初探kafka streams
1、启动zookeeper
zkServer.cmd
2、启动kafka
kafka-server-start.bat d:\soft\tool\Kafka\kafka_2.12-2.1.0\config\server.properties
3、创建一个用于存储输入数据的topic
kafka-console-producer.bat --broker-list localhost:9092 --topic streams-file-input < file-input.txt
为了方便演示,其中file-input.txt我是直接放到kafka的bin目录下
4、在idea中创建一个简单的项目,书写以下代码:
/**
* ymm56.com Inc.
* Copyright (c) 2013-2019 All Rights Reserved.
*/
package wikiedits; import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import org.apache.kafka.streams.kstream.KTable; import java.util.Arrays;
import java.util.Properties; /**
* @author LvHuiKang
* @version $Id: KafkaStreamTest.java, v 0.1 2019-03-26 19:45 LvHuiKang Exp $$
*/
public class KafkaStreamTest {
public static void main(String[] args) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
Serde<String> sdeStr = Serdes.String();
Serde<Long> sdeLong = Serdes.Long();
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> inputLines = builder.stream(sdeStr, sdeStr, "streams-file-input");
KTable<String, Long> wordCounts = inputLines.flatMapValues(inputLine -> Arrays.asList(inputLine.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count("Counts");
wordCounts.to(sdeStr, sdeLong, "streams-wordcount-output");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
System.out.println(); }
}
pom 依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>0.11.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.</artifactId>
<version>0.11.0.0</version>
</dependency>
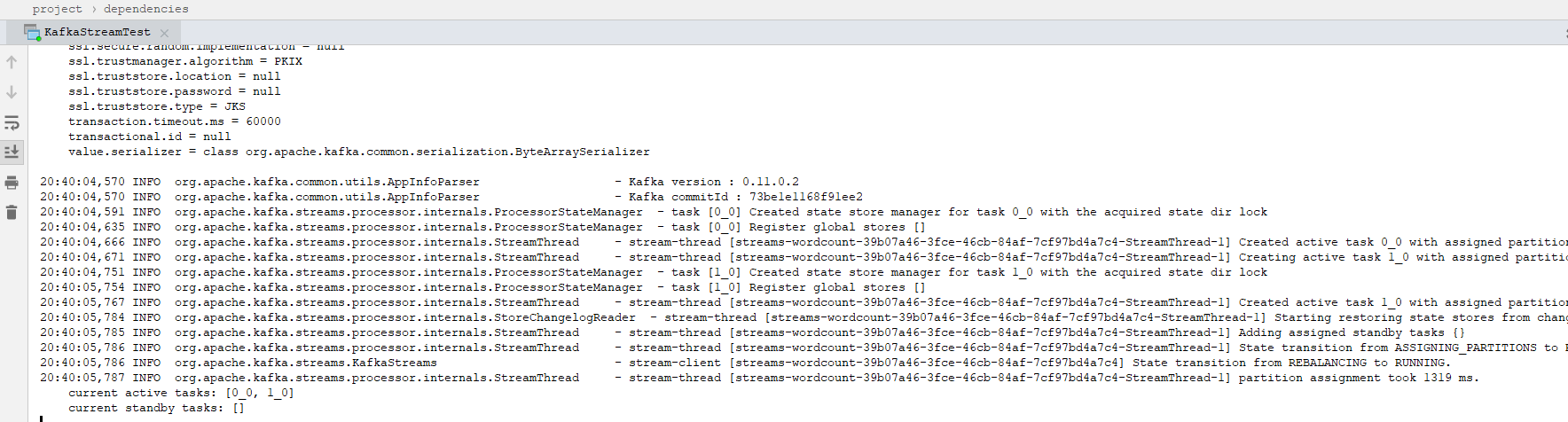
然后启动main方法,运行如下:
5、启动consumer:
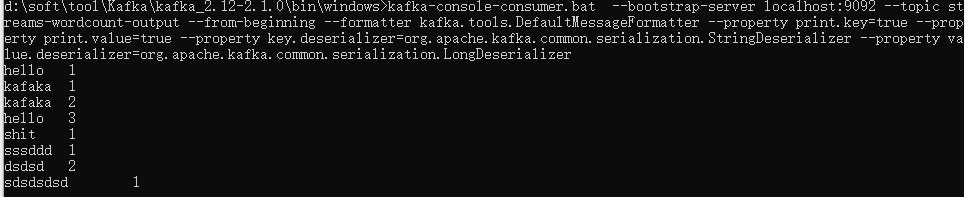
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
展示如下:
按Ctrl + C 退出。
以上就演示了kafka streams 的word-count示例
初探kafka streams的更多相关文章
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams 剖析
1.概述 Kafka Streams 是一个用来处理流式数据的库,属于Java类库,它并不是一个流处理框架,和Storm,Spark Streaming这类流处理框架是明显不一样的.那这样一个库是做什 ...
- 浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视.实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm.Spark Streaming.flink等.我今 ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 手把手教你写Kafka Streams程序
本文从以下四个方面手把手教你写Kafka Streams程序: 一. 设置Maven项目 二. 编写第一个Streams应用程序:Pipe 三. 编写第二个Streams应用程序:Line Split ...
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- 大全Kafka Streams
本文将从以下三个方面全面介绍Kafka Streams 一. Kafka Streams 概念 二. Kafka Streams 使用 三. Kafka Streams WordCount 一. ...
- 简介Kafka Streams
本文从以下几个方面介绍Kafka Streams: 一. Kafka Streams 背景 二. Kafka Streams 架构 三. Kafka Streams 并行模型 四. Kafka Str ...
随机推荐
- API接口通讯参数规范(2)
针对[API接口通讯参数规范]这篇文章留下的几个问题进行探讨. 问题1 试想一下,如果一个http请求返回一个500给我们,那我们是不是都不用看详情都知道该次请求发生了什么?这正是一个标准的结果码意义 ...
- java 并发多线程显式锁概念简介 什么是显式锁 多线程下篇(一)
目前对于同步,仅仅介绍了一个关键字synchronized,可以用于保证线程同步的原子性.可见性.有序性 对于synchronized关键字,对于静态方法默认是以该类的class对象作为锁,对于实例方 ...
- Mondrian + JPivot 环境配置
一.环境准备 特别说明:Mondrian + JPivot 环境笔者已整理调试通过,可直接部署运行. 1.1 环境要求 JDK1.8+ 1.2 环境包说明 从 https://pan.baidu.co ...
- redis的持久化方式RDB和AOF的区别
1.前言 最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据.由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能, ...
- 关于jQuery中的选择器
1:选择器的作用 获取网页的上面的标签元素等等,然后对他进行一些列的操作(添加样式,添加行为...) 2:选择器有哪些 基本选择器,层次选择器,过滤选择器,表单选择器 一:基本选择器 基本选择器是jq ...
- Java 在PDF中添加水印——文本/图片水印
水印是一种十分常用的防伪手段,常用于各种文档.资料等.常见的水印,包括文字类型的水印.图片或logo类型的水印.以下Java示例,将分别使用insertTextWatermark(PdfPageBas ...
- jQuery内容过滤选择器与子元素过滤选择器用法实例分析
jQuery选择器内容过滤 一.:contains(text) 选择器::contains(text)描述:匹配包含给定文本的元素返回值:元素集合 示例: ? 1 2 $("div.mini ...
- SpringAOP术语
2019-03-10/21:12:31 参考博客:MiroKlose AOP术语 1.通知: 通知定义了切面要完成的工作内容和何时完成工作,就是什么时候去做辅助功能,功能具体是什么代码 五种类型 Be ...
- php中读取中文文件夹及文件报错
php读取时出现中文乱码 一般php输出中出现中文乱码我们可用 header ('content:text/html;charset="utf-8"'); php中读取中文文件夹及 ...
- Python笔记-IO编程
IO在计算机中是指input和output(数据输入与输出),涉及到数据交换(磁盘.网络)的地方就需要IO接口. 输入流input stream是指数据从外面(磁盘.网络服务器)流入内存:输出流out ...