[BZOJ]1076 奖励关(SCOI2008)
终于又一次迎来了一道期望DP题,按照约定,小C把它贴了出来。
Description
你正在玩你最喜欢的电子游戏,并且刚刚进入一个奖励关。在这个奖励关里,系统将依次随机抛出k次宝物,每次你都可以选择吃或者不吃(必须在抛出下一个宝物之前做出选择,且现在决定不吃的宝物以后也不能再吃)。 宝物一共有n种,系统每次抛出这n种宝物的概率都相同且相互独立。也就是说,即使前k-1次系统都抛出宝物1(这种情况是有可能出现的,尽管概率非常小),第k次抛出各个宝物的概率依然均为1/n。 获取第i种宝物将得到Pi分,但并不是每种宝物都是可以随意获取的。第i种宝物有一个前提宝物集合Si。只有当Si中所有宝物都至少吃过一次,才能吃第i种宝物(如果系统抛出了一个目前不能吃的宝物,相当于白白的损失了一次机会)。注意,Pi可以是负数,但如果它是很多高分宝物的前提,损失短期利益而吃掉这个负分宝物将获得更大的长期利益。 假设你采取最优策略,平均情况你一共能在奖励关得到多少分值?
Input
第一行为两个正整数k和n,即宝物的数量和种类。以下n行分别描述一种宝物,其中第一个整数代表分值,随后的整数依次代表该宝物的各个前提宝物(各宝物编号为1到n),以0结尾。
Output
输出一个实数,保留六位小数,即在最优策略下平均情况的得分。
Sample Input
1 2
1 0
2 0
Sample Output
1.500000
HINT
1<=k<=100,1<=n<=15,分值为[-10^6,10^6]内的整数。
Solution
关于概率期望的题目让人头大,但是如果你还记得之前的口诀“概率正着做,期望倒着做”,这题就会变得很无脑。
很显然这题要我们求的是期望,所以我们倒着开始思考问题。
我们注意到n的范围小等于15,那还能是什么做法啊,当然是状压啊。
于是我们考虑设计状态,f[i][j]表示取了已经抛出i次物品,并且取了集合为j的物品至少1次,这之后按照最优策略能取到的期望值。
所谓最优策略,实际上就是比较转移代价和目标收益之间的大小关系,
假设我们在状态f[i][j],假设可以取得物品x,我们就要斟酌一下取得x的代价和取得x之后的收益,
也就是比较-w[x]和f[i+1][j|ys[x]]的大小,
如果-w[x]<f[i+1][j|ys[x]],也就是说收益更大,按照最优原则我们应该要取;(为什么是“应该”呢)
反之就是代价更大,按照最优原则我们肯定不能取,但是请注意,不取x也有一个收益,那就是f[i+1][j]。
不过就算取x的收益比代价大,但这两者的差值不一定大于不取x的收益,所以按照最优策略还是要对两者取一个max。
结合上面的思路来看,我们发现f[i][j]永远不可能是负数。
前面说的是能够取得物品x的情况,那么什么时候取不了物品x(未满足x的前提宝物集合)呢?
这种问题还用问?看看你自己设计的状态就知道了吧。
转移方程: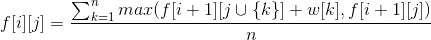 ,
,
其中如果取不了物品k,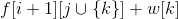 用 0 代替。
用 0 代替。
时间复杂度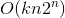 ,虽然复杂度有5亿然而却跑得飞快。
,虽然复杂度有5亿然而却跑得飞快。
#include <cstdio>
#include <algorithm>
#include <cstring>
#define MS 17
#define MN 35005
using namespace std;
int ys[MS],w[MS],prt[MS];
double f[][MN];
int m,n,stp; inline int read()
{
int n=,f=; char c=getchar();
while (c<'' || c>'') {if(c=='-')f=-; c=getchar();}
while (c>='' && c<='') {n=n*+c-''; c=getchar();}
return n*f;
} int main()
{
register int i,j,k,x,lg,rg;
m=read(); n=read();
for (ys[]=,i=;i<=n;++i) ys[i]=ys[i-]<<;
stp=ys[n]<<;
for (i=;i<=n;++i)
for (w[i]=read(),x=read();x;x=read()) prt[i]|=ys[x];
for (i=m-,lg=,rg=;i>=;--i,swap(lg,rg))
for (j=;j<stp;f[lg][j++]/=n)
for (f[lg][j]=,k=;k<=n;++k)
f[lg][j]+=max(((j&prt[k])==prt[k])?f[rg][j|ys[k]]+w[k]:,f[rg][j]);
printf("%.6lf",f[rg][]);
}
Last Word
自己手算一些小数据也是不错的调试技巧。
为了缩行可能代码画风会有点崩坏。
[BZOJ]1076 奖励关(SCOI2008)的更多相关文章
- BZOJ 1076 奖励关 状态压缩DP
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=1076 题目大意: 你正在玩你最喜欢的电子游戏,并且刚刚进入一个奖励关.在这个奖励关里, ...
- scoi 2008 && bzoj 1076 奖励关
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=3223 思路:15?好,状压,OK. 这是转移方程 if((s[k]&j)==s[k] ...
- BZOJ 1076 奖励关
注意几点: 1.为什么要逆推?由此状态可以轻易算出彼状态是否可行,而彼状态却无法轻易还原为此状态. 2.为什么可以逆推?假设时光倒流了....23333 3.注意位运算的准确,大胆写方程. #incl ...
- bzoj 1076 奖励关 状压+期望dp
因为每次选择都是有后效性的,直接dp肯定不行,所以需要逆推. f[i][j]表示从第i次开始,初始状态为j的期望收益 #include<cstdio> #include<cstrin ...
- BZOJ 1076 奖励关(状压期望DP)
当前得分期望=(上一轮得分期望+这一轮得分)/m dp[i,j]:第i轮拿的物品方案为j的最优得分期望 如果我们正着去做,会出现从不合法状态(比如前i个根本无法达到j这种方案),所以从后向前推 如果当 ...
- 【bzoj 1076】【SCOI2008】奖励关
1076: [SCOI2008]奖励关 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 1602 Solved: 891[Submit][Status ...
- 【BZOJ】【1076】【SCOI2008】奖励关
状压DP+数学期望 蒟蒻不会啊……看题跑…… Orz了一下Hzwer,发现自己现在真是太水了,难道不看题解就一道题也不会捉了吗? 题目数据范围不大……100*(2^16)很容易就跑过去了…… DP的时 ...
- 【BZOJ】1076: [SCOI2008]奖励关(状压dp+数学期望)
http://www.lydsy.com/JudgeOnline/problem.php?id=1076 有时候人蠢还真是蠢.一开始我看不懂期望啊..白书上其实讲得很详细的,什么全概率,全期望(这个压 ...
- bzoj 1076: [SCOI2008]奖励关
Description 你正在玩你最喜欢的电子游戏,并且刚刚进入一个奖励关.在这个奖励关里,系统将依次随机抛出k次宝物,每次你都可以选择吃或者不吃(必须在抛出下一个宝物之前做出选择,且现在决定不吃的宝 ...
随机推荐
- EMC CX4-480服务器raid磁盘数据恢复案例
[用户信息]上海某公司 [故障描述]需要进行数据恢复的设备是一台EMC CX4的存储服务器,因为硬盘出现故障导致整个存储阵列瘫痪.整个LUN是由7块1TB的硬盘组成的RAID 5.但服务器共有10块硬 ...
- 剑指offer-数据流中的中位数
题目描述 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值.如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值. ...
- 第三章Hibernate关联映射
第三章Hibernate关联映射 一.关联关系 类与类之间最普通的关系就是关联关系,而且关联是有方向的. 以部门和员工为列,一个部门下有多个员工,而一个员工只能属于一个部门,从员工到部门就是多对一关联 ...
- 使用 BenchmarkDotnet 测试代码性能
先来点题外话,清明节前把工作辞了(去 tm 的垃圾团队,各种拉帮结派.勾心斗角).这次找工作就得慢慢找了,不能急了,希望能找到个好团队,好岗位吧.顺便这段时间也算是比较闲,也能学习一下和填掉手上的坑. ...
- python学习之路01
python自己也自学过一段时间了,看过视频,也买过几本基础的书来看,目前为止对于一些简单的代码还是可以看懂,但是自己总是觉得缺少些什么,可能是缺少系统化的学习,也可能是缺少实际项目经验,对于这些缺少 ...
- Oracle update 执行更新操作后的数据恢复
操作数据库,经常会出现误操作,昨天执行的更新操作之后发现更新错了,只能想办法数据恢复了,现在整理一下 第一步:查询执行更新操作的时间 select r.FIRST_LOAD_TIME,r.* from ...
- Java基础语法<五> 大数值BigInteger BigDecimal
笔记整理 来源于<Java核心技术卷 I > <Java编程思想> 如果基本的整数和浮点数精度不能够满足需求,那么可以使用java.math包中的两个很有平有用的类:BigIn ...
- Android:ImageView控件显示图片
1)android显示图片可以使用imageView来呈现,而且也可以通过ImageButton来实现给button添加图片. 2)在创建一个ImageView后,显示图片绑定元素是:android: ...
- 1.0 添加WEB API项目并按注释生成文档(多项目结构)
1.新建ASP.NET 项目,模板选择如图 2.选择Web API,并选择不进行身份验证方式 成功后我们看到这个结果. 至于其它三种身份验证方式,不太适合我的使用.而且这种方式也可以在代码里去实现身份 ...
- WPF Uri
场景:自定义控件Generic.xaml样式引用资源字典Dictionary1.xaml. 方式:绝对路径. 方式1: <ResourceDictionary> <ResourceD ...