爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页
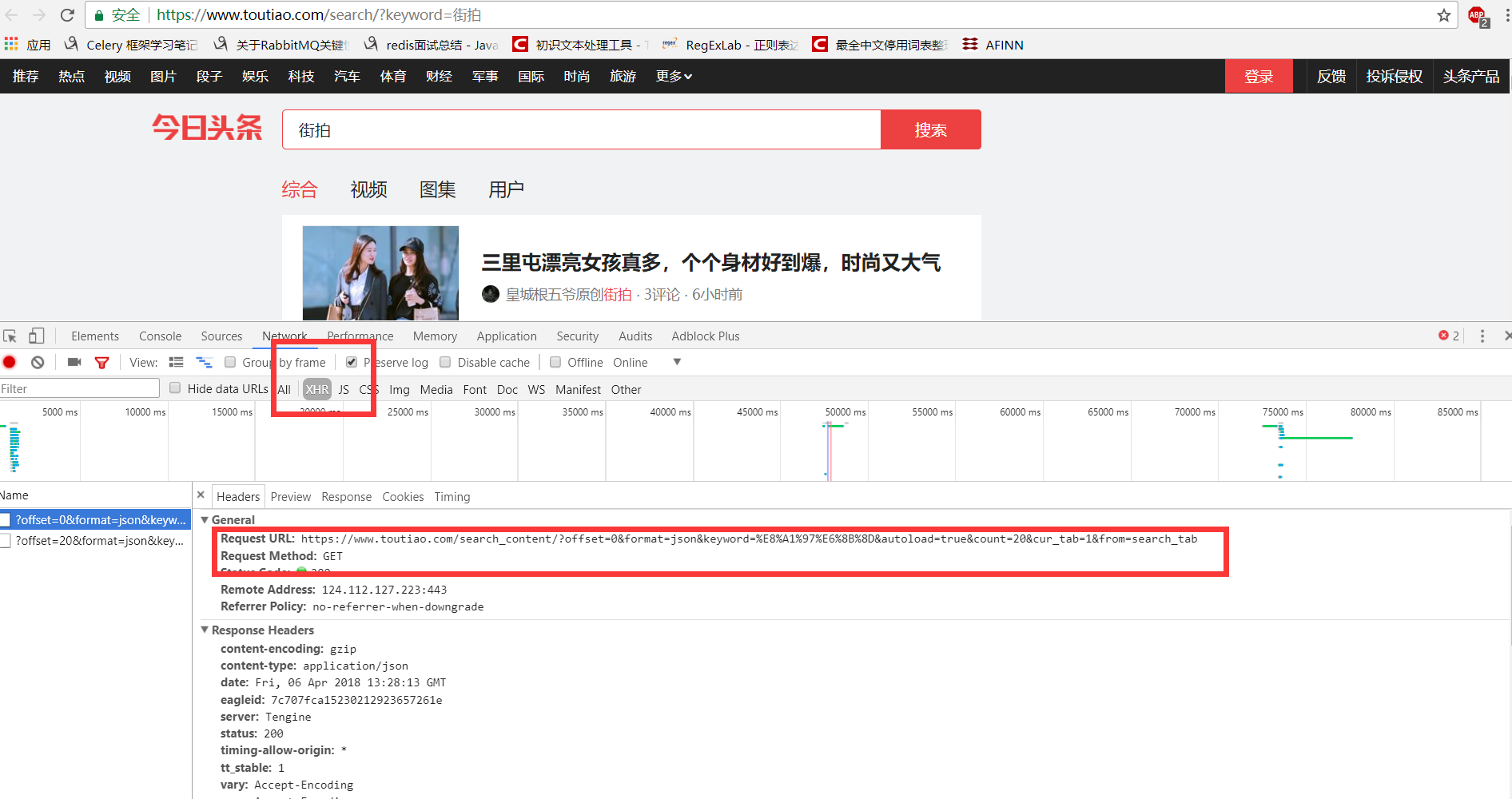
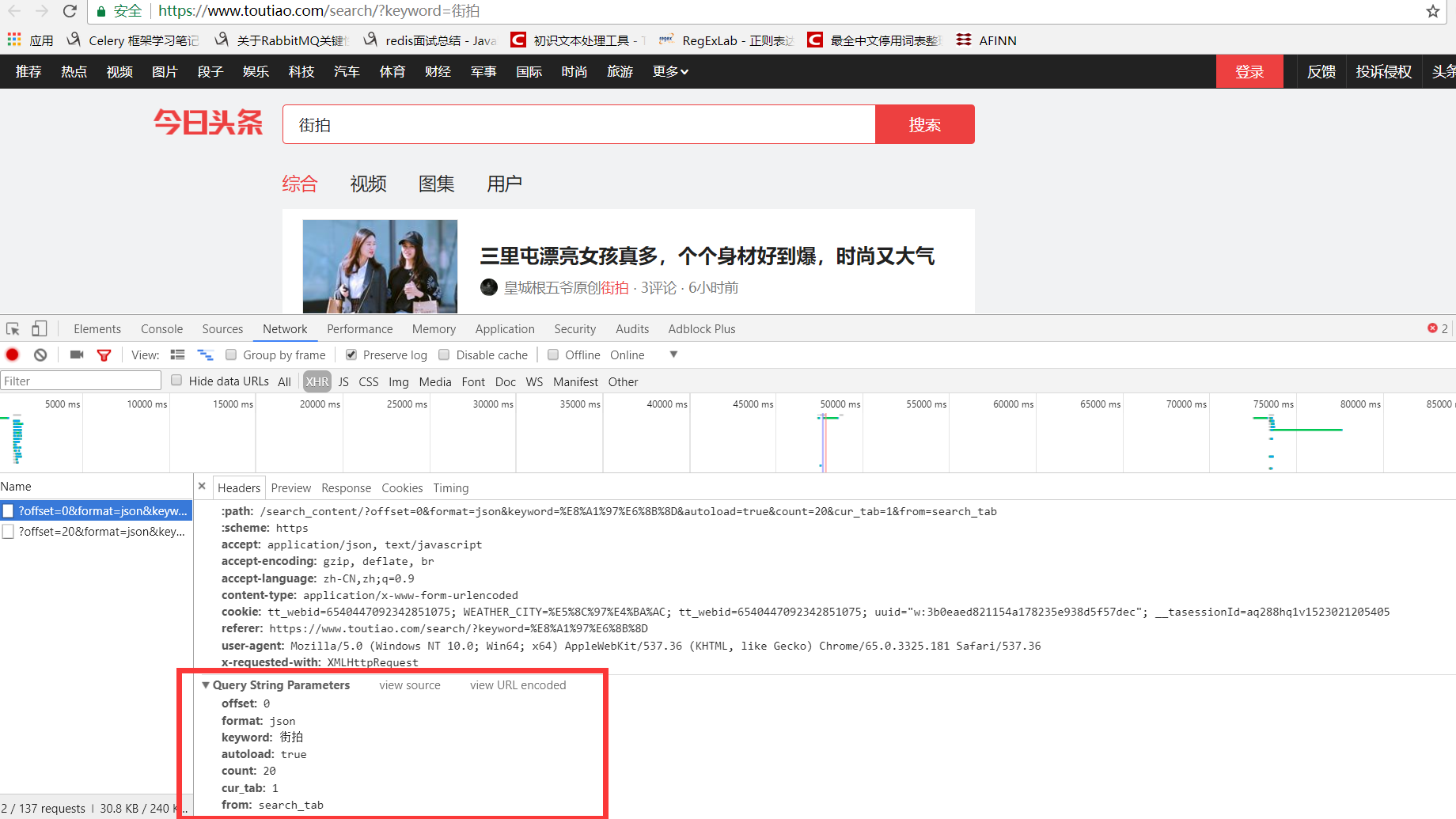
分析ajax的请求网址,和需要的参数。通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求。
(2)上代码
a、通过ajax请求获取页面数据
# 获取页面数据
def get_page_index(offset, keyword):
# 参数通过分析页面的ajax请求获得
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '',
'cur_tab': '',
'from': 'search_tab',
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 将字典转换为url参数形式
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('请求索引页错误')
return None
b、分析ajax请求的返回结果,获取图片集的url
# 分析ajax请求的返回结果,获取图片集的url
def parse_page_index(html):
data = json.loads(html) # 加载返回的json数据
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
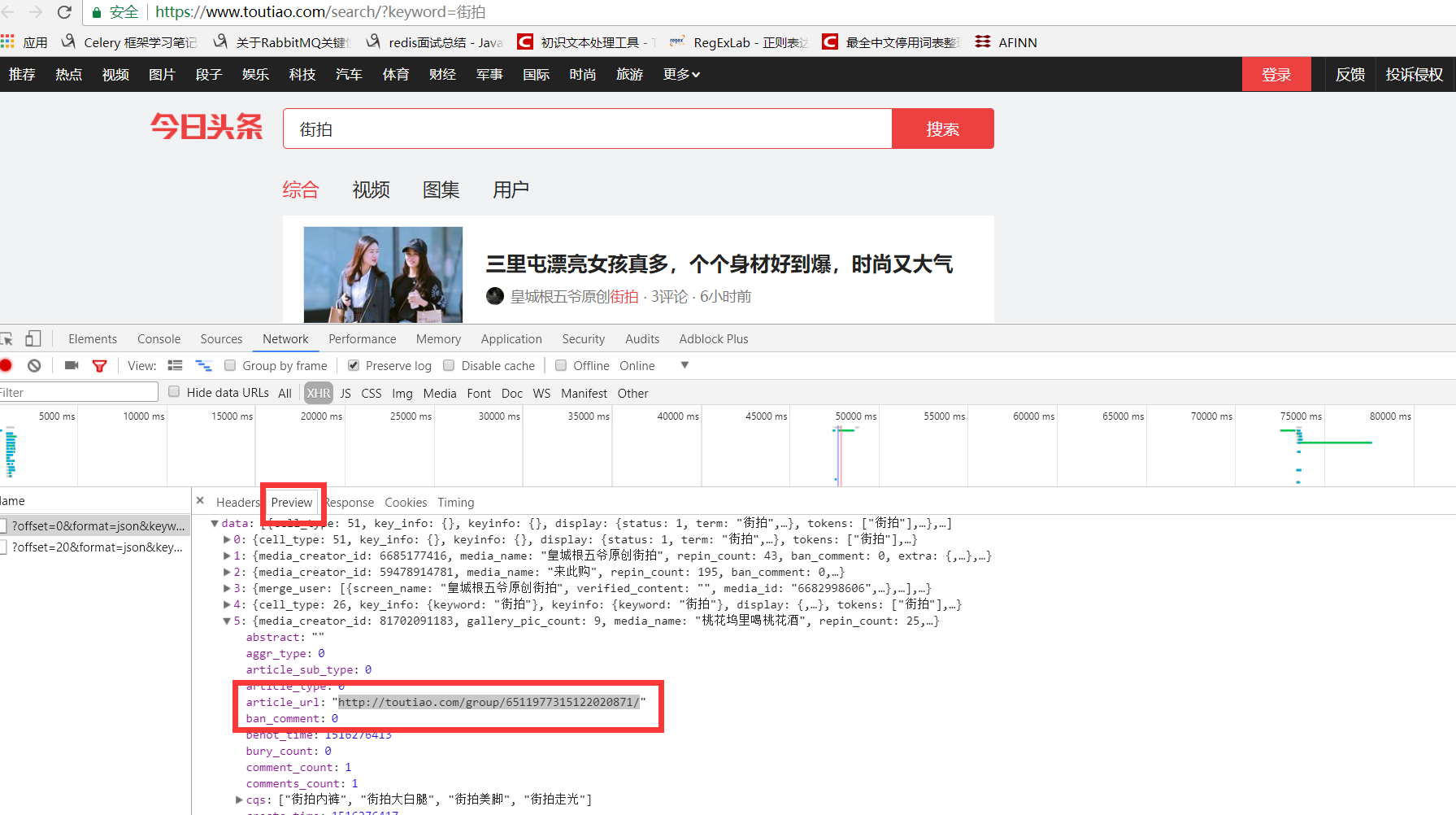
c、得到图集url后获取图集的内容
# 获取详情页的内容
def get_page_detail(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('详情页页错误', url)
return None
d、其他看完整代码
完整代码:
# -*- coding: utf-8 -*-
# @Author : FELIX
# @Date : 2018/4/4 12:49 import json import os
from hashlib import md5 import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import re
import pymongo
from multiprocessing import Pool MONGO_URL='localhost' MONGO_DB='toutiao' MONGO_TABLE='toutiao' GROUP_START=1
GROUP_END=20
KEYWORD='街拍' client = pymongo.MongoClient(MONGO_URL) # 连接MongoDB
db = client[MONGO_DB] # 如果已经存在连接,否则创建数据库 headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
} # 获取页面数据
def get_page_index(offset, keyword):
# 参数通过分析页面的ajax请求获得
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '',
'cur_tab': '',
'from': 'search_tab',
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) # 将字典转换为url参数形式
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('请求索引页错误')
return None # 分析ajax请求的返回结果,获取图片集的url
def parse_page_index(html):
data = json.loads(html) # 加载返回的json数据
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') # 获取详情页的内容
def get_page_detail(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
except RequestException:
print('详情页页错误', url)
return None def parse_page_detail(html, url):
# soup=BeautifulSoup(html,'lxml')
# print(soup)
# title=soup.select('tetle').get_text()
# print(title)
images_pattern = re.compile('articleInfo:.*?title: \'(.*?)\'.*?content.*?\'(.*?)\'', re.S)
result = re.search(images_pattern, html)
if result:
title = result.group(1)
url_pattern = re.compile('"(http:.*?)"')
img_url = re.findall(url_pattern, str(result.group(2)))
if img_url:
for img in img_url:
download_img(img) # 下载
data = {
'title': title,
'url': url,
'images': img_url,
}
return data def save_to_mongo(result):
if result:
if db[MONGO_TABLE].insert(result): # 插入数据
print('存储成功', result)
return True
return False def download_img(url):
print('正在下载', url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
save_img(response.content)
else:
return None
except RequestException:
print('下载图片错误', url)
return None def save_img(content):
# os.getcwd()获取当前文件路径,用md5命名,保证不重复
file_path = '{}/imgs/{}.{}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb')as f:
f.write(content) def main(offset):
html = get_page_index(offset, KEYWORD)
for url in parse_page_index(html):
html = get_page_detail(url)
print(url,'++++++++++++++++++++++++++++++++++++++++++++++++')
print(html)
if html:
result = parse_page_detail(html, url)
save_to_mongo(result)
# print(result)
# print(url) if __name__ == '__main__':
groups = [i * 20 for i in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
爬虫(八):分析Ajax请求抓取今日头条街拍美图的更多相关文章
- python3爬虫-分析Ajax,抓取今日头条街拍美图
# coding=utf-8 from urllib.parse import urlencode import requests from requests.exceptions import Re ...
- 通过分析Ajax请求 抓取今日头条街拍图集
代码: import os import re import json import time from hashlib import md5 from multiprocessing import ...
- 分析Ajax来爬取今日头条街拍美图并保存到MongDB
前提:.需要安装MongDB 注:因今日投票网页发生变更,如下代码不保证能正常使用 #!/usr/bin/env python #-*- coding: utf-8 -*- import json i ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- 分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部: 在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url: 选中其中一张图片,分析 json 请 ...
随机推荐
- Ubuntu 利用 mtd-utils 制作ubifs.img
确保已经安装了有关的工具 sudo apt-get install mtd-utils mkfs.ubifs -d fs -m -o rootfslink.ubiimg -e -c -F -v syn ...
- Jmeter之分布式测试/压测
Jmeter做分布式测试的原因: 测试机器的配置低,对服务器进行压测时,造成不了压力. jmeter并发10000后,测试机就已经卡顿了,而且测试结果有大量失败(忽略了jmeter自身问题=.=||| ...
- zabbix的离线安装方法----孙祎晨,如需转载请注明出处,谢谢配合。
------------------------zabbix的离线安装步骤--------------------------------------------------------------- ...
- babel编译ts
这里用的是babel7 npx babel src --out-dir lib --extensions ".ts"
- 【robotframework】robotframework基本使用
一.创建项目 1.创建测试项目 选择菜单栏 file----->new Project Name 输入项目名称:Type 选择 Directory. 2.创建测试套件 右键点击“测试项目”选择 ...
- ubuntu18.04 安装idea
首先从官网下载idea:IntelliJ IDEA (在安装IDEA前应先安装jdk环境) 得到ideaIU-2019.2.4.tar.gz 将安装包移动到/usr/local,这样可以让所有用 ...
- c# try 和 catch 块
- CSS之特性相关
一.css的继承性与层叠性 继承性: 面向对象语言都会存在继承的概念,在面向对象语言中,继承的特点:继承了父类的属性和方法.那么我们现在主要研究css,css就是在设置属性的.不会牵扯到方法的层面. ...
- IPC——概述
现代操作系统下的内存 现在的OS都引入了虚拟内存机制.我们说的内存空间,实际上虚拟内存空间,CPU执行PC指向的命令,PC指向的就是虚拟内存空间地址.虚拟内存机制只不过是OS为我们做了一层虚拟内存地址 ...
- apache Directory Studio 简易使用
apache Directory Studio 简易使用 本文首发:https://www.somata.work/2019/apacheDirectoryStudioSimpleUse.html 以 ...