使用redis所维护的代理池抓取微信文章
搜狗搜索可以直接搜索微信文章,本次就是利用搜狗搜搜出微信文章,获得详细的文章url来得到文章的信息.并把我们感兴趣的内容存入到mongodb中。
因为搜狗搜索微信文章的反爬虫比较强,经常封IP,所以要在封了IP之后切换IP,这里用到github上的一个开源类,当运行这个类时,就会动态的在redis中维护一个ip池,并通过flask映射到网页中,可以通过访问 localhost:5000/get/
来获取IP
这是搜狗微信搜索的页面,

构造搜索url .搜索时会传递的参数,通过firefox浏览器可以查到:
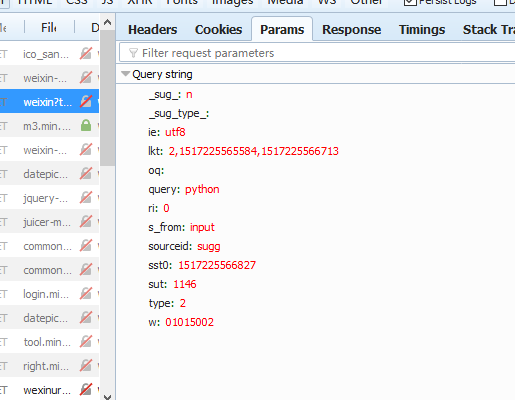
具体代码如下,其中关键部分已添加注释
from urllib.parse import urlencode
import requests
from settings import *
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
import pymongo
from lxml.etree import XMLSyntaxError class WeixinArticle(object):
"""
通过搜狗搜索微信文章,爬取到文章的详细内容,并把我们感兴趣的内容存入到mongodb中
因为搜狗搜索微信文章的反爬虫比较强,经常封IP,所以要在封了IP之后切换IP,这里用到github上的一个开源类,
当运行这个类时,就会动态的redis中维护一个ip池,并通过flask映射到网页中,可以通过访问 localhost:5000/get/
来获取IP,
"""
# 定义一个全局变量,这样在各个函数中均可以使用,就不用在传递这个变量
proxy = None def __init__(self):
self.keyword = KEYWORD
self.proxy_pool_url = PROXY_POOL_URL
self.max_count = MAX_COUNT
self.mongo_url = MONGO_URL
self.mongo_db = MONGO_DB
self.base_url = BASE_URL
self.headers = HEADERS
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db] def get_proxy(self, url):
"""获取我们所维护的IP"""
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return self.get_proxy(url) def get_html(self, url, count=1):
"""
通过传的url 获取搜狗微信文章页面信息,
:param count: 表示最后递归的次数
:return: 页面的信息
"""
if not url:
return None
if count >= self.max_count:
print("try many count ")
return None
print('crowling url ', url)
print('crowling count ', count)
# 定义一个全局变量,这样在各个函数中均可以使用,就不用在传递这个变量
global proxy
try:
if self.proxy:
# 如果有代理就用代理去访问
proxy = {
"http": "http://" + proxy,
}
response = requests.get(url=url, allow_redirects=False, headers=self.headers, proxy=proxy)
else:
# 如果没有代理就不用代理去访问
response = requests.get(url=url, allow_redirects=False, headers=self.headers)
if response.status_code == 200:
print(response.text)
return response.text
elif response.status_code == 302:
# 如果重定向了,说明我们的IP被ban了,此时就要更换代理
print("status code is 302 ")
proxy = self.get_proxy(self.proxy_pool_url)
if proxy:
print("Useing proxy: ", proxy)
return self.get_html(url)
else:
# 如果我们的代理都获取失败,那这次爬取就完全失败了,此时返回None
print("Get proxy failed")
return None
else:
print("Occur Error : ", response.status_code)
except ConnectionError as e:
# 我们只是递归调用max_count 这么多次,防止无限递归
print("Error Occured ", e.args)
count += 1
proxy = self.get_proxy(self.proxy_pool_url)
return self.get_html(url, count) def get_index(self, keyword, page):
"""use urlencode to constract url"""
data = {
"query": keyword,
"type": 2,
# "s_from": "input",
# "ie": "utf8",
"page": page
}
queries = urlencode(data)
url = self.base_url + queries
# 为了让程序的的流程更直观,可以不在这里调用 get_html函数,在main函数中调用
# print(url)
# html = get_html(url)
# return html
return url def parse_index_html(self, html):
"""解析get_html函数得到的html,即是通过关键字搜索的搜狗页面,解析这个页面得到微信文章的url"""
# print(html)
if not html:
"""如果传进来的html是None,则直接返回"""
print("the html is None")
return None
try:
doc = pq(html)
items = doc(".news-box .news-list li .txt-box h3 a").items()
for item in items:
article_urls = item.attr("href")
for article_url in article_urls:
# 在程序中做了迭代之后,在主程序中就可以不用迭代,这样mian函数中的逻辑会更清楚
yield article_url
except UnicodeDecodeError:
print("UnicodeDecodeError error") def get_detail(self, url):
"""通过parse_index_html函数得到微信文章的url,利用requests去得到这个url的网页信息"""
print("get_detail url :",url)
try:
response = requests.get(url,headers=self.headers)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None def parse_detail(self, html):
"""解析通过get_detail函数得到微信文章url网页信息,得到我们想要的信息"""
if not html:
return None
try:
doc = pq(html)
title = doc('#activity-name').text()
content = doc(".rich_media_content p span").text()
date = doc("#post-date").text()
weichat_name = doc("#post-user").text()
return {
"title": title,
"content": content,
"date": date,
"weichat_name": weichat_name,
}
except XMLSyntaxError:
return None def save_to_mongo(self, data):
"""保存到mongodb 中,这里我们希望 title 不重复,所以用update 这种方式进行更新"""
if self.db['articls'].update({"title": data["title"]}, {"$set": data}, True):
print("save to mongo ")
else:
print("save to mongo failed ", data["title"]) def main(self):
"""
这个爬虫的主要逻辑就在main函数中,
我在所有的处理函数都加了异常处理,和当传入的值是None时的处理,所以在main函数就不用做处理
""" keyword = self.keyword
for page in range(1, 5):
url = self.get_index(keyword, page)
html = self.get_html(url)
article_url = self.parse_index_html(html)
article_html = self.get_detail(article_url)
article_data = self.parse_detail(article_html)
self.save_to_mongo(article_data) def run(self):
self.main() if __name__ == "__main__":
weixin_article = WeixinArticle()
weixin_article.run()
之后,把这们常用的配置写在settings.py,方便程序的修改。
KEYWORD="风景"
PROXY_POOL_URL="http://127.0.0.1:5000"
MAX_COUNT=5
MONGO_URL="localhost"
MONGO_DB="weixin"
BASE_URL = "http://weixin.sogou.com/weixin?"
HEADERS = {
# "Accept": "* / *",
# "Accept-Encoding": "gzip, deflate",
# "Accept-Language": "zh-CN,zh;q=0.9",
# "Connection": "keep-alive",
# "Cookie": "SUID=2FF0747C4990A000000005A45FE0C; SUID=59A4FF3C52110A0000005A45FE0D; weixinIndexVisited=1; SUV=00E75AA0A99675A45FE104A7DA232; CXID=B3DDF3C9EA20CECCB4F94A077C74ED; ad=Xkllllllll0U1lllllVNllll9lllll9qxlw@@@@@@@@@@@; ABTEST=0|1517209704|v1; SNUID=D8A7384B3C395FD4BC22C3DDE2172; JSESSIONID=aaa3zBm9sI7SGeZhCaCew; ppinf=5|1517210191|8419791|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZToxODolRTYlODElODElRTYlODAlODJ8Y3J0OjEwOjE1MTcyMTAxOTF8cmzoxODolRTYlODElODElRTYlODAlODJ8dXNlcmlkOjQ0Om85dDJsdUN1Rm5aVTlaNWYzMGpjDUGN6NW9Ad2VpeGluLnNvaHUuY29tfA; pprdig=m",
"Host": "account.sogou.com",
"Referer": "http://weixin.sogou.com/weixin?query=python&s_from=input&type=2&page=10&ie=utf8",
"Upgrade-Insecure-Requests": "",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
项目目录结构如下:
关于怎么使用redis维护一个IP代理池,我会在另一篇博客中作说明.
使用redis所维护的代理池抓取微信文章的更多相关文章
- 4.使用Redis+Flask维护动态代理池
1.为什么使用代理池 许多⽹网站有专⻔门的反爬⾍虫措施,可能遇到封IP等问题. 互联⽹网上公开了了⼤大量量免费代理理,利利⽤用好资源. 通过定时的检测维护同样可以得到多个可⽤用代理理. 2.代理池的要 ...
- 转载:使用redis+flask维护动态代理池
githu源码地址:https://github.com/Germey/ProxyPool更好的代理池维护:https://github.com/Python3WebSpider/ProxyPool ...
- 使用redis+flask维护动态代理池
在进行网络爬虫时,会经常有封ip的现象.可以使用代理池来进行代理ip的处理. 代理池的要求:多站抓取,异步检测.定时筛选,持续更新.提供接口,易于提取. 代理池架构:获取器,过滤器,代理队列,定时检测 ...
- [Python爬虫] 之十五:Selenium +phantomjs根据微信公众号抓取微信文章
借助搜索微信搜索引擎进行抓取 抓取过程 1.首先在搜狗的微信搜索页面测试一下,这样能够让我们的思路更加清晰 在搜索引擎上使用微信公众号英文名进行“搜公众号”操作(因为公众号英文名是公众号唯一的,而中文 ...
- 代理池抓取基础版-(python协程)--抓取网站(西刺-后期会持续更新)
# coding = utf- __autor__ = 'litao' import urllib.request import urllib.request import urllib.error ...
- asp.net MVC 抓取微信文章数据(正文)
1.抓微信的正文主要是调用第三方的接口(https://market.aliyun.com/products/56928004/cmapi012134.html) using Newtonsoft.J ...
- asp.net mvc抓取微信文章里面所有的图片
/// <summary> /// 下载指定URL下的所有图片 /// </summary> public class WebPageImage { /// <summa ...
- 利用 Flask+Redis 维护 IP 代理池
代理池的维护 目前有很多网站提供免费代理,而且种类齐全,比如各个地区.各个匿名级别的都有,不过质量实在不敢恭维,毕竟都是免费公开的,可能一个代理无数个人在用也说不定.所以我们需要做的是大量抓取这些免费 ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
随机推荐
- UVAlive 3708 Graveyard(最优化问题)
题目描述: 在周长10000的圆上,初始等距的放置着n个雕塑,现在新加入m个雕塑,要使得这n+m个雕塑仍然等距,问原来n个雕塑要移动的距离总和的最小值. 原题地址: http://acm.hust.e ...
- UESTC1599-wtmsb-优先队列
wtmsb Time Limit: 1000/100MS (Java/Others) Memory Limit: 131072/131072KB (Java/Others) 这天,AutSky_Jad ...
- BZOJ2726: [SDOI2012]任务安排
题目:http://www.lydsy.com/JudgeOnline/problem.php?id=2726 倒着做,前面的点对后面的点都是有贡献的. f[i]=min(f[j]+cost[i]*( ...
- codeforce 367dev2_c dp
codeforce 367dev2_c dp 标签: dp 题意: 你可以通过反转任意字符串,使得所给的所有字符串排列顺序为字典序,每次反转都有一定的代价,问你最小的代价 题解:水水的dp...仔细想 ...
- Redis进阶实践之四Redis的基本数据类型
一.引言 今天正式开始了Redis的学习,如果要想学好Redis,必须先学好Redis的数据类型.Redis为什么会比以前的Memchaed等内存缓存软件使用的更频繁,适用范围更广呢?就是因为R ...
- 解决 重启nginx: [alert] kill(189, 1) failed (3: No such process)
解决 nginx: [alert] kill(189, 1) failed (3: No such process) [root@localhost/]# nginx -s reloadnginx: ...
- 深入设计电子计算器(一)——CPU框架及指令集设计
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖.如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/8278418.html 作者:窗户 Q ...
- 程序员听到bug后的N种反应,太形象了
程序员的世界里,不止有代码,还有bug,bug,bug 当出现bug时,程序员们的反应是怎样的呢?
- linux日志查看命令
tail tail 命令用于显示文本文件的末尾几行, 对于监控文件日志特别有用 tail example.txt #显示文件 example.txt 的后十行内容: tail -n 20 exampl ...
- Spark算子--first、count、reduce、collect、lookup
转载请标明出处http://www.cnblogs.com/haozhengfei/p/4b8582c8dde1529abb11e4ccc8296171.html first.count.reduce ...