分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部:
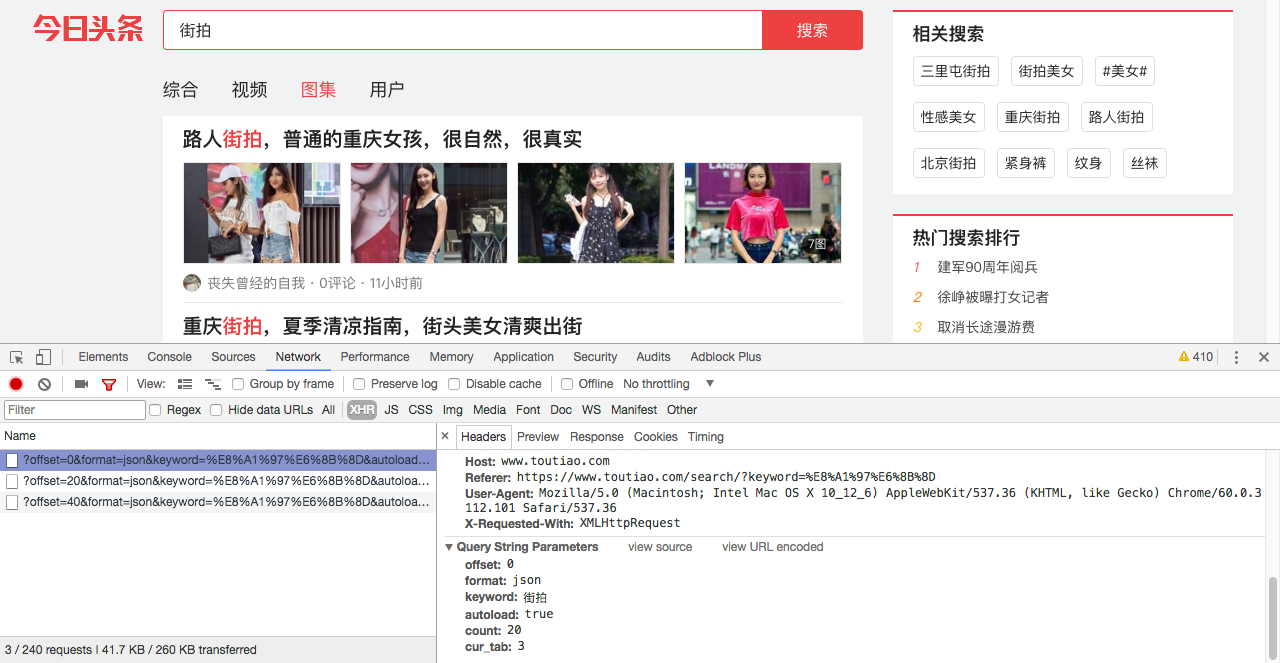
在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url:
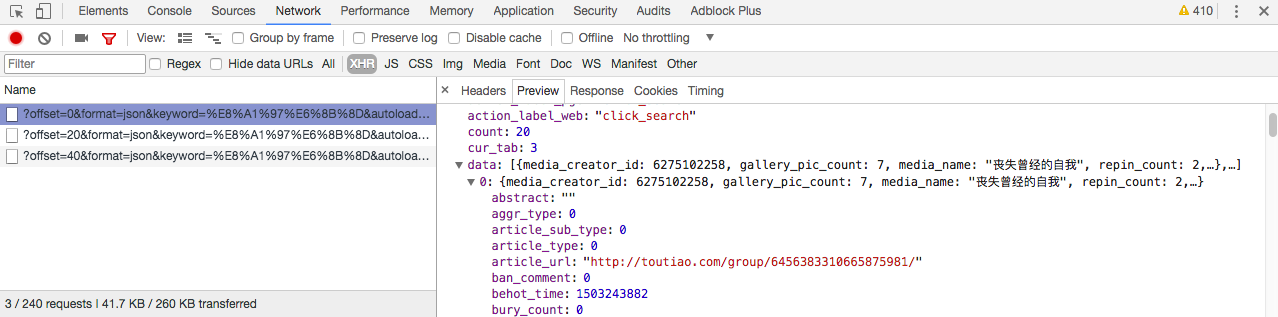
选中其中一张图片,分析 json 请求,可以找到图片地址在 gallery 一栏:
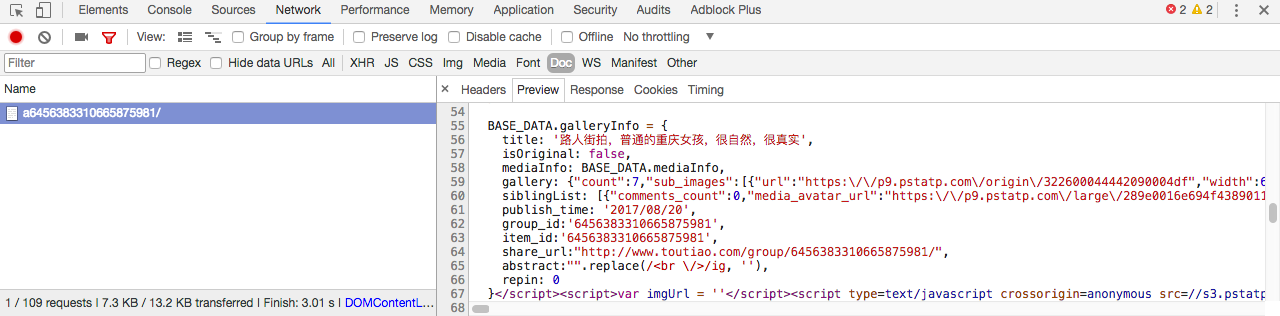
找到图片地址,接下来我们就可以来写代码了:
1.导入必要的库:
import requests
import json
import re
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
from json.decoder import JSONDecodeError
from requests.exceptions import RequestException
from urllib.parse import urlencode
from bs4 import BeautifulSoup
2.获取索引页并分析:
def get_page_index(offset, keyword):
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求索引页出错')
return None def parse_page_index(text):
try:
data = json.loads(text)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
3.获取详情页并分析:
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求详情页出错')
return None def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()
images_pattern = re.compile('gallery: (.*?),\n', re.S)
result = re.search(images_pattern, html)
if result:
data = json.loads(result.group(1))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images:
download_images(image)
return {
'title': title,
'url': url,
'images': images
}
4.使用 MongoDB 数据库存储数据:
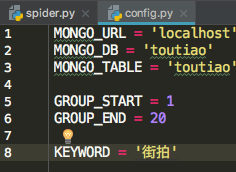
首先定义一个 config.py 文件,配置默认参数:
写入 MongoDB:
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print(' 存储到 MongoDB 成功', result)
return True
5.存储图片到本地:
def download_images(url):
print(' 正在下载', url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print(' 请求图片出错')
return None def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
6.最后定义 main()函数,并开启多线程抓取20页图集:
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close() def main(offset):
text = get_page_index(offset, KEYWORD)
for url in parse_page_index(text):
html = get_page_detail(url)
if html:
result = parse_page_detail(html, url)
if result:
save_to_mongo(result) if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
代码GitHub地址:https://github.com/weixuqin/PythonProjects/tree/master/jiepai
分析 ajax 请求并抓取今日头条街拍美图的更多相关文章
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- python爬虫知识点总结(十)分析Ajax请求并抓取今日头条街拍美图
一.流程框架
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python爬虫系列-分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. 2.抓取详情页内容 解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 3.下载图片与保存数据库 将 ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
随机推荐
- RTMP规范协议
本文参照rtmp协议英文版,进行简单的协议分析 1.什么是RTMP 关于 Adobe 的实时消息协议(Real Time Messaging Protocol,RTMP),是一种多媒体的复用和分组的应 ...
- 庖丁解牛Linux内核学习笔记(1)--计算机是如何工作的
存储程序计算机模型 冯诺依曼体系结构 冯诺依曼体系结构是存储程序计算机,什么叫存储程序计算机?从硬件角度说,假设有cpu和内存,两者通过总线连接,在cpu内部有一个寄存器叫ip(instruction ...
- Beta版本敏捷冲刺每日报告——Day1
1.情况简述 Beta阶段第一次Scrum Meeting 敏捷开发起止时间 2017.11.2 08:00 -- 2017.11.2 21:00 讨论时间地点 2017.11.2晚6:00,软工所实 ...
- tornado options
tornado.options.define() 用来定义options选项变量的方法,定义的变量可以在全局的tornado.options.options中获取使用,传入参数: name 选项变量名 ...
- MobileNet_v2
研究动机: 神经网络彻底改变了机器智能的许多领域,实现了超人的准确性.然而,提高准确性的驱动力往往需要付出代价:现代先进网络需要高度计算资源,超出许多移动和嵌入式应用的能力. 主要贡献: 发明了一个新 ...
- 读取.properties的内容1
属性文件方便于项目进行更改,在项目开发中用的也是非常的普遍,在这里就把属性文件的读取通过代码进行一个小结: package com.oyy.test; import java.io.BufferedI ...
- 【非官方】Surging 微服务框架使用入门
前言 本文非 Surging 官方教程,只是自己学习的总结.如有哪里不对,还望指正. 我对 surging 的看法 我目前所在的公司采用架构就是类似与Surging的RPC框架,在.NET 4.0框架 ...
- Oracle RAC环境下定位并杀掉最终阻塞的会话
实验环境:Oracle RAC 11.2.0.4 (2节点) 1.模拟故障:会话被级联阻塞 2.常规方法:梳理找出最终阻塞会话 3.改进方法:立即找出最终阻塞会话 之前其实也写过一篇相关文章: 如何定 ...
- restful架构风格设计准则(六)版本管理
读书笔记,原文链接:http://www.cnblogs.com/loveis715/p/4669091.html,感谢作者! 版本管理 在前面已经提到过,一个REST系统为资源所抽象出的URI实际上 ...
- hadoop2.6.0实践:002 检查伪分布式环境搭建
1.检查网络配置[root@hadoop-master ~]# cat /etc/sysconfig/networkNETWORKING=yesHOSTNAME=hadoop-masterGATEWA ...