分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部:
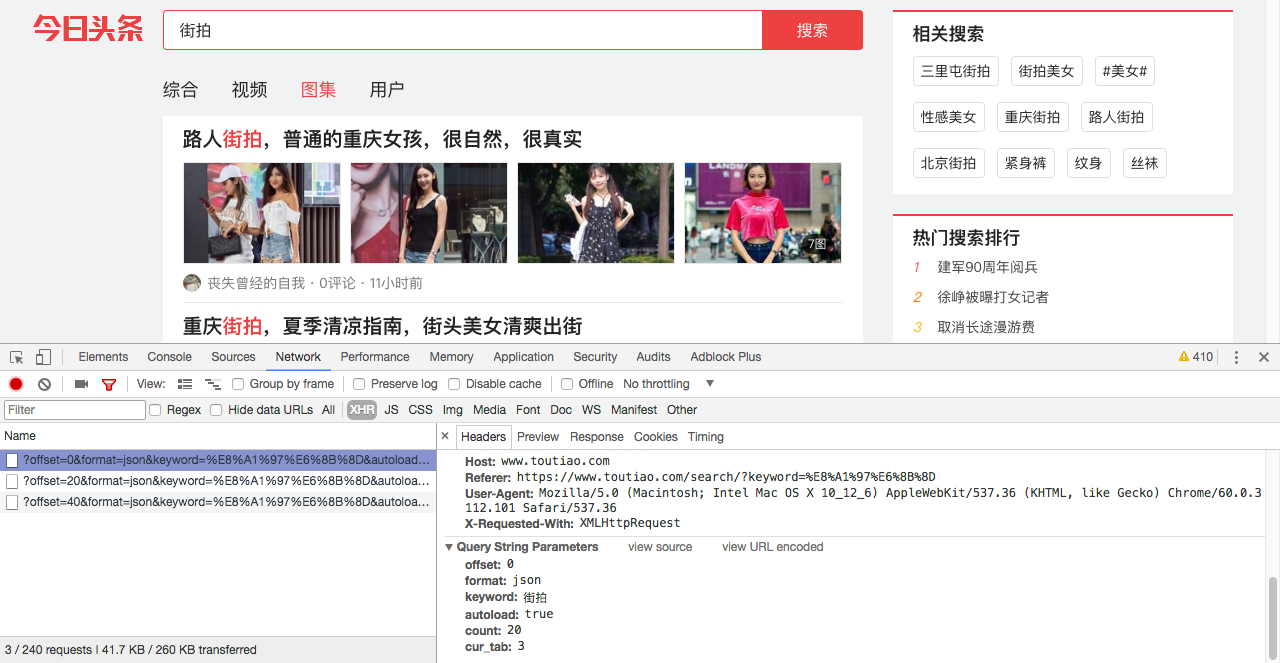
在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url:
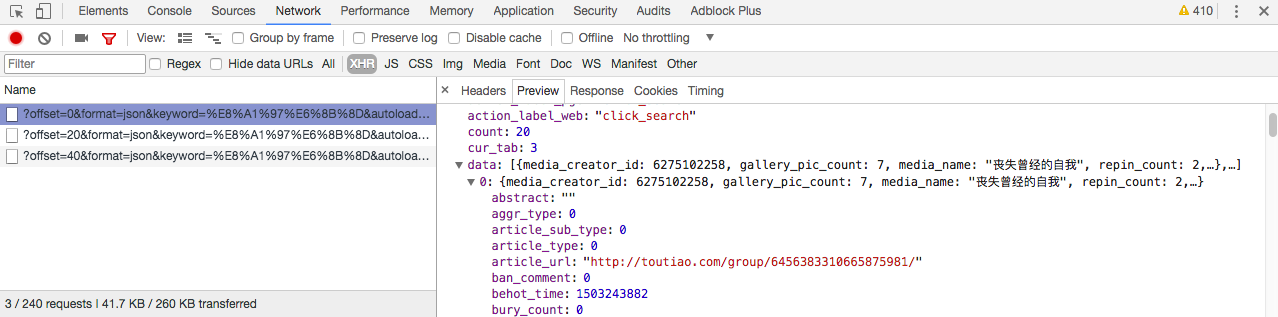
选中其中一张图片,分析 json 请求,可以找到图片地址在 gallery 一栏:
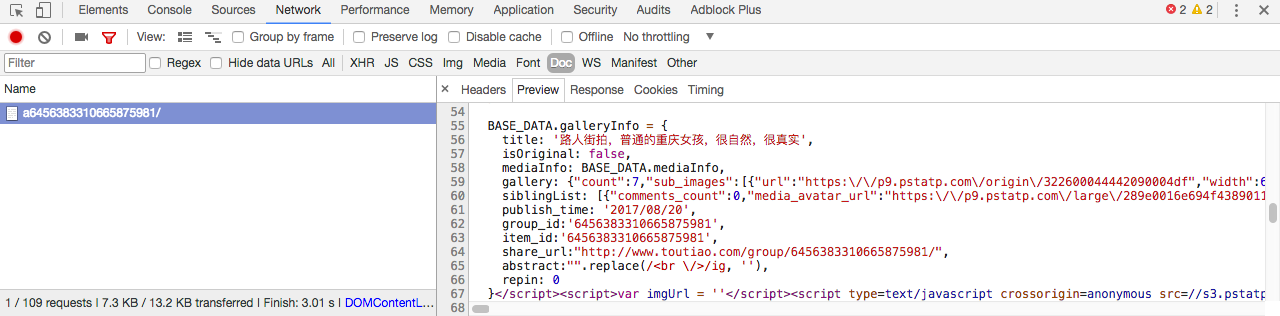
找到图片地址,接下来我们就可以来写代码了:
1.导入必要的库:
import requests
import json
import re
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
from json.decoder import JSONDecodeError
from requests.exceptions import RequestException
from urllib.parse import urlencode
from bs4 import BeautifulSoup
2.获取索引页并分析:
def get_page_index(offset, keyword):
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求索引页出错')
return None def parse_page_index(text):
try:
data = json.loads(text)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
3.获取详情页并分析:
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求详情页出错')
return None def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()
images_pattern = re.compile('gallery: (.*?),\n', re.S)
result = re.search(images_pattern, html)
if result:
data = json.loads(result.group(1))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images:
download_images(image)
return {
'title': title,
'url': url,
'images': images
}
4.使用 MongoDB 数据库存储数据:
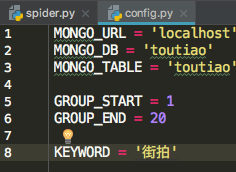
首先定义一个 config.py 文件,配置默认参数:
写入 MongoDB:
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print(' 存储到 MongoDB 成功', result)
return True
5.存储图片到本地:
def download_images(url):
print(' 正在下载', url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print(' 请求图片出错')
return None def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
6.最后定义 main()函数,并开启多线程抓取20页图集:
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close() def main(offset):
text = get_page_index(offset, KEYWORD)
for url in parse_page_index(text):
html = get_page_detail(url)
if html:
result = parse_page_detail(html, url)
if result:
save_to_mongo(result) if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
代码GitHub地址:https://github.com/weixuqin/PythonProjects/tree/master/jiepai
分析 ajax 请求并抓取今日头条街拍美图的更多相关文章
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- python爬虫知识点总结(十)分析Ajax请求并抓取今日头条街拍美图
一.流程框架
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python爬虫系列-分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. 2.抓取详情页内容 解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 3.下载图片与保存数据库 将 ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
随机推荐
- 初学MySQL基础知识笔记--01
本人初入博客园,第一次写博客,在今后的时间里会一点点的提高自己博客的水平,以及博客的排版等. 在今天,我学习了一下MySQL数据库的基本知识,相信关于MySQL的资料网上会有很多,所以我就不在这里复制 ...
- linux小白成长之路10————SpringBoot项目部署进阶
[内容指引] war包部署: jar包部署: 基于Docker云部署. 一.war包部署 通过"云开发"平台初始化的SpringBoot项目默认采用jar形式打包,这也是我们推荐的 ...
- JavaScript(第三十二天)【Ajax】
2005年Jesse James Garrett发表了一篇文章,标题为:"Ajax:A new Approach to Web Applications".他在这篇文章里介绍了一种 ...
- 福州大学软件1715|W班-助教卞倩虹个人简介
各位好,我是卞倩虹 本科阶段的专业是网络工程,通过学校的学习我掌握了基础的网络组网配置技术,常常在机房配置路由器和交换机等相关设备.后来我接触了软件编程,在深入了解和学习后编程语言后,自主开发了一些项 ...
- alpha-咸鱼冲刺day1
一,合照 emmmmm.自然是没有的. 二,项目燃尽图 三,项目进展 登陆界面随意写了一下.(明天用来做测试的) 把学姐给我的模板改成了自家的个人主页界面,侧边栏啥的都弄出来了(快撒花花!) 四,问题 ...
- cpp常用函数总结
//sprintf sprintf(temp_str_result, "%lf", temp_double); result = temp_str_result; (*begin) ...
- PHP、Java、Python、C、C++ 这几种编程语言都各有什么特点或优点
PHP.Java.Python.C.C++ 这几种编程语言都各有什么特点或优点 汇编: C: Java: C#: PHP: Python: Go: Haskell: Lisp: C++: &l ...
- 项目Beta冲刺Day2
项目进展 李明皇 今天解决的进度 优化了信息详情页的布局:日期显示,添加举报按钮等 优化了程序的数据传递逻辑 明天安排 程序运行逻辑的完善 林翔 今天解决的进度 实现微信端消息发布的插入数据库 明天安 ...
- Python入门代码练习
一.循环猜年龄程序,猜错三次则打印提示信息并退出循环,猜对也打印提示信息并退出循环 count=0while count < 3: num = input("猜年龄游戏:") ...
- vue初尝试--新建项目
这是一篇技术贴--如何新建一个基于vue的项目 1.下载对应版本的nodejs安装,下载的nodejs都集成了npm,所以nodejs安装完成之后npm也对应安装完成了. 安装完成之后可以在cmd命令 ...