利用 Flask+Redis 维护 IP 代理池
代理池的维护
目前有很多网站提供免费代理,而且种类齐全,比如各个地区、各个匿名级别的都有,不过质量实在不敢恭维,毕竟都是免费公开的,可能一个代理无数个人在用也说不定。所以我们需要做的是大量抓取这些免费代理,然后筛选出其中可用的代理存储起来供我们使用,不可用的进行剔除。
获取代理途径
维护一个代理池第一步就是要找到提供免费代理的站点,例如PROXY360,网页内容如下:
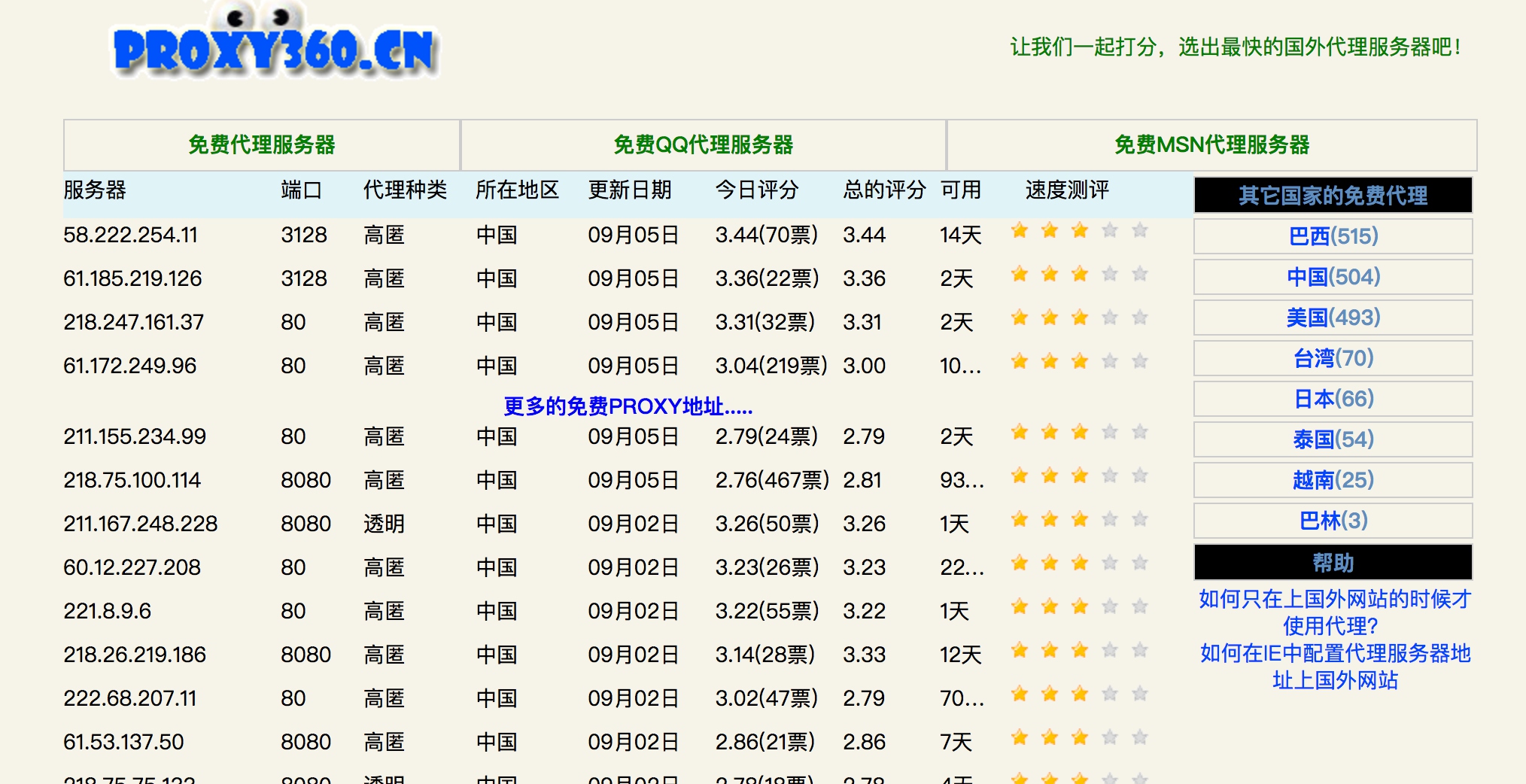
可以看到网页里提供了一些免费代理列表,包括服务器地址、端口、代理种类、地区、更新时间等等信息。
当前我们需要的就是代理服务器和端口信息,将其爬取下来即可。
维护代理
那么爬取下代理之后怎样保存呢?
首先我们需要确保的目标是可以边取边存,另外还需要定时检查队列中不可用的代理将其剔除,所以需要易于存取。
另外怎样区分哪些是最新的可用的,哪些是旧的,如果用修改时间来标注是可以的,不过更简单的方法就是维护一个队列,只从一端存入,例如右端,这样就能确保最新的代理在队列右端,而在左端则是存入时间较长的代理,如果要取一个可用代理,从队列右端取一个就好了。
那么对于队列的左端,不能让它一直老化下去,还需要做的操作就是定时从队列左端取出代理,然后进行检测,如果可用,重新将其加入右端。
通过以上操作,就保证了代理一直是最新可用的。
所以目前来看,既能高效处理,又可以做到队列动态维护,合适的方法就是利用Redis数据库的队列。
可以定义一个类来维护一个Redis队列,比如get方法是批量从左端取出代理,put方法是从右端放入可用代理,pop方法是从右端取出最新可用代理。
import redis
from proxypool.error import PoolEmptyError
from proxypool.setting import HOST, PORT
class RedisClient(object):
def __init__(self, host=HOST, port=PORT):
self._db = redis.Redis(host, port)
def get(self, count=1):
proxies = self._db.lrange("proxies", 0, count - 1)
self._db.ltrim("proxies", count, -1)
return proxies
def put(self, proxy):
self._db.rpush("proxies", proxy)
def pop(self):
try:
return self._db.rpop("proxies").decode('utf-8')
except:
raise PoolEmptyError
检测代理
那么如何来检测代理是否可用?可以使用这个代理来请求某个站点,比如百度,如果获得正常的返回结果,那证明代理可用,否则代理不可用。
conn = RedisClient()
proxies = {'http': proxy}
r = requests.get('https://www.baidu.com', proxies=proxies)
if r.status_code == 200:
conn.put(proxy)
例如在这里proxy就是要检测的代理,使用requests库设置好这个代理,然后请求百度,正常请求,那就可以将这个代理存入Redis。
获取可用代理
现在我们维护了一个代理池,那么这个代理池需要是可以公用的。
比如现在有多个爬虫项目都需要用到代理,而代理池的维护作为另外的一个项目,他们之间如果要建立连接,最恰当的方式就是接口。
所以可以利用Web服务器来实现一个接口,其他的项目通过请求这个接口得到内容获取到一个可用代理,这样保证了代理池的通用性。
所以要实现这个还需要一个Web服务器,例如Flask,Tornado等等。
例如使用Flask,定义一个路由,然后调用的RedisClient的pop方法,返回结果即可。
@app.route('/')
def get_proxy():
conn = RedisClient()
return conn.pop()
这样一来,整个程序运行起来后,请求网页就可以看到一个可用代理了。
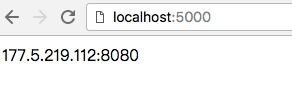
使用代理
使用代理时只需要请求这个站点,就可以拿到可使用的代理了。
def get_proxy():
r = requests.get('http://127.0.0.1:5000')
return r.text
def crawl(url, proxy):
proxies = {'http': get_proxy()}
r = requests.get(url, proxies=proxies)
# do something
可以定义一个简单的方法,返回网页内容即代理,然后在爬取方法里设置代理使用即可。
样例实现
https://github.com/Germey/ProxyPool
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
利用 Flask+Redis 维护 IP 代理池的更多相关文章
- Flask开发系列之Flask+redis实现IP代理池
Flask开发系列之Flask+redis实现IP代理池 代理池的要求 多站抓取,异步检测:多站抓取:指的是我们需要从各大免费的ip代理网站,把他们公开的一些免费代理抓取下来:一步检测指的是:把这些代 ...
- Scrapy加Redis加IP代理池实现音乐爬虫
音乐爬虫 关注公众号"轻松学编程"了解更多. 目的:爬取歌名,歌手,歌词,歌曲url. 一.创建爬虫项目 创建一个文件夹,进入文件夹,打开cmd窗口,输入: scrapy star ...
- 4.使用Redis+Flask维护动态代理池
1.为什么使用代理池 许多⽹网站有专⻔门的反爬⾍虫措施,可能遇到封IP等问题. 互联⽹网上公开了了⼤大量量免费代理理,利利⽤用好资源. 通过定时的检测维护同样可以得到多个可⽤用代理理. 2.代理池的要 ...
- 记一次企业级爬虫系统升级改造(六):基于Redis实现免费的IP代理池
前言: 首先表示抱歉,春节后一直较忙,未及时更新该系列文章. 近期,由于监控的站源越来越多,就偶有站源做了反爬机制,造成我们的SupportYun系统小爬虫服务时常被封IP,不能进行数据采集. 这时候 ...
- 使用redis所维护的代理池抓取微信文章
搜狗搜索可以直接搜索微信文章,本次就是利用搜狗搜搜出微信文章,获得详细的文章url来得到文章的信息.并把我们感兴趣的内容存入到mongodb中. 因为搜狗搜索微信文章的反爬虫比较强,经常封IP,所以要 ...
- ip代理池的爬虫编写、验证和维护
打算法比赛有点累,比赛之余写点小项目来提升一下工程能力.顺便陶冶一下情操 本来是想买一个服务器写个博客或者是弄个什么FQ的东西 最后刷知乎看到有一个很有意思的项目,就是维护一个「高可用低延迟的高匿IP ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- Python爬虫之ip代理池
可能在学习爬虫的时候,遇到很多的反爬的手段,封ip 就是其中之一. 对于封IP的网站.需要很多的代理IP,去买代理IP,对于初学者觉得没有必要,每个卖代理IP的网站有的提供了免费IP,可是又很少,写了 ...
- 5 使用ip代理池爬取糗事百科
从09年读本科开始学计算机以来,一直在迷茫中度过,很想学些东西,做些事情,却往往陷进一些技术细节而蹉跎时光.直到最近几个月,才明白程序员的意义并不是要搞清楚所有代码细节,而是要有更宏高的方向,要有更专 ...
随机推荐
- Updated: Database Partitioning with EBS Whitepaper
Partitioning allows a single database table and its associated indexes to be broken into smaller com ...
- jvm最大线程数
摘自:http://sesame.iteye.com/blog/622670 工作中碰到过这个问题好几次了,觉得有必要总结一下,所以有了这篇文章,这篇文章分为三个部分:认识问题.分析问题.解决问题. ...
- 012-对象——魔术常量__CLASS__ __METHOD__ __FUNCTION__ __DIR__ __FILE__
<?php /** *魔术常量__CLASS__ __METHOD__ __FUNCTION__ __DIR__ __FILE__ */ //魔术常量:__CLASS__ 得到类名. /*cla ...
- 条款20:在传递对象的时候尽量用reference-to-constent来代替,pass-by-value
注意一下,c++的底层编译器而言,引用类型往往都是由指针来实现出来的,所以pass-by-reference实际意义上往往是传递了一个指针,这对于c++的内置类型来说往往传递一个reference更加 ...
- 在Windows下为PHP5.6安装redis扩展
Redis 安装 Window 下安装 下载地址:https://github.com/MSOpenTech/redis/releases. Redis 支持 32 位和 64 位.这个需要根据你系统 ...
- CoreData / MagicalRecord
CoreData 之前在学习使用SQLite时, 需要编写大量的sql语句,完成数据的增删改查,但对于不熟悉sql语句的开发人员来说,难度较大,调试程序比较困难.由此出现CoreData框架,将sql ...
- dateTimePicker编辑状态下,取值不正确的问题
当对dateTimePicker进行编辑,回车,调用函数处理dateTimePicker的value值时,其取值结果是你编辑之前的值,而不是你编辑后的值,虽然dateTimePicker.text的值 ...
- verilog case 语句合并问题
有时候在case语句中会有不同选择执行相同操作的情况,为了简化代码,可以将其合并. 以下解答来自百度知道(由于排版问题,有相应修改): reg [1:0]addr_cnt=2'b11; reg rea ...
- Django初体验——搭建简易blog
前几天在网上看到了篇采用Django搭建简易博客的视频,好奇心驱使也就点进去学了下,毕竟自己对于Django是无比敬畏的,并不是很了解,来次初体验. 本文的操作环境:ubuntu.python2.7. ...
- shfileoperation 删除文件 FileDelete(CString strName)
From:http://blog.csdn.net/lvwx369/article/details/41440883 注意:其中namePath 为全局变量 Cstring namePath; BOO ...