struts2、hibernate的知识点
以下内容是我在复习struts2、hibernate和spring的时候记下得到,部分书上找不到的内容来自网络
以下是网络部分的原文网站:
http://blog.csdn.net/frankaqi/article/details/51873557
http://blog.sina.com.cn/s/blog_75115c8d0102vy1i.html
http://www.cnblogs.com/xiohao/p/3561175.html
http://www.cnblogs.com/oumyye/p/4356149.html
https://yq.aliyun.com/articles/18651
http://www.cnblogs.com/tengpan-cn/p/5970796.html
http://blog.csdn.net/chenleixing/article/details/44572637
http://blog.csdn.net/wild_elegance_k/article/details/47683725
http://www.cnblogs.com/joyang/p/4973435.html
http://blog.csdn.net/firejuly/article/details/8190229
http://blog.csdn.net/ljl18566743868/article/details/52130583
http://www.cnblogs.com/langtianya/p/4628967.html
Struts2
1:Struts2与Struts1的联系
struts1与struts2都是mvc框架的经典实现模式。
Struts2是Struts1和Webwork结合的产物,但却是以WebWork的设计思想为核心,采用拦截器的机制来处理用户的请求,所以Struts 2可以理解为WebWork的更新产品
2:Struts2与Struts1的区别
1:因为Stuts2是针对拦截器开发的,也就是所谓的AOP思想,可以配置多个action,用起来比较方便,依赖性也更弱一点
2:因为请求之前的拦截器有一些注入的操作,速度相对Stuts1来说慢一点。
3:Struts1是使用ActionServlet做为其中心处理器,Struts2则使用一个拦截器(FilterDispatcher)做为其中心处理器,这样做的一个好处就是将Action类和Servlet API进行了分离。Struts1的Action类依赖于Servlet API,Struts2则不依赖于Servlet API
4:Struts1的Action类是单例模式,必须设计成线程安全的,Struts2则为每一个请求产生一个实例
5:因为Struts1依赖于Servlet API这些Web元素,因此对Struts1的Action进行测试的时候是很困难的,需要借助于其他的测试工具,Struts2的Action可以像测试其他的一些Model层的Service类一样进行测试
6:Struts1的Action与View通过ActionForm或者其子类进行数据传递,struts2可以通过POJO(Plain Ordinary Java Object 简单的Java对象)进行数据传递
7:Struts1绑定了JSTL,为页面的编写带来方便,Struts2整合了OGNL,也可以使用JSTL,因此,Struts2下的表达式语言更加强大
3:Struts2的简单处理流程
1:客户端产生一个HttpServletRequest的请求
2:客户端产生的请求被提交到一系列的标准过滤器(Filter)组建链中
3:核心控制器组建FilterDispatcher被调用,并询问ActionMapper来决定这个请求是否需要调用某个Action
4:ActionMapper决定要调用那一个Action,FilterDispatcher把请求交给ActionProxy。
5:ActionProxy通过Configurate Manager询问Struts配置文件,找到要调用的Action类
6: ActionProxy创建一个ActionInvocation实例
7: ActionInvocation实例使用命令模式来调用,回调Action的exeute方法
8: 一旦Action执行完毕,ActionInvocation负责根据Struts.xml的配置返回结果。
4:Struts2如何进行校验
A:编程校验
1:针对所有方法:继承ActionSupport,重写validate方法。
2:针对某个方法进行效验:validateXxx方法。
B:校验框架
每个Action类有一个校验文件,命名为 Action类名-validation.xml,且与Action类同目录,这是对action里面所有的方法进行校验。
对Action里面的指定方法做校验使用Action的类名-访问路径_方法名-validation.xml。
5:什么是OGNL,有什么用途?
OGNL的全程是(Object-Graph Navigation Language 对象图导航语言)
它是一种功能强大的开源表达式语言,使用这种表达式语言,可以通过某种表达式语法,存取java对象的任意属性,调用java对象的方法,同时能够自动实现必要的类型转换
struts2默认的表达式语言就是OGNL,它具有以下特点:
1:支持对象方法调用:对象名.方法名
2:支持类静态方法调用和值访问:@包括路径的类全名@方法名(参数)
3:支持赋值操作和表达式串联
6:模型驱动与属性驱动是什么
模型驱动与属性驱动都是用来封装数据的。
A:模型驱动:模型驱动指通过JavaBean模型进行数据传递
在实现类中实现ModelDriven<T>接口使用泛型把属性类封装起来,重写getModel()方法,然后在实现类里创建一个属性类的实例。
B:属性驱动:属性驱动是指通过字段进行数据传递
属性驱动分为
1):基本数据类型字段驱动方式的数据传递
直接在action里面定义各种java基本 数据类型的字段
2):直接使用域对象字段驱动方式的数据传递
就方法A而言,当需要传入的数据过于庞大的时候,会使action非常臃肿,不够简洁所以需要使用方法B(这也是我常用的方法)。将属性和响应的get/set方法提取出来单独作为一个域对象封装起来,在action里面直接使用域对象
7:dispatcher和redirect
dispatcher结果类型是将请求转发到jsp视图资源 ---->请求转发(是struts2的默认结果类型)
redirect类型是将请求重定向到jsp视图资源或者重定向到action---->重定向 (重定向请求,将丢失所有参数,包括action的处理结果)
<action>
<result type="redirect"></result>
<result type="dispatcher"></result>
</action>
8:Struts2中result type的类型有哪些
1:dispatcher : 默认的类型,相当于servlet的foward,服务器端跳转。客户端看到的是struts2中配置的地址,而不是真正页面的地址。一般用于跳转到jsp页面
2:redirect、redirect-action : 页面重定向,客户端跳转;前者用于跳转到jsp页面,后者用于跳转到action
3:chain : 将请求转发到一个action
4:stream : 一般用于下载文件用
5:PlainText : 普通文本
6:Velocity(Velocity) : 用于与Velocity技术的集成
7:XSLT(xslt) : 用于与XML/XSLT技术的集成
8:HttpHeader : 返回报文头给用户
9:json
9:Struts2中的拦截器有什么用?
拦截器是struts2的核心组成部分,拦截器提供了一种机制,使得开发者可以定义一个特定的功能模块,这个模块会在action执行之前或者之后执行用于对数据进行处理,也可以在action执行之前阻止action执行。同时拦截器也可以让你将通用代码模块作为一个可重用的类。拦截器是AOP(面向切面编程)的一种实现策略
10:列举框架提供的拦截器名称
1:conversation:这是一个处理类型转换错误的拦截器,它负责将类型转换错误从ActionContext中取出,并转换成Action的FieldError错误。
2:Exception:这个拦截器负责处理异常,它将异常映射成结果。
3:fileUpload:这个拦截器主要用于文件上传,它负责解析表单中文件域的内容。
4:i18n:这是支持国际化的拦截器,它负责把所选的语言、区域放入用户Session中。
5:params:这是最基本的一个拦截器,它负责解析HTTP请求中的参数,并将参数值设置成Action对应的属性值。
6:scope:这是范围转换拦截器,它可以将Action状态信息保存到HttpSession范围,或者保存到ServletContext范围内。
7:token:这个拦截器主要用于阻止重复提交,它检查传到Action中的token,从而防止多次提交。
只要我们定义的包继承了struts-default包,就可以直接使用这些拦截器。
11:struts2常用标签

12:struts2上传文件
1:创建web项目并导入相应包
2:修改web.xml文件里面的配置
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_9" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<!-- 指定struts2的核心过滤器 -->
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
3:在WebRoot目录下面创建upload文件夹
4:创建上传文件对应test.ServletTest
package test; import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream; import javax.imageio.stream.FileImageInputStream; import org.apache.struts2.ServletActionContext; import com.opensymphony.xwork2.ActionSupport; public class ServletTest extends ActionSupport{
private static final long seriaVersionUID=1L;
private File picture;//提交过来的文件
private String pictureFileName;//提交的文件名
private String pictureContentType;//提交的文件类型
private String mess;
public File getPicture() {
return picture;
}
public void setPicture(File picture) {
this.picture = picture;
}
public String getPictureFileName() {
return pictureFileName;
}
public void setPictureFileName(String pictureFileName) {
this.pictureFileName = pictureFileName;
}
public String getPictureContentType() {
return pictureContentType;
}
public void setPictureContentType(String pictureContentType) {
this.pictureContentType = pictureContentType;
}
public String getMess() {
return mess;
}
public void setMess(String mess) {
this.mess = mess;
}
public String execute() throws IOException{
System.out.println("提交过来的文件: "+picture);
System.out.println("提交的文件名: "+pictureFileName);
System.out.println("提交的文件类型: "+pictureContentType);
//判断是否有提交的文件
if(picture==null){
mess="请上传图片!!";
return "wrong";
}
//文件输出流
InputStream is = new FileInputStream(picture);
//设置文件保存目录
String uploadPath=ServletActionContext.getServletContext().getRealPath("\\upload");
//设置目标文件
File toFile = new File(uploadPath,this.getPictureFileName());
//文件输出流
OutputStream os = new FileOutputStream(toFile);
byte[]buffer = new byte[1024];
int length=0;
//读取file文件到tofile文件中
while (-1 != (length = is.read(buffer))) {
os.write(buffer, 0, length);
}
is.close();
os.close();
return "success";
}
}
5:创建对应的struts.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="default" extends="struts-default">
<action name="upload" class="test.ServletTest" method="execute">
<result name="success">/success.jsp</result>
<result name="wrong">/index.jsp</result>
</action>
</package>
</struts>
6:创建对应的success.jsp和index.jsp
index.jsp
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>
<%@taglib prefix="s" uri="/struts-tags" %>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>"> <title>主页面</title>
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
<!--
<link rel="stylesheet" type="text/css" href="styles.css">
-->
</head> <body>
${mess }
<s:form action="upload" method="post" enctype="multipart/form-data" >
<s:file name="picture" label="上传图片" />
<s:submit value="上传"/>
<s:reset value="重置" />
</s:form>
</body>
</html>
success.jsp
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>"> <title>成功页面</title> <meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
<!--
<link rel="stylesheet" type="text/css" href="styles.css">
--> </head> <body>
<h1>文件上传成功</h1><hr/>
<p>上传文件名:${pictureFileName}</p>
<p>文件上传类型:${pictureContentType}</p>
<img src="upload/${pictureFileName}" />
</body>
</html>
13:自定义一个拦截器
1:创建一个简单的struts2项目。可以参照http://www.cnblogs.com/minuobaci/p/7536229.html
2:删除src目录下面的包,在src目录下面创建一个com.gx.entity.User
package com.gx.entity;
public class User {
private String username;
private String password;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
3:在src目录下面创建一个com.gx.action.LoginAction
package com.gx.action; import com.gx.entity.User;
import com.opensymphony.xwork2.ActionContext; public class LoginAction {
private User user;
private String mess;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public String getMess() {
return mess;
}
public void setMess(String mess) {
this.mess = mess;
}
public String login(){
System.out.println("login is working......");
ActionContext actionContext = ActionContext.getContext();
if(user.getUsername().equals("admin")&&user.getPassword().equals("123")){
//将用户存储在session里面
actionContext.getSession().put("user", user);
return "success";
}else{
mess = "登录失败!!";
return "wrong";
}
}
}
4:在src目录下面创建一个com.gx.action.BookAction
package com.gx.action;
public class BookAction {
private String mess;
public String getMess() {
return mess;
}
public void setMess(String mess) {
this.mess = mess;
}
public String add(){
System.out.println("add is working......");
mess = "添加成功";
return "success";
}
public String delete(){
System.out.println("delete is working......");
mess = "删除成功";
return "success";
}
public String find(){
System.out.println("find is working......");
mess = "查找成功";
return "success";
}
public String update(){
System.out.println("update is working......");
mess = "修改成功";
return "success";
}
}
5:创建拦截器com.gx.intercepter.LoginIntercepter
package com.gx.intercepter; import com.opensymphony.xwork2.ActionContext;
import com.opensymphony.xwork2.ActionInvocation;
import com.opensymphony.xwork2.interceptor.AbstractInterceptor; public class LoginIntercepter extends AbstractInterceptor{
public String intercept(ActionInvocation invocation) throws Exception{
System.out.println("LoginIntercepter is working......");
ActionContext actionContext = invocation.getInvocationContext();
Object user = actionContext.getSession().get("user");
if(user!=null){
//继续向下执行
return invocation.invoke();
}else{
actionContext.put("msg", "你还没有登录");
return "wrong";
}
}
}
6:在WebRoot下面创建main.jsp页面
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>"> <title>main page</title> <meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
<!--
<link rel="stylesheet" type="text/css" href="styles.css">
--> </head> <body>
<!-- 这里的struts2_test是我的项目名 -->
<a href="/struts2_test/book_add">增加</a>
<a href="/struts2_test/book_delete">删除</a>
<a href="/struts2_test/book_find">查找</a>
<a href="/struts2_test/book_update">修改</a>
</body>
</html>
7:修改index.jsp里面<body>的代码如下
${requestScope.msg}
<form action="login" method="post">
请输入用户名:<input type="text" name="user.username"><br/>
请输入用户密码:<input type="password" name="user.password"><br/><br/>
<input type="submit" value="提交"/>
</form>
8:在struts.xml里面声明拦截器
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="default" extends="struts-default">
<!-- 声明拦截器 -->
<interceptors>
<interceptor name="checkLogin" class="com.gx.intercepter.LoginIntercepter" />
<interceptor-stack name="myStack">
<interceptor-ref name="defaultStack" />
<interceptor-ref name="checkLogin" />
</interceptor-stack>
</interceptors>
<!-- 用户登录 -->
<action name="login" class="com.gx.action.LoginAction" method="login">
<result name="success">/main.jsp</result>
<result name="wrong">/wrong.jsp</result>
</action>
<!-- book操作 -->
<action name="book_*" class="com.gx.action.BookAction" method="{1}">
<!-- 此处的name与test.ServletTest.java里面的方法返回值相对应 -->
<result name="success">/success.jsp</result>
<!-- 使用自定义拦截器 -->
<interceptor-ref name="myStack" />
<result name="wrong">/index.jsp</result>
</action>
</package>
</struts>
9:在网页上输入网址:http://localhost:8080/struts2_test/main.jsp
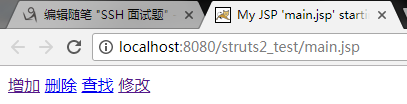
10:随便点击一个超链接,在这里我选择修改
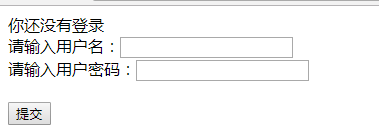
11:可以看到,被拦截器拦截到了,转到了请求登录页面
输入用户名:admin和密码:123点击登录
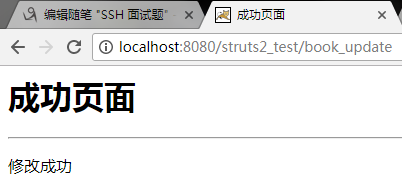
13:点击修改
14:拦截器和过滤器的区别联系
过滤器,可以在用户传入的request,response进入servlet或者struts的action进行业务逻辑处理之前过滤掉一些信息,或者提前设置一些参数。比如过滤掉非法url(不是login.do的地址请求,如果用户没有登录都过滤掉),或者在传入servlet或者struts的action前统一设置字符集,或者去除掉一些非法字符
拦截器是struts2的核心组成部分,拦截器提供了一种机制,使得开发者可以定义一个特定的功能模块,这个模块会在action执行之前或者之后执行用于对数据进行处理,也可以在action执行之前阻止action执行。同时拦截器也可以让你将通用代码模块作为一个可重用的类。拦截器是AOP(面向切面编程)的一种实现策略
两者之间的区别
1:拦截器是基于java的反射机制的,而过滤器是基于函数回调。
2:拦截器不依赖于servlet容器,过滤器依赖与servlet容器。
3:拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
4:拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问
5:在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次
15:struts2的优缺点
优点
1:实现了MVC模式,层次结构清晰,减少了代码的维护量,方便了我们对Action进行的测试,使程序员只需关注业务逻辑的实现,HTML前端程序员可以集中精力于表现层的开发,有利于缩短产品的开发时间。
2: 丰富的标签库,大大提高了开发的效率。
3:通过配置文件,就可以掌握整个系统各个部分之间的关系。降低模块间耦合度
4:强大的核心拦截器机制,struts2中的拦截器是Action级别的AOP,通过拦截器,可以很方便让我们对业务进行扩展
缺点
安全性有待提高。Struts2曝出2个高危安全漏洞,一个是使用缩写的导航参数前缀时的远程代码执行漏洞,另一个是使用缩写的重定向参数前缀时的开放式重定向漏洞。
hibernate
1:hibernate的持久化对象状态三种状态
hibernate是持久层的ORM映射框架,专注于数据的持久化工作。
所谓的持久化就是将内存中的数据永久存储到关系型数据库中。
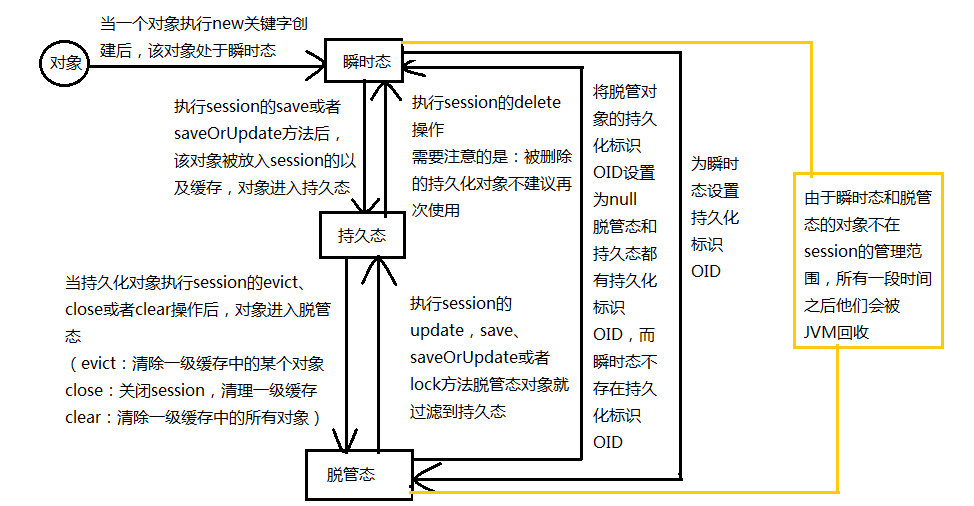
持久化的三种状态:
瞬时态:也称临时态或者自由态,瞬时态的实例是由new命令创建、开辟内存空间的对象,没有与hibernate session关联,在数据库中也没有记录,失去引用后将被JVM回收
持久态:加入到session缓存中,并且相关联的session没有关闭,在数据库里面有对应的记录,每条记录只对应唯一的持久化对象,需要注意的是,持久态对象是在事务尚未提交前变成持久态的
脱管态:也称离线态或者游离态,当持久态的实例与session的关联被关闭的时候就成了脱管态。与数据库里面的数据存在关联,只是失去了与当前session的关联,脱管态改变的时候hibernate不能检测到
2:hibernate持久化状态之间的转化
3:hibernate的一级缓存
hibernate的一级缓存为hibernate的内置缓存,不能被卸载
*** 什么是hibernate的一级缓存? ***
hibernate的一级缓存就是指session缓存,session缓存是一块内存空间,用来存放相互管理的java对象,在使用hibernate查询对象的时候,首先会使用对象属性的OID值在hibernate的一级缓存中进行查找,如果找到匹配的OID值的对象就会直接将该对象从一级缓存中取出使用,不会再去查询数据库,如果,没有找到就回去数据库查找。当从数据库中查询到所需数据的时候,该数据信息也会放置到一级缓存中。
hibernate一级缓存的作用就是减少对数据库的访问次数。
4:hibernate一级缓存的特点
1:当应用程序调用session接口的save、update、saveOrUpdate方法的时候,如果session缓存中没有相应的对象,hibernate会自动把从数据库中查询到的相应对象的信息加入到一级缓存里
2:当调用session接口的load、get方法以及query接口的list、Iterator方法的时候,会判断缓存中是否存在该对象,有则返回,不会查询数据库,如果没有,就会去数据库中查找对应对象,并将其添加到一级缓存里面
3:调用session的close方法的时候session缓存会被清空
4:session能够在某些时间点按照缓存对象的变化执行相关的SQL语句来同步更新数据库,这一过程被称为刷出缓存(flush)
5:hibernate的session接口的load方法与get方法有什么区别
1:当数据库不存在对应ID数据时,调用load()方法将会抛出ObjectNotFoundException异常,get()方法将返回null
2:当对象.hbm.xml配置文件<class>元素的lazy属性设置为true时(延迟加载),调用load()方法时则返回持久对象的代理类实例,此时的代理类实例是由运行时动态生成的类,该代理类实例包括原目标对象的所有属性和方法,该代理类实例的属性除了ID不为null外,所在属性为null值,查看日志并没有Hibernate SQL输出,说明没有执行查询操作,当代理类实例通过getXXX()方法获取属性值时,Hiberante才真正执行数据库查询操作。当对象.hbm.xml配置文件<class>元素的lazy属性设置为false时,调用load()方法则是立即执行数据库并直接返回实体类,并不返回代理类。而调用get()方法时不管lazy为何值,都直接返回实体类。
*** 联系 ***
load()和get()都会先从Session缓存中查找,如果没有找到对应的对象,则查询Hibernate二级缓存,再找不到该对象,则发送一条SQL语句查询。
6:默认情况下session刷出缓存的时间点
1:当应用程序调用transaction的commit方法的时候,该方法先刷出缓存(session.flush()),然后再向数据库提交事务(tx.commit())
2:当应用程序执行一些查询操作的时候,如果缓存中持久化对象的属性已经发生了变化,会先刷出缓存,以保证查询结果能够反映持久化对象的最新状态
3:调用session的flush()方法
7:hibernate二级缓存
*** hibernate提供两个级别的缓存 ***
第一级缓存是session级别的缓存,属于事务范围的缓存,由hibernate管理,一般情况下无需干预
第二级缓存是一个可插拔的缓存插件,是由sessionFactory负责管理的
当执行某个查询获得的结果集是实体对象的时候,hibernate就会把获得的实体对象按照ID加载到二级缓存中。在访问指定的对象的时候,首先从一级缓存中查找,找到了就直接使用,找不到就转到二级缓存中查找(在配置和启动二级缓存的情况下)。如果找到就直接使用,否则查询数据库,并将找到的结果放到一级缓存和二级缓存中
*** sessionFactory的缓存可以分为两类 ***
1:内置缓存:hibernate自带的不可以卸载。在hibernate的初始化阶段将映射元数据(映射文件中数据的复制)和预定义的SQL语句(hibernate根据映射元数据推导出来的)放到sessionFactory的缓存中。该内置缓存是只读的
2:外置缓存(二级缓存):一个可配置的缓存插件,默认情况下,sessionFactory不会启用这个缓存插件,外置缓存中的数据是数据库数据的复制,外置缓存的物理介质可以是内存或者硬盘
*** 二级缓存可以分成4类 ***
1:类级别的缓存:主要用于存储实体对象
2:集合级别的缓存:用于存储几何数据
3:查询缓存:缓存一些常用查询语句和查询结果
4:更新时间戳:该区域放了与查询结果相关的表在进行插入,更新或者删除操作的时间戳,hibernate通过更新时间戳来判断被缓存的查询结果是否过期
*** 二级缓存的并发事务隔离级别 ***
只读型:用于重来不会被修改的数据
读写型:用于常读但是很少被修改的数据,防止脏读
非严格读写:不保证缓存与数据库一致性,用于极少被修改且允许脏读的数据
事务型:对于常读但很少修改的数据,可以防止脏读和不可重复读
8:关联关系映射
1:一对多
class one{
private set<more> more;
}
class more{
private one one;
}
配置文件
one.hbm.xml(放在<class>里面的<property>下面)
<!-- 这里的more是one.java里面的属性名 -->
<set name="more">
<!-- 确定数据库里面的关联外键,one_id是外键的名称 -->
<key column = "one_id" />
<!-- 映射到关联类属性 -->
<one-to-many class="com.gx.more" />
</set>
more.hbm.xml(放在<class>里面的<property>下面)
<!-- 设置多对一关系映射 -->
<!-- 这里的one是more.java里面的属性名 -->
<many-to-one name="one" class="com.gx.one" column="one_id"/>
2:多对多
class A{
private set<B> b
}
class B{
private set<A> a;
}
配置文件
A.hbm.xml
<set name="b" table="a_b">
<key column="a_id" />
<many-to-many class="com.gx.B" column="b_id" />
</set>
B.hbm.xml
<set name="a" table="a_b">
<key column="b_id" />
<many-to-many class="com.gx.A" column="a_id" />
</set>
9:反转操作
反转操作在映射文件里面通过对集合的inverse属性的设置,来控制关联关系和对象的级联关系
inverse的默认属性使false,也就是说关系的两端都能控制。这就会造成更新等操作的时候出现重复更新,会报错。一般来说,如果是一对多的关系,会将一的一方的inverse的值设置为true,即通过一方来维护关联关系,这样就不会产生多余的SQL语句,如果是多对多,设置其中的一方就可以了
10:级联操作
级联操作是指当主控方执行保存、更新或者删除操作的时候,其关联对象也执行相同的操作
在映射文件里面通过对cascade属性的设置来控制是否对关联对象采用级联操作
cascade属性的设置
1:save-update:在执行save、update或saveOrUpdate的时候进行关联操作
2:delete:在执行delete操作的时候进行关联操作
3:delete-orphan:表示孤儿删除,即删除所有和当前对象解除关联关系的对象
4:all:表示所有情况下均进行关联操作,但是不包括delete-orphan操作
5:all-delete-orphan:所有情况下均进行关联操作,包括delete-orphan操作
6:none:任何情况下都不进行关联操作
11:hibernate的检索方式

12:HQL
HQL(面向对象的查询语言)和SQL查询语言有点相似,但是HQL使用的是类、对象和属性的概念,没有表和字段的概念
HQL检索方式具有以下功能:
1:在查询语句中设定各种查询条件
2:支持投影查询,即仅仅检索出对象的部分属性
有些时候只需要查询部分属性,并不需要查询一个类的所有属性。如果在这种情况下查询出所有的属性使非常影响查询性能的,为此提供了投影查询。使用投影查询查找到的集合里面的每一个元素都是一个Object数组而不是一个对象
3:支持分页查询
4:支持分组查询,允许使用group by和having关键字
5:提供内置聚集函数,如sum、min、max
6: 支持子查询,即嵌套查询
7:支持动态绑定参数
13:事务的特点:
1:原子性(Atomicity):事务中所有的操作被捆绑成一个不可分割的单元,即对事物所进行的数据修改等操作,要么全部执行成功,要么全部执行失败
2:一致性(Consistency):表示事务完成的时候,必须使所有的数据都保持一致
3:隔离性(Isolation):指一个事务的执行不能被其他事务干扰,即一个事物内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰
4:持久性(Durability):也称为永久性,指一个事务一旦提交,他对数据库中数据的改变就是永久的,提交后的其他操作或者故障不会对其有任何影响
14:事务并发问题
1:脏读:一个事务读取另一个事务未提交的数据
2:不可重复读:一个事务对同一行数据重复读取两次,却得到不一样的结果
3:虚读/幻读:事务A在操作过程中进行两次查询,第二次得到了第一次没有出现过的数据。因为两次查询的过程中另一个事务B插入了新的数据
4:更新丢失:两个事务更新同一条数据,后提交(或者撤销)的事务将前面的事务提交的数据覆盖
第一类丢失更新:两个事务同时操作同一个数据的时候,A事务撤销时,把已经提交的B事务的更新数据覆盖,对B事务来说造成了数据的丢失
第二类丢失更新:两个事务同时操作同哟个数据时,事务A将修改结果成功提交后,对事务B已经提交了的修改结果进行了覆盖,对事物B造成了数据丢失
15:事务隔离级别
为了避免并发事务问题出现,在标准SQL规范里面定义了4个事务隔离级别
1:读未提交(1级):一个事务在执行过程中,既可以访问其他事务未提交的新插入的数据,又可以访问未提交的修改数据。如果一个事务已经开始写数据,则另一个事务不允许同时进行写操作,但允许其他事务读取此行数据。可以防止丢失数据
2:读已提交(2级):一个事务在执行过程中,既可以访问其他事务成功提交的新插入的数据,又可以访问成功修改的数据。读取数据的事务允许其他事务继续访问该行数据,但未提交的写事务将会禁止其他事务访问该行。可以避免脏读
3:可重复读取(4级):一个事务在执行过程中,可以访问其他事务成功提交的新插入的数据,但不可以访问成功修改的数据。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。防止不可重复读和脏读
4:序列化(8级):提供严格的事务隔离。它要求事务序列化执行,事务只能一个接一个的执行,不能并发执行。可以防止脏读、不可重复读和幻读
16:操作管理事务的方法
1:通过代码来操作管理事务
//开启事务
Transaction tx = session.beginTransaction();
…… //提交事务
tx.commit
//回滚事务
tx.rollback
2:通过hibernate的配置文件(hibernate.cfg.xml里面的<session-factory>里面写下面的配置)对事务进行配置
<!-- 使用本地事务 -->
<property name="hibernate.current_session_context_class" >
thread
</property>
<!-- 使用全局事务 -->
<property name="hibernate.current_session_context_class">jta</property>
<!-- 设置事务隔离级别 -->
<property name="hibernate.connection.isolation">4</property>
本地事务和全局事务是hibernate对事物处理从两种方法:
本地事务指针对一个数据库的操作,即只针对一个事务性资源进行操作。
全局事务是由应用服务器进行管理的事务,他需要使用JTA,并且可以用于多个事务性资源(跨多个数据库)
由于JTA的API非常笨重,并且通常只在服务器的环境下使用,因此全局事务的使用限制了应用代码的重用性,通常情况下对于hibernate的事务管理都是选择本地事务
17:悲观锁,乐观锁
当多个事务访问数据库里面相同的数据的时候,如果没有采取必要的隔离措施,将会导致各种事务并发问题,可以采用悲观锁或者乐观锁对其进行控制
悲观锁:每次操作数据的时候,总是悲观的认为会有其他的事务来操作相同的数据,因此,在整个数据处理过程中,将会把数据处于锁定状态,悲观锁具有排他性,一般由数据库来实现,在锁定时间内,其他事务不能对数据进行存取等操作,这样可能导致长时间的等待问题。
乐观锁:乐观锁通常认为许多事务同时操作一个数据的情况很少,所以乐观锁不会做数据库层次的锁定,而是基于数据版本表示实现应用程序级别上的锁定机制。(数据版本标识是指通过为数据表增加一个“version”字段,实现在读取数据的时候,将版本号一起读出,之后更新次数据的时候,将版本号加一,提交数据的时候,如果提交数据的版本号大于数据库版本号则允许跟新否则禁止)
hibernate和mybatis的对比
1:Mybatis框架相对简单很容易上手,但也相对简陋些。
2:Hibernate 与Mybatis都是流行的持久层开发框架,但Hibernate开发社区相对多热闹些,支持的工具也多,更新也快。而Mybatis相对平静,工具较少。
3:针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程。
4:Hibernate具有自己的日志统计。但Mybatis本身不带日志统计,需要使用Log4j进行日志记录。
5:Hibernate与具体数据库的关联只需在XML文件中配置即可,所有的HQL语句与具体使用的数据库无关,移植性很好。MyBatis项目中所有的SQL语句都是依赖所用的数据库的,所以不同数据库类型的支持不好
6:hibernate的开发者不必考虑 SQL 语句的执行。这部分细节已经由 Hibernate 掌管妥当,只有开发者在进行系统性能调优的时候才需要进行了解。而MyBatis在这一块没有文档说明,用户需要对对象自己进行详细的管理。
7:因为Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。
而MyBatis在这一方面,使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免Cache的盲目使用。否则,脏数据的出现会给系统的正常运行带来很大的隐患。
*** mybatis优势 ***
MyBatis可以进行更为细致的SQL优化,可以减少查询字段
MyBatis容易掌握,而Hibernate门槛较高。
*** hibernate优势 ***
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳
最核心的一点,mybatis和hibernate的思想不一样,mybatis是面向数据库的,hibernate是面向对象的,所以hibernate的包装非常好,甚至对于简单的SQL我们都不需要书写代码,可以直接继承HibernateDaoSupport类就可以直接使用不需要写SQL了
面临的问题,hibernate包装的太好,以至于优化SQL的时候不太方便,排错也不太方便
mybatis
1:简介
ORM的全称是Object/Relation Mapping即对象/关系数据库映射。可以将ORM理解为一种规范,他概述了这类框架的基本特征,完成面向对象的编程语言到关系数据库的映射。当ORM框架完成映射之后,程序员既可以利用面向对象程序设计语言的简单易用性,又可以利用关系数据库的技术优势,因此可以把ORM当成是应用程序和数据库的桥梁
确切的说,mybatis并不是一种ORM框架,他的设计思想和ORM相似,只是他允许开发人员直接编写SQL语句,访问更加灵活,更确切,他应该是一种“SQL Mapping”框架
2:创建一个mybatis项目,实现根据ID查询用户,并测试
1:创建实体类com.gx.mybatis.entity.User
package com.gx.mybatis.entity;
public class User {
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", age=" + age + "]";
}
}
2:创建com.gx.mybatis.dao.UserMapper接口
package com.gx.mybatis.dao;
import com.gx.mybatis.entity.User;
public interface UserMapper {
/**
* 根据ID查询用户
* @param id
* @return
*/
public User selectUserById(int id);
}
3:在com.gx.mybatis.dao目录下创建实现selectUserById方法的配置文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 此处的名称与DAO对应 -->
<mapper namespace="com.gx.mybatis.dao.UserMapper">
<!--ID要与接口中的方法名相同 parameterType传入的参数类型 resultType 返回的类型这里也User类的全路径-->
<select id="selectUserById" parameterType="int" resultType="com.gx.mybatis.entity.User">
select * from user where id=#{id}
</select>
</mapper>
#{}是sql的参数占位符,Mybatis会将sql中的#{}替换为?号,在sql执行前会使用PreparedStatement的参数设置方法,按序给sql的?号占位符设置参数值,比如ps.setInt(0, parameterValue)。
4:创建文件夹config
5:configuration.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--配置 -->
<configuration>
<!-- 加载资源文件 -->
<properties resource="db.properties"/>
<!--配置环境 -->
<environments default="development">
<environment id="development">
<!--事务管理 -->
<transactionManager type="JDBC"/>
<!--数据源 通过Properties加载配置 -->
<dataSource type="POOLED">
<!--驱动driver -->
<property name="driver" value="${driver}"/>
<!--连接URL -->
<property name="url" value="${url}"/>
<!--用户名 -->
<property name="username" value="${username}"/>
<!--密码 -->
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!--建立映射 -->
<mappers>
<mapper resource="com/gx/mybatis/dao/UserMapper.xml"/>
</mappers>
</configuration>
${}是Properties文件中的变量占位符,它可以用于标签属性值和sql内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver
6:db.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3307/test?characterEncoding=utf8
username=root
password=root
7:创建测试类com.gx.mybatis.test.TestMyBatis1
package com.gx.mybatis.test; import java.io.IOException;
import java.io.Reader; import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test; import com.gx.mybatis.dao.UserMapper;
import com.gx.mybatis.entity.User; public class TestMyBatis1 {
//Session工厂
static SqlSessionFactory sqlSessionFactory=null;
//Session
static SqlSession session=null;
//字符流
static Reader reader=null;
public static void main(String[] args) {
//加载配置文件
try {
reader=Resources.getResourceAsReader("configuration.xml");
//建立SqlSessionFactory
sqlSessionFactory=new SqlSessionFactoryBuilder().build(reader);
//打开Session
session=sqlSessionFactory.openSession();
//获取用户接口对象
UserMapper userMapper=session.getMapper(UserMapper.class);
//调用查询方法
User user=userMapper.selectUserById(1);
System.out.println(user.toString());
} catch (IOException e) {
e.printStackTrace();
}
} }
8:运行测试类,测试结果为

3:使用别名
1:修改UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 此处的名称与DAO对应 -->
<mapper namespace="com.gx.mybatis.dao.UserMapper"> <!--结果映射 不区别大小写,建议数据库的列写为大写 -->
<resultMap type="User" id="userMap">
<!--主键 -->
<id property="id" column="ID"/>
<!--姓名 -->
<id property="name" column="NAME"/>
<!--年龄 -->
<id property="age" column="AGE"/>
</resultMap> <!--修改前resultType返回的类型是User类的全路径 ,这里resultType里面的是别名-->
<select id="selectUserById" parameterType="int" resultType="User">
select * from user where id=#{id}
</select> </mapper>
2:修改configuration.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--配置 -->
<configuration>
<!-- 加载资源文件 -->
<properties resource="db.properties"/>
<!--使用别名 -->
<typeAliases>
<!--用户类别名 -->
<typeAlias type="com.gx.mybatis.entity.User" alias="User"/>
</typeAliases>
<!--配置环境 -->
<environments default="development">
<environment id="development">
<!--事务管理 -->
<transactionManager type="JDBC"/>
<!--数据源 通过Properties加载配置 -->
<dataSource type="POOLED">
<!--驱动driver -->
<property name="driver" value="${driver}"/>
<!--连接URL -->
<property name="url" value="${url}"/>
<!--用户名 -->
<property name="username" value="${username}"/>
<!--密码 -->
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!--建立映射 -->
<mappers>
<mapper resource="com/gx/mybatis/dao/UserMapper.xml"/>
</mappers>
</configuration>
3:创建测试类TestMybatis2
package com.gx.mybatis.test; import java.io.IOException;
import java.io.Reader; import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder; import com.gx.mybatis.dao.UserMapper;
import com.gx.mybatis.entity.User; public class TestMyBatis2 {
//Session工厂
static SqlSessionFactory sqlSessionFactory=null;
//Session
static SqlSession session=null;
//字符流
static Reader reader=null;
public static void main(String[] args) {
//加载配置文件
try {
reader=Resources.getResourceAsReader("configuration.xml");
//建立SqlSessionFactory
sqlSessionFactory=new SqlSessionFactoryBuilder().build(reader);
//打开Session
session=sqlSessionFactory.openSession();
//获取用户接口对象
UserMapper userMapper=session.getMapper(UserMapper.class);
//调用查询方法
User user=userMapper.selectUserById(2);
System.out.println(user.toString());
} catch (IOException e) {
e.printStackTrace();
}
} }
4:测试结果
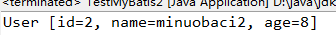
4:在使用别名的情况下添加其他方法
1:修改UserMapper
package com.gx.mybatis.dao;
import java.util.List;
import com.gx.mybatis.entity.User;
public interface UserMapper {
//增加
public void addUser(User user);
//删除
public void deleteUser(int id);
//查询
public User selectUserById(int id);
public List<User> selectUserLikeName(String name);
public List<User> selectAll();
//修改
public void updateUser(User user);
}
2:修改UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 此处的名称与DAO对应 -->
<mapper namespace="com.gx.mybatis.dao.UserMapper">
<!--结果映射 不区另大小写,建议数据库的列写为大写 -->
<resultMap type="User" id="userMap">
<!--主键 -->
<id property="id" column="ID"/>
<!--姓名 -->
<id property="name" column="NAME"/>
<!--年龄 -->
<id property="age" column="AGE"/>
</resultMap>
<!--resultType里面的是别名-->
<!-- 增加 -->
<insert id="addUser" parameterType="User" useGeneratedKeys="true" keyProperty="id">
insert into user(name,age)values(#{name},#{age})
</insert>
<!-- 删除 -->
<delete id="deleteUser" parameterType="int">
delete from user where id=#{id}
</delete>
<!-- 查询 -->
<select id="selectUserById" parameterType="int" resultType="User">
select * from user where id=#{id}
</select>
<select id="selectUserLikeName" parameterType="String" resultMap="userMap">
select * from user where name like "%"#{name}"%"
</select>
<select id="selectAll" resultMap="userMap">
select * from user
</select>
<!-- 修改 -->
<update id="updateUser" parameterType="User">
update user set name=#{name},age=#{age} where id=#{id}
</update>
</mapper>
3:创建测试类TestMybatis3
package com.gx.mybatis.test; import java.io.IOException;
import java.io.Reader;
import java.util.List; import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder; import com.gx.mybatis.dao.UserMapper;
import com.gx.mybatis.entity.User; public class TestMyBatis3 {
//Session工厂
static SqlSessionFactory sqlSessionFactory=null;
//Session
static SqlSession session=null;
//字符流
static Reader reader=null;
public static void main(String[] args) {
//加载配置文件
try {
reader=Resources.getResourceAsReader("configuration.xml");
//建立SqlSessionFactory
sqlSessionFactory=new SqlSessionFactoryBuilder().build(reader);
//打开Session
session=sqlSessionFactory.openSession();
//获取用户接口对象
UserMapper userMapper=session.getMapper(UserMapper.class);
//调用添加方法
User user1 = new User();
user1.setAge(12);
user1.setName("lili");
userMapper.addUser(user1);
//使用查询姓名方法
List<User> lists1 = userMapper.selectUserLikeName("lili");
System.out.println("使用查询姓名方法:");
for(User u : lists1){
System.out.println(u.toString());
}
//使用查询ID方法
User user2 = userMapper.selectUserById(1);
System.out.println("使用查询ID方法: "+user2.toString());
//使用修改方法
user2.setName("mary");
userMapper.updateUser(user2);
System.out.println("使用修改方法: "+user2.toString());
//使用删除方法
userMapper.deleteUser(user2.getId());
//使用查询所有方法
List<User> lists2 = userMapper.selectAll();
System.out.println("使用查询所有方法:");
for(User u : lists2){
System.out.println(u.toString());
}
} catch (IOException e) {
e.printStackTrace();
}
} }
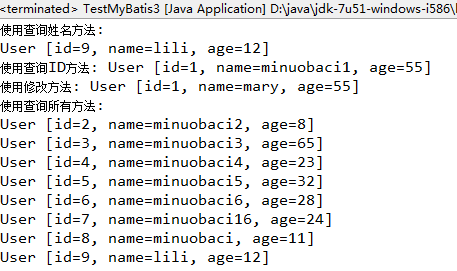
4:测试结果
struts2、hibernate的知识点的更多相关文章
- struts2+hibernate整合-实现登录功能
最近一直学习struts2+hibernate框架,于是想把两个框架整合到一起,做一个小的登录项目.其他不多说,直接看例子. 1).Struts2 和hibernate的环境配置 包括jar包.web ...
- JQuery+Ajax+Struts2+Hibernate 实现完整的登录注册
写在最前: 下午有招聘会,不想去,总觉得没有准备好,而且都是一些不对口的公司,可是又静不下心来,就来写个博客. 最近在仿造一个书城的网站:http://www.yousuu.com ,UI直接拿来用, ...
- struts2+hibernate+poi导出Excel实例
本实例通过struts2+hibernate+poi实现导出数据导入到Excel的功能 用到的jar包: poi 下载地址:http://poi.apache.org/ 根据查询条件的选择显示相应数据 ...
- 工作笔记3.手把手教你搭建SSH(struts2+hibernate+spring)环境
上文中我们介绍<工作笔记2.软件开发经常使用工具> 从今天開始本文将教大家怎样进行开发?本文以搭建SSH(struts2+hibernate+spring)框架为例,共分为3步: 1)3个 ...
- Spring整合Struts2,Hibernate的xml方式
作为一个学习中的码农,一直学习才是我们的常态,所以最近学习了SSH(Spring,Struts2,Hibernate)整合,数据库用的MySQL. 写了一个简单的例子,用的工具是IntelliJ Id ...
- Struts2+Hibernate框架探险
写这篇文章的目的 了解 JavaWeb 开发的人都知道SSH和SSM框架,前段时间开始接触 JavaWeb 开发,看了几个教学视频后就想上手构建一个小型 Web项目,可在跟着视频敲代码当中,使用 St ...
- 简单Spring+Struts2+Hibernate框架搭建
使用Maven+Spring+Struts2+Hibernate整合 pom文件 <project xmlns="http://maven.apache.org/POM/4.0.0&q ...
- SSH(Spring Struts2 Hibernate)框架整合(注解版)
案例描述:使用SSH整合框架实现部门的添加功能 工程: Maven 数据库:Oracle 框架:Spring Struts2 Hibernate 案例架构: 1.依赖jar包 pom.xml < ...
- [Java web]Spring+Struts2+Hibernate整合过程
摘要 最近一直在折腾java web相关内容,这里就把最近学习的spring+struts2+hibernate进行一个整合,也就是大家经常说的ssh. 环境 工具IDE :Idea 2018 数据库 ...
- Struts2+Hibernate+Spring 整合示例
转自:https://blog.csdn.net/tkd03072010/article/details/7468769 Struts2+Hibernate+Spring 整合示例 Spring整合S ...
随机推荐
- Python 起步 环境配置
1:https://www.python.org/ 首先进入这个网址,选择自己喜欢的版本 2:嘛,我以前装的是2.7,把下载好的安装一下就行 3:我的电脑Python的安装路径C:\Progra ...
- mac终端快捷键
mac终端快捷键: http://www.jianshu.com/p/e6c364084c22
- vbox 挂载共享文件时可能出现的问题以及对应的解决办法
VMBox挂载共享文件时可能出现的问题以及对应的解决办法 如果出现“未能加载虚拟光盘***.iso 到虚拟电脑的错误” : 左边一栏,右键光盘,eject,再安装
- man时括号里的数字是啥意思
https://www.cnblogs.com/istarstar/p/7851233.html 具体含义可以man man来查看(自己查自己). MANUAL SECTIONS The standa ...
- 6 - 编码解码器-一种channelHandler
6.1 解码器 6.1.1 抽象类-ByteToMessageDecoder decode(ChannelHandlerContext ctx, ByteBuf in, List<Object& ...
- Spring4.x、SpringMVC和DButils整合
tomcat 8.Spring 4.X.JDK1.8 需要jar包: 1)日志组件:log4j # debug < info < warn < error log4j.rootLog ...
- 设置VS代码模板
本文URL:http://www.cnblogs.com/CUIT-DX037/p/6770366.html 打开VS安装目录下:\Microsoft Visual Studio 12.0\Commo ...
- 生产消费者模式与python+redis实例运用(中级篇)
上一篇文章介绍了生产消费者模式与python+redis实例运用(基础篇),但是依旧遗留了一个问题,就是如果消费者消费的速度跟不上生产者,依旧会浪费我们大量的时间去等待,这时候我们就可以考虑使用多进程 ...
- AngularJS(十):依赖注入
本文也同步发表在我的公众号“我的天空” 依赖注入 依赖注入不是AngularJS独有的概念,而是现代软件开发与架构的范畴,但是在AngularJS中“依赖注入”是其核心思想之一,所以我们专门来学习一下 ...
- Django--对表的操作
一丶多表创建 1.创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之 ...