典型分布式系统分析之MapReduce
在 《分布式学习最佳实践:从分布式系统的特征开始(附思维导图)》一文中,提到学习分布式系统的一个好方法是思考分布式系统要解决的问题,有哪些衡量标准,为了解决这些问题;提出了哪些理论、协议、算法,这些解决办法各自的优缺点、适用场景;然后再思考,不同的系统是如何解决同一个问题的,比如说数据分片,比如说元数据的高可用,到了工程实践这个层面是怎么解决的。
上面是从问题出发,寻找答案。而另一个方法,是从一个具体的系统出发,分析这个分布式系统是如何解决需要解决所有问题,如何根据实际情况对分布式特性进行权衡。比如说对于CAP,是如何在C(一致性)与A(一致性)之间折中的。因此,本系列文章的主题就是了解这些分布式系统是如何满足高性能、可扩展、高可用的一般性要求,各自的衡量标准,使用了哪些算法,有哪些设计巧妙、值得借鉴之处。
刘杰的《分布式系统原理介绍》一文中,也是介绍了分布式系统的诸多概念和协议,然后说道:
“即便如此,笔者觉得后续可以再作一篇《典型分布式系统分析》,从各个系统的角度横向分析这些系统的特点。”
但是我在网上搜索并没有发现相关的文章,本文冒昧地使用了这个题目,而我自己深知,在分布式领域我知之甚少,因此只算得抛砖引玉,希望大牛多指正。如果业界前辈能够有时间来写写这个系列,那就更好了。
在这个系列中,一般都是根据论文对系统进行简介,然后尝试回答一下问题:
- 系统在性能、可扩展性、可用性、一致性之间的衡量,特别是CAP
- 系统的水平扩展是如何实现的,是如何分片的
- 系统的元数据服务器的性能、可用性
- 系统的副本控制协议,是中心化还是去中心化
- 对于中心化副本控制协议,中心是如何选举的
- 系统还用到了哪些协议、理论、算法
本文地址:http://www.cnblogs.com/xybaby/p/8733633.html
MapReduce简介
在google的论文《MapReduce: Simplified Data Processing on Large Clusters》中,MapReduce既指一种编程模型,又指google为这种编程模型开发的一套运行时框架。
MapReduce is a programming model and an associated implementation for processing and generating large data sets.
在《初识分布式计算:从MapReduce到Yarn&Fuxi》一文中,已经对MapReduce进行了详细介绍,而且论文本身也非常容易读懂。所以在本文中,只重述一些重要的点 -- 决定了MapReduce这个系统的特征的点。
这里强调两个概念:Job and Task。在MapReduce中,整个计算任务称之为Job,而被划分的子任务称之为task。Job是对用户而言的,而task是运行框架内部术语。
MapReduce运算模型
MapReduce编程模型来自函数式编程,包含两个最基本的算子:map,reduce
map: (k1, v1) -> [(k2, v2)]
reduce: [(k2, [v2] )] --> [(k3, v3)]
将一个运算任务分解成大量独立正交的子任务,每个子任务通过map算子计算,得到中间结果,然后用reduce算子进行聚合,得到最终结果。这两个算子看起来简单,但很多问题都能用这个模型来解决。
这两个算子有一个很重要的特征:确定性的纯过程调用(pure function),函数既不会修改输入,也不存在中间状态,也没有共享的内存。因此,输入一致的情况下,输出也是一致的,这大大方便了容错性设计。
MapReduce运行框架
运行框架的作用在于提高用户(在这里也是程序员)的生产力,用户只需通过map function、reduce function描述自己的计算问题,而不用关心计算在哪个机器上进行、相互之间如何通信、机器故障如何处理等复杂的问题,因为这些问题本身与计算任务不相关。
运行框架调度流程图如下:
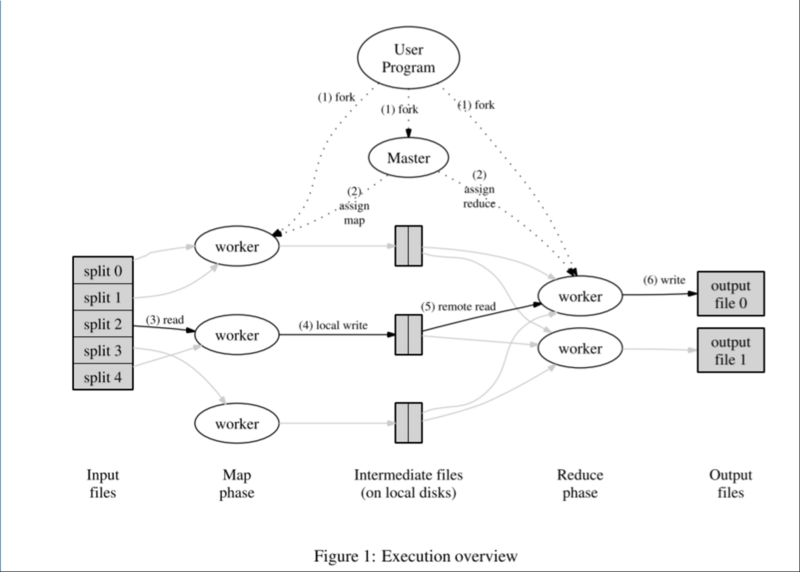
系统中有两类主要的进程节点:master(单点),worker(多个)。其中,worker根据不同的计算任务,又分为map worker(对应上图中的Map phase)、reduce worker(对应上图中的Reduce phase)。
master是系统的中心节点,负责计算任务到worker节点的分配,同时监控worker节点的状态。如果某个worker计算太慢,或者宕机,master会将该worker进程负责的计算任务转移到其他进程。
map worker从GFS(google file system)中读取输入数据,然后将中间结果写到本地文件;reduce worker从master处得知中间结果的问题,通过rpc读取中间文件,计算之后将最终结果写入到可靠存储GFS。
MapReduce系统分析
MapReduce是一个分布式计算系统,计算的数据来自于文件,而且文件系统是可靠的(GFS保证了文件的可用性、可靠性)。
scalability
由于计算任务的正交性,很容易通过增加map worker、reduce worker来处理计算任务的增长。Input file 到 Map phase这个阶段,使用了基于范围(range based)的分片方法,master作为元数据服务器会记录split到worker的映射关系。当用户指定R份最终输出(也就是reduce worker的输出)时,如何对中间结果(intermediate files)进行划分呢?系统默认提供了hash分片方法(e.g. hash(key) mod R), 也允许用户自行提供partition function来进行划分。
在Mapreduce中,子任务(task)的数量要远小于worker的数量,这样的好处在于更好的负载均衡、更快的故障恢复。
We subdivide the map phase into M pieces and the reduce phase into R pieces, as described above.
Ideally,M and R should be much larger than the number of worker machines.
Having each worker perform many different tasks improves dynamic load balancing, and also speeds up recovery when a worker fails: the many map tasksit has completed can be spread out across all the other worker machines.
系统的scalability主要受到master的约束,master是系统中的单点,需要维护每个计算子任务(task)的状态,与所有的worker保持心跳,记录map worker计算的中间结果的文件位置。
avaliability
系统对worker的容错性较好,但对master的容错性较差。
master通过心跳来保证确定worker是否存活,如果心跳超时,那么master标记这个worker failed,然后将该worker所负责的所有task设置为idle(等待计算)状态。在《关于心跳、故障监测、lease机制》一文种中,提到了心跳检测只能保证完整性(completeness),无法保证准确性(accuracy),接下来后分析到,在MapReduce,不准确也是没有关系的。
对于map worker,计算结果是写到本地文件,本地文件的位置需要通知到master,即使同一个task被多个map worker执行,单点的master只会采纳一份中间结果。而且上面提到了map function是pure function,所以计算结果也是一样的。
对于reduce worker,reduce task的计算结果会先写到临时文件(temporary file),task完成之后再重命名写入gfs,那么如果一个reduce task再多个reduce worker上计算,那么会不会有问题呢,答案是不会的
We rely on the atomic renameoperation provided by the underlying file system to guarantee that the final file system state contains just the data produced by one execution of the reduce task.
而由于master是单点,即使有周期性的checkpoint也可能造成状态的不一致,因此MapReduce会将master的crash告知用户,用户可自行决定是否重试整个计算。
performance
MapReduce作为离线计算平台,更多关注的是系统的吞吐率,那么有哪些提高性能的点呢
第一:data locality
在论文中提到,网络传输代价是昂贵的,所以如果worker能从本地文件系统读取数据的话就能尽可能的少网络传输。这也归功于GFS系统,GFS以chuck(对应的就是Input file split)的粒度将每一份文件在不同的机器上保存三份。那么master在掌握了chunk的位置时,就可以将map worker调度到相应的机器,避免网络传输。
第二:backup task
master在发现某个worker上的task进展异常缓慢的时候,会将这个task调度到其他worker,以缩短这个任务(Job)的完成时间。在上面avaliability已经提到,即使有两个worker执行同一份task,也不会有问题的。
总结
MapReduce提供了一个简单但强大的编程范式与运行环境,是一个离线分布式计算系统。MapReduce的最大优点在于易于使用、伸缩性很好。相比分布式存储,分布式计算的状态更少,因此不会出现严重的一致性、可用性问题,由于计算的确定性,通过简单重试就能解决很多问题。
references
MapReduce: Simplified Data Processing on Large Clusters
6.824 Schedule: Spring 2016 LEC 1
典型分布式系统分析之MapReduce的更多相关文章
- 典型分布式系统分析:MapReduce
在 <分布式学习最佳实践:从分布式系统的特征开始(附思维导图)>一文中,提到学习分布式系统的一个好方法是思考分布式系统要解决的问题,有哪些衡量标准,为了解决这些问题:提出了哪些理论.协议. ...
- 典型分布式系统分析: GFS
本文是典型分布式系统分析系列的第二篇,关注的是GFS,一个分布式文件存储系统.在前面介绍MapReduce的时候也提到,MapReduce的原始输入文件和最终输出都是存放在GFS上的,GFS保证了数据 ...
- 典型分布式系统分析:Bigtable
本文是典型分布式系统分析的第三篇,分析的是Bigtable,一个结构化的分布式存储系统. Bigtable作为一个分布式存储系统,和其他分布式系统一样,需要保证可扩展.高可用与高性能.与此同时,Big ...
- 典型分布式系统分析:Dynamo
本文是典型分布式系统分析系列的第四篇,主要介绍 Dynamo,一个在 Amazon 公司内部使用的去中心化的.高可用的分布式 key-value 存储系统. 在典型分布式系统分析系列的第一篇 MapR ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- 分布式处理框架MapReduce的深入简出
1).MapReduce的概述 2).MapReduce 编程模型 3).MapReduce架构 4).MapReduce编程 Google MapReduce论文,论文发表于2004年 Hadoop ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- Hadoop Mapreduce刮
前言 的一个渣渣程序猿一枚,因为个人工作,须要常常和hadoop打交道,可是自己之前没有接触过hadoop.所以算是边学边用,这个博客算是记录一下学习历程,梳理一下自己的思路,请各位看官轻拍.本博客大 ...
- 06_Hadoop分布式文件系统HDFS架构讲解
mr 计算框架 假如有三台机器 统领者master 01 02 03 每台机器都有过滤的应用程序 移动数据 01机== 300M >mr 移动计算 java程序传递给各个机器(mr) ...
随机推荐
- flex布局简析
最近开始对flex布局进行一个重新的认识. 首先. flex布局适用于所有元素 但是注意一点的就是,一旦父级元素设定flex布局的时候,子元素的传统布局属性, float,clear,vertical ...
- GLSL Versions和GLSL ES Versions 对比
You can use the #version command as the first line of your shader to specify GLSL version: #version ...
- 路径字符串数据转化为树型层级对象,path to json tree
由于项目中使用了react 及 ant-design ,在使用tree树型控件时,需要 类似下面的数据, const treeData = [{ title: '0-0', key: '0-0', c ...
- 和sin有关的代码
include include using namespace std; const double TINY_VALUE=1e-10; double tsin(double x) { double g ...
- 上海依图-电话面试-angularjs
树的遍历(树结构:node.name,node.children),输出node.name(递归) 指令的scope的绑定策略(@绑定DOM数学单向绑定:=双向数据绑定:&绑定父作用域函数) ...
- 记录python接口自动化测试--利用unittest生成测试报告(第四目)
前面介绍了是用unittest管理测试用例,这次看看如何生成html格式的测试报告 生成html格式的测试报告需要用到 HTMLTestRunner,在网上下载了一个HTMLTestRunner.py ...
- 项目Beta冲刺预热
Beta准备 1. 讨论组长是否重选的议题和结论. 经过讨论,我们认为,经过一段时间的磨合,现任组长是不需要更换的. 2. 下一阶段需要改进完善的功能. 增加关于征信的功能,贴近选题主题 美化界面,尽 ...
- CoreAnimation注意事项
最近调查的一个bug和内存泄露都和CoreAnimation有关,因此谈一下使用CoreAnimation需要注意的几个问题 CAAnimation的delegate属性是retain的,这个设计确实 ...
- JAVA接口基础知识总结
1:是用关键字interface定义的. 2:接口中包含的成员,最常见的有全局常量.抽象方法. 注意:接口中的成员都有固定的修饰符. 成员变量:public static final 成员方法 ...
- android头像选择(拍照,相册,裁剪)
组织头像上传时候,不兼容android6.0,并且 imageview.setImageBitmap(BitmapFactory.decodeFile(IMAGE_FILE_LOCATION));// ...