初探kafka streams
1、启动zookeeper
zkServer.cmd
2、启动kafka
kafka-server-start.bat d:\soft\tool\Kafka\kafka_2.12-2.1.0\config\server.properties
3、创建一个用于存储输入数据的topic
kafka-console-producer.bat --broker-list localhost:9092 --topic streams-file-input < file-input.txt
为了方便演示,其中file-input.txt我是直接放到kafka的bin目录下
4、在idea中创建一个简单的项目,书写以下代码:
/**
* ymm56.com Inc.
* Copyright (c) 2013-2019 All Rights Reserved.
*/
package wikiedits; import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KTable; import java.util.Arrays;
import java.util.Properties; /**
* @author LvHuiKang
* @version $Id: KafkaStreamTest.java, v 0.1 2019-03-26 19:45 LvHuiKang Exp $$
*/
public class KafkaStreamTest {
public static void main(String[] args) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
Serde<String> sdeStr = Serdes.String();
Serde<Long> sdeLong = Serdes.Long();
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> inputLines = builder.stream(sdeStr, sdeStr, "streams-file-input");
KTable<String, Long> wordCounts = inputLines.flatMapValues(inputLine -> Arrays.asList(inputLine.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count("Counts");
wordCounts.to(sdeStr, sdeLong, "streams-wordcount-output");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
System.out.println(); }
}
pom 依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.</artifactId>
<version>0.11.0.0</version>
</dependency>
然后启动main方法,运行如下:
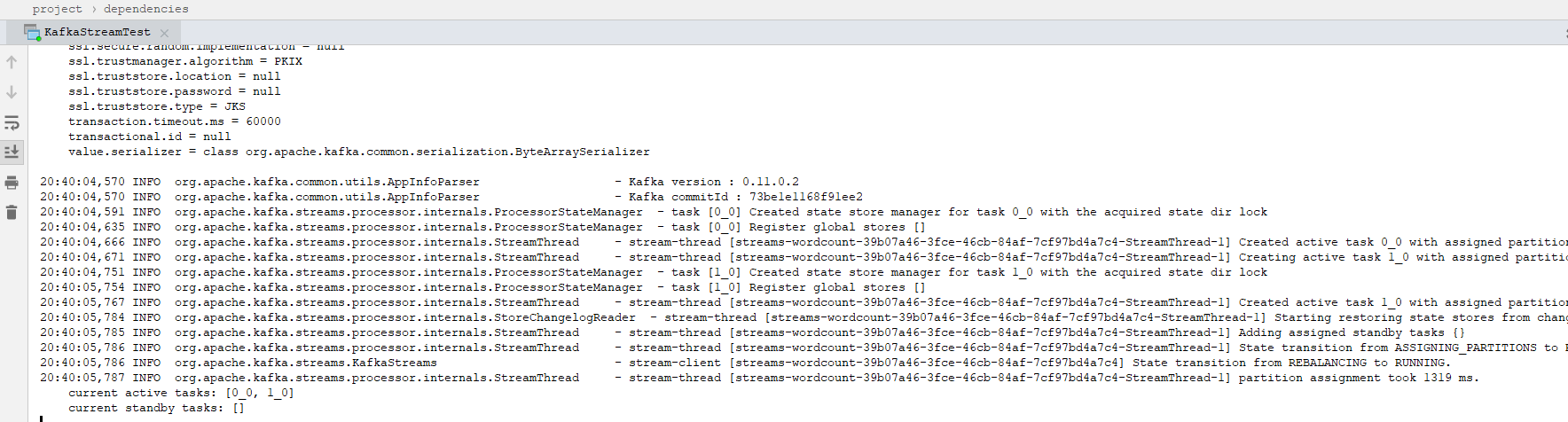
5、启动consumer:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
展示如下:
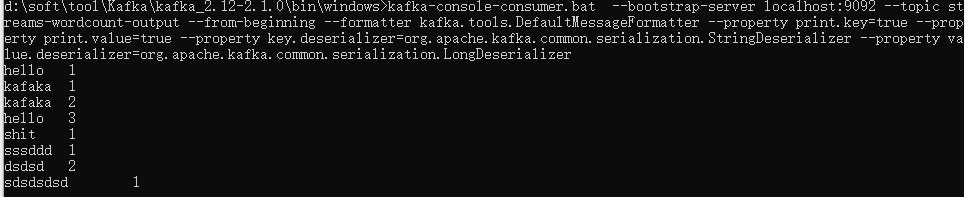
按Ctrl + C 退出。
以上就演示了kafka streams 的word-count示例
初探kafka streams的更多相关文章
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams 剖析
1.概述 Kafka Streams 是一个用来处理流式数据的库,属于Java类库,它并不是一个流处理框架,和Storm,Spark Streaming这类流处理框架是明显不一样的.那这样一个库是做什 ...
- 浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视.实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm.Spark Streaming.flink等.我今 ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 手把手教你写Kafka Streams程序
本文从以下四个方面手把手教你写Kafka Streams程序: 一. 设置Maven项目 二. 编写第一个Streams应用程序:Pipe 三. 编写第二个Streams应用程序:Line Split ...
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- 大全Kafka Streams
本文将从以下三个方面全面介绍Kafka Streams 一. Kafka Streams 概念 二. Kafka Streams 使用 三. Kafka Streams WordCount 一. ...
- 简介Kafka Streams
本文从以下几个方面介绍Kafka Streams: 一. Kafka Streams 背景 二. Kafka Streams 架构 三. Kafka Streams 并行模型 四. Kafka Str ...
随机推荐
- 字符型液晶屏模拟控件(En)
A replica CLCD module control. Initiated on May 5, 2012 Updated on Feb 21, 2017 Copyright 2012-2017 ...
- 整合 MyPerf4J 做Java性能监控和统计工具
快速启动MyPerf4J MyPerf4J 采用 JavaAgent 配置方式,透明化接入应用,对应用代码完全没有侵入. 打包 项目地址: https://github.com/LinShunKang ...
- C# 数组Array
数组是对相同类型的一组数据的封装.数组定义的时候,要说明是对哪一种类型的封装,并且要指定长度. using System; using System.Collections.Generic; usin ...
- 纯手写springIOC
大家好啊- 那么今天来带大家写一下spring的ioc. 其实也很简单,首先我们明白两点,java解析xml和java的反射机制,因为ioc就是主要是基于这两个来实现,今天只是简单的来大家实现下. 废 ...
- python 自定义模块的发布和安装
[学习笔记] 自定义模块 使用的是pycharm 说白了就是.py文件都可以作为模块导入,像定义一个文件 名字为Mycode __all__ = ["add","sub& ...
- Nginx系列
包括nginx的入门和进阶学习. 目录 nginx系列1:认识nginx nginx系列2:搭建nginx环境 nginx系列3:搭建一个静态资源web服务器 nginx系列4:日志管理 nginx系 ...
- 五一出门必备的手机APP神器 让你瞬间大开眼界
如今我们手机上有各种各样的软件,但是比较实用的又有哪些呢?所以每次大家都会花上很久的时间去查找满意的软件吧!今天就给大家送上一波福利,因为五一小长假就要到来了,说不定大家会使用到呢! 轻颜相机 轻颜相 ...
- 轨迹系列4——WebGIS中使用ZRender实现轨迹前端动态播放特效
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 项目中需要在地图上以时间轴方式播放人员.车辆在地图上的历史行进 ...
- java:数据结构复习(二)数组栈
import java.util.Arrays;import java.util.Scanner; /** * @author 李正阳 */public class MyArraysStack< ...
- JVM内存结构,运行机制
三月十号,白天出去有事情出去了一天,晚上刚到食堂就接到阿里电话, 紧张到不行,很多基础的问题都不知道从哪里说了orz: 其中关于JVM内存结构,运行机制,自己笔记里面有总结的,可当天还是一下子说不出来 ...