【学习笔记】GBDT算法和XGBoost
前言
这一篇内容我学了足足有五个小时,不仅仅是因为内容难以理解,
更是因为前面CART和提升树的概念和算法本质没有深刻理解,基本功不够就总是导致自己的理解会相互在脑子里打架,现在再回过头来,打算好好总结一下这两个强大的算法
感谢B站up老弓的学习日记的耐心讲解,附上链接 https://www.bilibili.com/video/BV1K5411g7nB
下面的截图也将从该视频中截出
GBDT
GBDT概述
GBDT也是集成学习Boosting家族的成员,但是却和传统的Adaboost有很大的不同。回顾下Adaboost,我们是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮的迭代下去。GBDT也是迭代,使用了前向分布算法,但是弱学习器限定了只能使用CART回归树模型,同时迭代思路和Adaboost也有所不同。在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是ft−1(x), 损失函数是L(y,ft−1(x)), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x),让本轮的损失函数L(y,ft(x))=L(y,ft−1(x)+ht(x))最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
GBDT回归算法
为什么可以用泰勒二阶展开呢,我们既然定义了任意损失函数都可以进行回归,那么我们就要给出每一轮的训练方法,我们自己的损失函数.但是不管你怎么变化,每次计算这些东西的时候都是需要输入这一轮的特征值和上一轮的特征值的,把两次的损失函数做差,才能得到增长情况,因此也就想到了泰勒公式
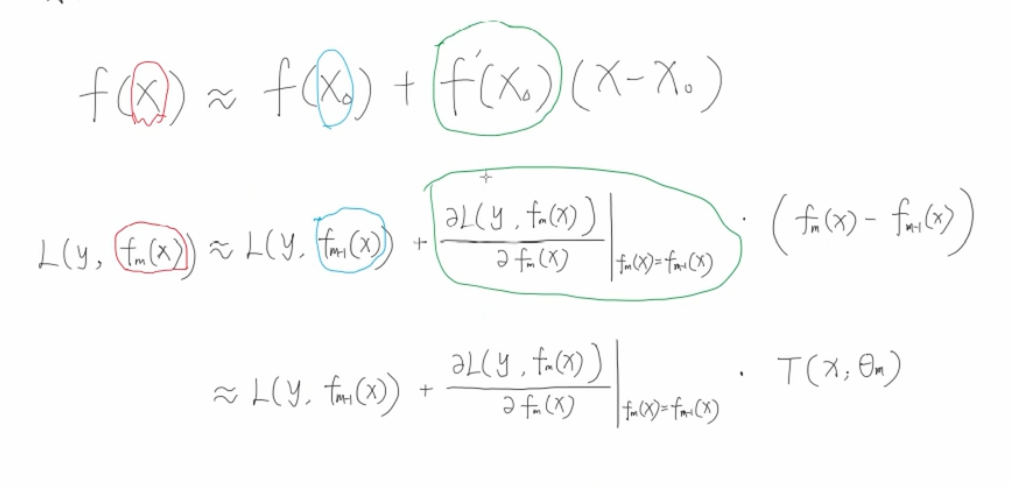
因为需要满足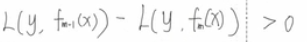 ,所以我们有
,所以我们有
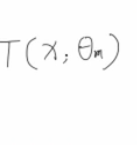
这两个东西相等的时候,就是一个平方项了,就有
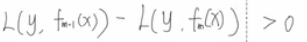
所以才有了那个经典负梯度表示公式

以上就是整个GBDT算法的原理,然后的工作就是,每次都永久出来的r来更新训练集,然后用训练集拟合,拟合完的结果再去和上一次求出的东西累加即可,最后得出的提升树就会不断接近真实的数据集
GBDT优缺点
- 可以灵活处理各种类型的数据,包括连续值和离散值。
- 在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
- 使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
- 由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
Xgboost
从GBDT到XGBoost
作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化:
一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以直接很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。
二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度。
三是算法健壮性的优化:对于缺失值的特征,通过枚举所有缺失值在当前节点是进入左子树还是右子树来决定缺失值的处理方式。算法本身加入了L1和L2正则化项,可以防止过拟合,泛化能力更强。
在上面三方面的优化中,第一部分算法本身的优化是重点也是难点。现在我们就来看看算法本身的优化内容。
目标函数
目标函数可以分为两个部分,一部分是损失函数,一部分是正则(用于控制模型的复杂度)。
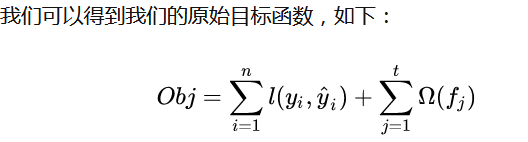
这个式子右边的前半部分就是损失函数,后半部分就是正则,这个正则可以根据当前叶子节点个个数给出一个惩罚值来预防过拟合的问题,现在我们对损失函数和正则分开讨论
简单化损失函数
gboost是前向迭代,我们的重点在于第t个树,所以涉及到前t-1个树变量或者说参数我们是可以看做常数的。
所以我们的损失函数进一步可以化为如下,其中一个变化是我们对正则项进行了拆分,变成可前t-1项,和第t项:
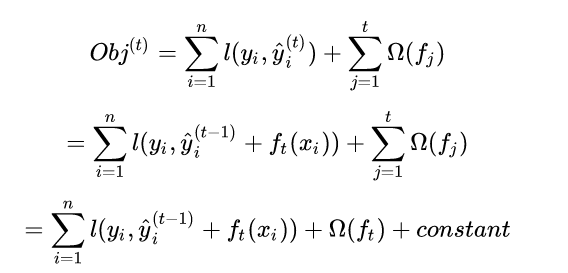
基于此,在不改变目标函数精读的情况下,我们已经做了最大的简化,最核心的点就是我们认为前t-1个树已经训练好了,所以涉及到的参数和变量我们当成了常数。
接下来,我们使用泰勒级数,对目标函数近似展开.
损失函数展开公式细节推导如下:

因为GBDT里面对泰勒展开原理已经有了详细的推导,所以这里就不说了
XGBoost损失函数的优化求解
关于如何一次求解出决策树最优的所有J个叶子节点区域和每个叶子节点区域的最优解wtj,我们可以把它拆分成2个问题:
- 如果我们已经求出了第t个决策树的J个最优的叶子节点区域,如何求出每个叶子节点区域的最优解wtj?
- 对当前决策树做子树分裂决策时,应该如何选择哪个特征和特征值进行分裂,使最终我们的损失函数Lt最小?
对于第一个问题,其实是比较简单的,我们直接基于损失函数对wtj求导并令导数为0即可。这样我们得到叶子节点区域的最优解wtj表达式为:
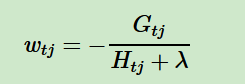
现在我们回到XGBoost,我们已经解决了第一个问题。现在来看XGBoost优化拆分出的第二个问题:如何选择哪个特征和特征值进行分裂,使最终我们的损失函数最小?
在GBDT里面,我们是直接拟合的CART回归树,所以树节点分裂使用的是均方误差。XGBoost这里不使用均方误差,而是使用贪心法,即每次分裂都期望最小化我们的损失函数的误差
这里我对贪心算法解释是,每次回调去一个特征,这个特征就可以把根节点分裂,然后再根据这些不同的特征来计算最佳的特征选取,以保证我们的损失函数可以最迅速的准确划分,接近真实值。而用于比较选取的增益值,则是分裂前损失减去分裂后的损失,增益越大,损失下降的就越多
XGBoost与GBDT比较
与GBDT相比,Xgboost的优化点:
- 算法本身的优化:首先GBDT只支持决策树,Xgboost除了支持决策树,可以支持多种弱学习器,可以是默认的gbtree, 也就是CART决策树,还可以是线性弱学习器gblinear以及DART;其次GBDT损失函数化简的时候进行的是一阶泰勒公式的展开,而Xgboost使用的是二阶泰勒公式的展示。还有一点是Xgboost的目标函数加上了正则项,这个正则项是对树复杂度的控制,防止过拟合。
- 可以处理缺失值。尝试通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向
- 运行效率:并行化,单个弱学习器最耗时的就是决策树的分裂过程,对于不同特征的特征分裂点,可以使用多线程并行选择。这里想提一下,我自己理解,这里应该针对的是每个节点,而不是每个弱学习器。这里其实我当时深究了一下,有点混乱。为什么是针对每个节点呢?因为我每个节点也有很多特征,所以在每个节点上,我并行(多线程)除了多个特征,每个线程都在做寻找增益最大的分割点。还有需要注意的一点是Xgboost在并行处理之前,会提前把样本按照特征大小排好序,默认都放在右子树,然后递归的从小到大拿出一个个的样本放到左子树,然后计算对基于此时的分割点的增益的大小,然后记录并更新最大的增益分割点。
【学习笔记】GBDT算法和XGBoost的更多相关文章
- 用Spark学习FP Tree算法和PrefixSpan算法
在FP Tree算法原理总结和PrefixSpan算法原理总结中,我们对FP Tree和PrefixSpan这两种关联算法的原理做了总结,这里就从实践的角度介绍如何使用这两个算法.由于scikit-l ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- 北京大学Cousera学习笔记--6-计算导论与C语言基础--计算机的基本原理-认识程序设计语言 如何学习
1.是一门高级程序语言 低级语言-机器语言(二进制) 汇编语言-load add save mult 高级语言:有利于人们编写理解 2.C语言的规范定义非常的宽泛 1.long型数据长度不短于int型 ...
- 北京大学Cousera学习笔记--8-计算导论与C语言基础--C的运算部分
赋值运算符 1.两边类型不同:赋值时要进行类型转换,右边要转换到左边 2.长数赋值短数 最后的部分截断赋值给短数 3.短数赋给长数 数不变 4.符号位赋值 --计算机不区分符号位数字位,直接赋值 表达 ...
- 北京大学Cousera学习笔记--7-计算导论与C语言基础--基本数据类型&变量&常量
1.整形数据 1.基本型(int 4B).短整型(short 2B).长整型(long 4B) VC环境下 sizeof运算符用于计算某种类型的对象在内存中所占的字节数 ,用法:size(int) ...
- 北京大学Cousera学习笔记--5-计算导论与C语言基础--计算机的基本原理-设计程序
只要你认真的思考,你就会发现这个世界是如此的简单,正如我们想象的一样,正因为如此,我们的思考才更加的有价值 1.单词:关键字(有特定含义的):其他词用关键字定义出来 2.数和计算符号:数据类型+运算符 ...
- 北京大学Cousera学习笔记--4-计算导论与C语言基础--计算机的基本原理-程序运行的基本原理
已知:电路能完成计算 怎么计算:设计好很多个原子电路,需要的时候就把他们临时组装在一起--ENIAC 升级:冯诺依曼-EDVAC(现在的计算机都是) 1.通过某种命令来控制计算机.让计算机按照这种命令 ...
- 北京大学Cousera学习笔记--3-计算导论与C语言基础-第一讲.计算机的基本原理-计算机怎么计算-数的二进制
思考问题 1.“数”在计算机中是如何表示的? 2.逻辑上“数”是怎么运算的? 3.物理上“数”的计算是怎么实现的? 从图灵机计算问题得出: 1.字母表中的符号越多(几进制),读入移动次数减少,但程序数 ...
- 北京大学Cousera学习笔记--2-计算导论与C语言基础-第一讲.计算机的基本原理-图灵机
有限状态读写头从一个初始状态开始,对存储器上的输入数据进行读或写操作,经过有限步操作之后停机,此时存储器上的输出数据就是计算结果 (1) 图灵机的构成: 1.一条存储带:双向无限延长:上有一个个的小方 ...
随机推荐
- labview从入门到出家9(进阶篇)--串口通讯
Labview在工控领域,如产线,实验室等环境用得较多,其中与仪器通讯控制的方式有串口(RS232,RS485,TTL),GPIB,网口,CAN等,其中串口在仪器还有单片机控制中用来调试居多.(很 ...
- lombok的常用注解
出处: https://blog.csdn.net/sunnyzyq/article/details/119992746 1. @Accessors 源码 我们打开 @Accessors 的源码可以看 ...
- 使用Docker-compose来封装celery4.1+rabbitmq3.7服务,实现微服务架构
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_115 大家都知道,Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,在之前的一篇文章中:python3.7+Torn ...
- 附加进程 到远程服务器中Docker容器内 调试
很多时候,我们在本地开发过程中程序运行很正常,但是发布到线上之后由于环境的原因,可能会有一些异常.通常我们会通过日志来分析问题,除了日志还有一种常用的调试手段就是:附加进程. VS中的附加进程非常强大 ...
- CC2530_ZigBee+华为云IOT:设计一套属于自己的冷链采集系统
摘要:以CC2530单片机为核心器件,设计一个冷链环境信息采集系统,利用传感器技术对冷藏仓内的环境参数进行采集,上传到华为云物联网云平台,然后通过手机端或移动端进行显示,便于分析,观察冷链环境信息. ...
- 2022了你还不会『低代码』?数据科学也能玩转Low-Code啦! ⛵
作者:韩信子@ShowMeAI 数据分析实战系列:http://www.showmeai.tech/tutorials/40 机器学习实战系列:http://www.showmeai.tech/tut ...
- ABP 6.0.0-rc.1的新特性
2022-07-26官方发布ABP 6.0.0-rc.1版本,本文挑选了几个新特性进行了介绍,主要包括LeptonX Lite默认主题.OpenIddict模块,以及如何将Identity Ser ...
- 万答#4,延迟从库加上MASTER_DELAY,主库宕机后如何快速恢复服务
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 当主库宕机后,延迟从库如何才能"取消"主动延迟,以便恢复服务 ...
- Linux系列之压缩命令
前言 Linux 有三个常用的压缩命令:gzip.bzip2和 tar .本文介绍它们的区别和简单用法. 压缩文件 数据压缩是去除数据中冗余部分的过程,需要通过压缩算法完成.这些算法可分为两类: 无损 ...
- DolphinScheduler & K8s 在优路科技的实践
T 摘要 · 本文通过介绍DolphinScheduler on Kubernetes 在优路科技的实践,阐述了DolphinScheduler如何在云原生时代,更好地助力企业实现高效的数据调度解决方 ...