- 在一个链表的第 i 个位置插入一项,必须先找到位置为 i - 1 ( i < n)或者 n - 1 ( i >= n )的节点。然后,需要考虑如下两种情况。此处,还需要考虑 head 为空或者插入位置小于等于0的情况
- 从任意位置删除
- 从一个链表结构中删除第 i 项,具有以下3种情况
- i <= 0 ——使用删除第 1 项的代码
- 0 < i < n ——搜索位于 i -1 位置的节点,删除其后面的节点
- i >= n ——删除最后一个节点
- 代码
#Assume that the linked structure has at least one node
if index <=0 or head.next == None:
removeItem = head.data
head = head.next
return removeItem
else:
#Search for node at position next - 1 or the next to last position
probe = head
while index > 1 and probe.next.next != None
probe = probe.next
index
removeItem = probe.next.data
probe.next = probe.next.next
return removeItem
- 从一个链表结构中删除第 i 项,具有以下3种情况
- 复杂度权衡:时间、空间和单链表结构
操作
运行时间
在第 i 个位置访问
O(n),平均情况
在第 i 个位置替换
O(n),平均情况
在开始处插入
O(1),最好情况和最差情况
在开始处删除
O(1),最好情况和最差情况
在第 i 个位置插入
O(n),平均情况
从第 i 个位置删除
O(n),平均情况
- 单链表结构相对于数组的主要优点并不是时间性能,而是内存性能
- 遍历
- 链表的变体
- 带有一个哑头节点的循环链表结构
- 循环链表结构包含了从结构中的最后一个节点回到第一个节点的一个链接。在这个实现中,至少总是有一个节点是哑头结点,它不包含数据,但是充当了链表结构的开头和结尾的一个标记
- 示意图
- 带有一个哑头节点的循环链表结构
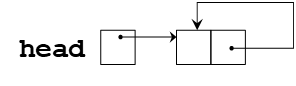
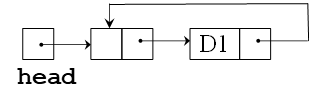
- 哑头结点使得插入和删除操作只需要考虑一种情况
- 插入结点
#Search for node at position index - 1 or the last position
probe = head
while index > 0 and probe.next != head:
probe = probe.next
index
#Insert new node after node at position index - 1 or last position
probe.next = Node( newItem, probe.next )
- 插入结点
- 双链表结构
- 双链表每个节点中含有两个指针,通常称为 next 和 previous,还有一个 tail 指针,它允许直接访问结构中的最后一个结点
- 示意图
- 示意图
- 双链表类的定义
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
linked node structure
"""
class Node( object ):
"""Represent a singly linked node."""
def __init__( self, data, next = None ):
"""Instantiates a Node with default next of None."""
self.data = data
self.next = next
class TwoWayNode( Node ):
def __init__( self, data, previous = None, next = None ):
Node.__init__( self, data, next )
self.previous = previous
- 双链表类的使用
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:Lijunjie
"""
File: testtwowaynode.py
Tests the two way node Class
"""
from node import TwoWayNode
#Create a doubly linked structure with one node
head )
tail = head
#Add four nodes to the end of the doubly linked structure
,6 ):
tail.next = TwoWayNode( data, tail )
tail = tail.next
#print the contents of the linked structure in reverse order
proble = tail
while proble != None:
print( proble.data )
proble = proble.previous
- 在链表未尾插入一个新的项的语句
tail.next = TwoWayNode( data, tail )
tail = tail.next
- 新节点的 previous 指针必须指向当前的尾节点。通过将 tail 当作该节点构造方法的第2个参数传递,来实现这一点
- 当前尾节点的 next 指针必须指向新的节点,这通过第一条赋值语句来实现
- tail 指针必须指向新的节点。第二条赋值语句实现这点
- 带有哑头节点的循环双链表
- 双链表每个节点中含有两个指针,通常称为 next 和 previous,还有一个 tail 指针,它允许直接访问结构中的最后一个结点


数据结构( Pyhon 语言描述 ) — — 第4章:数据和链表结构的更多相关文章
- 数据结构( Pyhon 语言描述 ) — —第9章:列表
概念 列表是一个线性的集合,允许用户在任意位置插入.删除.访问和替换元素 使用列表 基于索引的操作 基本操作 数组与列表的区别 数组是一种具体的数据结构,拥有基于单个的物理内存块的一种特定的,不变的实 ...
- 数据结构( Pyhon 语言描述 ) — — 第2章:集合概览
集合类型 定义 个或多个其他对象的对象.集合拥有访问对象.插入对象.删除对象.确定集合大小以及遍历或访问集合的对象的操作 分类 根据组织方式进行 线性集合 线性集合按照位置排列其项,除了第一项,每一项 ...
- 数据结构( Pyhon 语言描述 ) — —第10章:树
树的概览 树是层级式的集合 树中最顶端的节点叫做根 个或多个后继(子节点). 没有子节点的节点叫做叶子节点 拥有子节点的节点叫做内部节点 ,其子节点位于层级1,依次类推.一个空树的层级为 -1 树的术 ...
- 数据结构( Pyhon 语言描述 ) — — 第5章:接口、实现和多态
接口 接口是软件资源用户可用的一组操作 接口中的内容是函数头和方法头,以及它们的文档 设计良好的软件系统会将接口与其实现分隔开来 多态 多态是在两个或多个类的实现中使用相同的运算符号.函数名或方法.多 ...
- 数据结构( Pyhon 语言描述 ) — — 第7章:栈
栈概览 栈是线性集合,遵从后进先出原则( Last - in first - out , LIFO )原则 栈常用的操作包括压入( push ) 和弹出( pop ) 栈的应用 将中缀表达式转换为后缀 ...
- 数据结构( Pyhon 语言描述 ) — — 第6章:继承和抽象类
继承 新的类通过继承可以获得已有类的所有特性和行为 继承允许两个类(子类和超类)之间共享数据和方法 可以复用已有的代码,从而消除冗余性 使得软件系统的维护和验证变得简单 子类通过修改自己的方法或者添加 ...
- 数据结构( Pyhon 语言描述 ) — — 第3章:搜索、排序和复杂度分析
评估算法的性能 评价标准 正确性 可读性和易维护性 运行时间性能 空间性能(内存) 度量算法的运行时间 示例 """ Print the running times fo ...
- 数据结构( Pyhon 语言描述 ) — —第11章:集和字典
使用集 集是没有特定顺序的项的一个集合,集中的项中唯一的 集上可以执行的操作 返回集中项的数目 测试集是否为空 向集中添加一项 从集中删除一项 测试给定的项是否在集中 获取两个集的并集 获取两个集的交 ...
- 数据结构( Pyhon 语言描述 ) — — 第1章:Python编程基础
变量和赋值语句 在同一条赋值语句中可以引入多个变量 交换变量a 和b 的值 a,b = b,a Python换行可以使用转义字符\,下一行的缩进量相同 )\ 帮助文档 help() 控制语句 条件式语 ...
随机推荐
- 拓扑排序复习——Chemist
一.基本算法 拓扑序列:对于一张有向图,求一个序列ai若对于每一条边(u,v),都满足au<=av ,则称这个序列为这张有向图的拓扑序列,一张图可能有多个拓扑序列. 求拓扑序列:找到入度为0的点 ...
- 点击a标签的子元素不跳转 ,阻止默认行为
- Android SDK Manager 无法下载Android8.1.0(API 27) SDK Platform
在Android SDK Manager 中安装Android 8.1.0 SDK Platform时报错导致无法安装. 错误信息:Downloading SDK Platform Android 8 ...
- 【bzoj2084】[Poi2010]Antisymmetry
2084: [Poi2010]Antisymmetry Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 1205 Solved: 756[Submit ...
- A.华华听月月唱歌
链接:https://ac.nowcoder.com/acm/contest/392/A 题意: 月月唱歌超级好听的说!华华听说月月在某个网站发布了自己唱的歌曲,于是把完整的歌曲下载到了U盘里.然而华 ...
- Codeforces Round #544 (Div. 3) D. Zero Quantity Maximization
链接:https://codeforces.com/contest/1133/problem/D 题意: 给两个数组a,b. 同时ci = ai * d + bi. 找到一个d使c数组中的0最多. 求 ...
- qconbeijing2015
http://2015.qconbeijing.com/schedule 大会日程 2015年4月23日,星期四 地点 2号厅 203AB 201AB 9:15 开场致辞 专题 主题演讲 互联网金融背 ...
- qconbeijing2018
https://2018.qconbeijing.com/schedule 会议 · 第一天 (2018/04/20 周五) 时间 日程 上午 主题演讲 大数据下的软件质量建设实践 黄闻欣 出品 人工 ...
- C/S WinForm自动升级
这二天刚好完成一个C/S 自动升级的功能 代码分享一下 /// <summary> /// 版本检测 /// </summary> public class ...
- Java基础50题test3—水仙花数
水仙花数 题目:打印出所有的"水仙花数",所谓"水仙花数"是指一个三位数,其各位数字立方和等于该数本身.例 如:153 是一个"水仙花数", ...