图说论文《LSM-based Storage Techniques: A Survey》
本文从 《LSM-based Storage Techniques: A Survey》 摘取部分图片,来介绍 LSM tree 的相关内容。详细内容请查看论文原文。
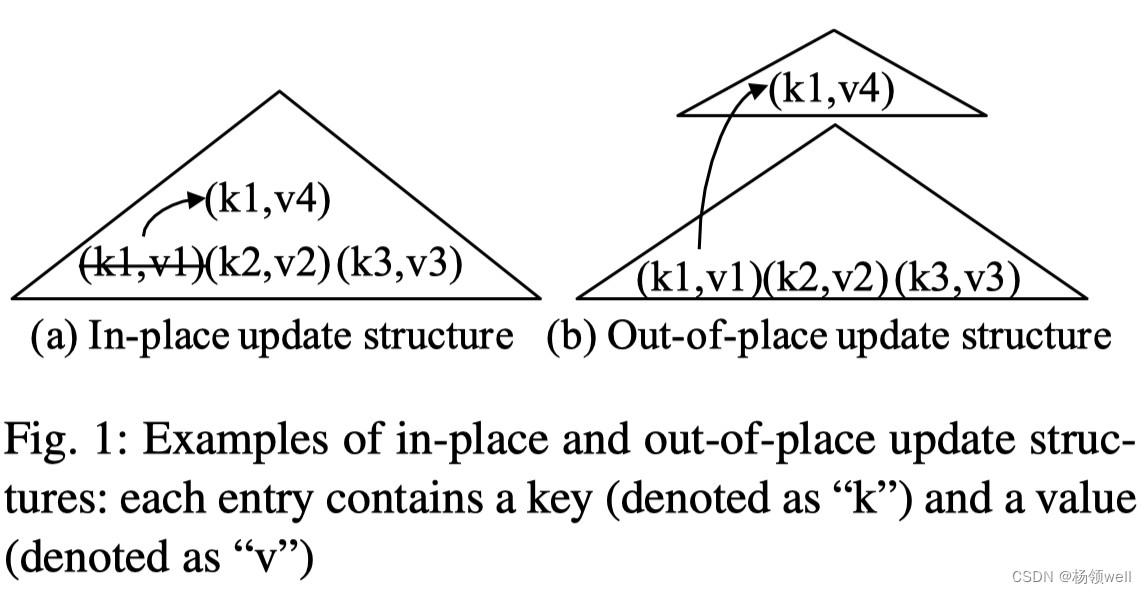
in-place update V.S. out-of-place update
- 索引结构通常有两种数据的更新策略:in-place update 和 out-of-place update。
- in-place update:在原数据处覆盖写入,e.g. B+树。该策略读性能较好(只需要读一份数据);随机 IO导致写性能较差;空间碎片导致空间利用率下降。
- out-of-place update:在新的地方写入更新后的数据(原数据不做变更), e.g. LSM tree。与 in-place update 相反,该策略写性能较好(顺序写);同一份数据保存多份导致读性能较差;顺序写减少空间碎片从而提高空间利用率。
LSM-tree 基本原理
- LSM-tree 包含 C0, C1, …, Ck 共 k+1 层, 每一层的数据都是 B+ 树。其中 C0 层维护在内存中,而 C1, …, Ck 层维护在磁盘。
- Write 操作: 每次写入数据都只写入 C0 层。
- Point Query 操作:每次点查询操作会依次遍历 C0, C1, …, Ck, 返回查询到最新版本的数据。如果遍历完之后都没有查到数据,则该数据不存在。比如, 查询
key = b的值, 在 C0 层查到b=2, 直接返回该值,而不用继续遍历 C1, …, Ck。 - Range Query 操作:范围查询会并发的在 C0, C1, …, Ck 查找指定范围的数据,然后根据优先级从高到低将每层的查询结果合并为最终的查询结果。 比如,查询结果为
<C0, a=1, b=2>, <C1, b=3, c=3>, 合并之后的最终结果为a=1, b=2, c=3。 - Delete 操作:删除操作写入删除标记数据,由后台进程负责异步删除。
- Merge 操作:C0, C1, …, Ck 每层容量固定,依次按照一定比率递增。当某层 Ci 数据规模达到该层容量上限,后台 Merge 进程 会将该层数据合入 Ci+1 层。

Merge 策略: Leveling Merge Policy V.S. Tiering Merge Policy
注:图中的数字表示 Index 的范围。如 0-100 指 Index 在 0-100 的数据可以保存在该 component。
- Leveling Merge Policy:每一层只包含一个 component。L 层的 component 容量是 L-1 层的 T 倍。当 L 层达到其容量上限,会被合并到 L+1 层。如 Fig.3(a),L0 的数据达到上限,合入到 L1 层。
- Tiering Merge Policy:每一层最多包含 T 个 component。当 L 层达到容量上限,它的 T 个 component 会合并为 L+1 层的一个 component。如果 L 为配置的最大层,则合并后的 component 保持在该层。如 Fig.3(b), T=2, L0 层的数据达到上限,它的 2 个component 合并为了 L1 层的一个新的 component。

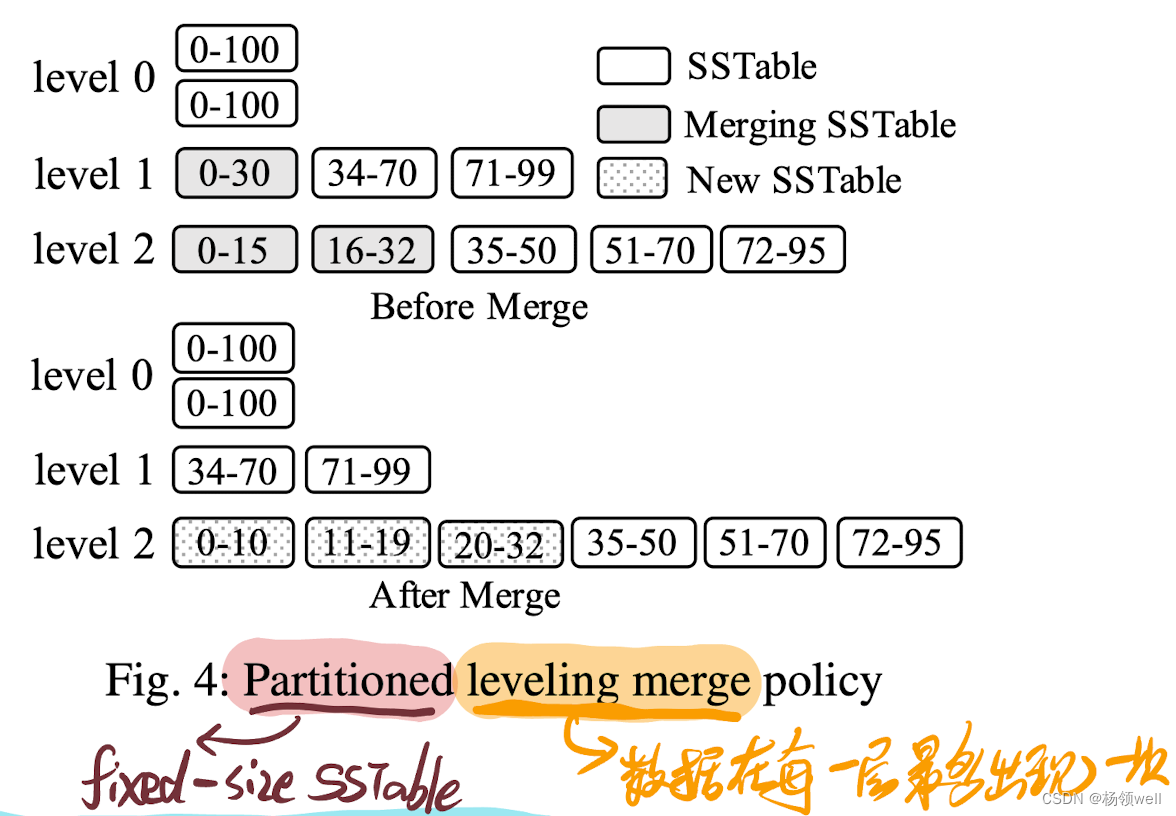
Partition Policy: partitioned leveling merge policy V.S. partitioned tiering merge policy
LSM-tree 有两类比较常见的优化策略:布隆过滤器(Bloom Filter)和数据分区(Partitioning)。
- 布隆过滤器(Bloom Filter):可以为每一棵 B+ 树或它的非叶子节点绑定一个布隆过滤器,以提高数据的查询效率。
- 数据分区(Partitioning):可以将每一层的 component 拆分成更小的 partition(记作: SSTable)。数据分区可以提高 merge 的效率;减少merge 过程中对磁盘空间的浪费等。
不同的 merge policy, partioning 的处理方式也有所不同。
partitioned leveling merge policy
- 每一层的数据被 partition 为多个相同大小的 SSTable。
- L0 数据直接从内存 flush 而来,因此不需要进行 partition。
- 读写操作与非 partitioned 的 leveling merge policy 一致。
- Merge 流程: 将 L 层一个 SSTable merge 到 L+1 层,需要将 L+1 层所有和该 SSTable 有重叠 Index 的 SSTable 一起,合并为 L+1 层新的 SSTable。如 Fig.4 Merge 0-30(L1) 到 L2。L2 层与它 Index 有重叠的 SSTable 有 0-15(L2) 和 16-32(L2)。将0-30(L1), 0-15(L2) 和 16-32(L2) 三个 SSTable 一起合并为 L2 层新的 SSTable: 0-10(L2), 11-19(L2) 和 20-32(L2)。
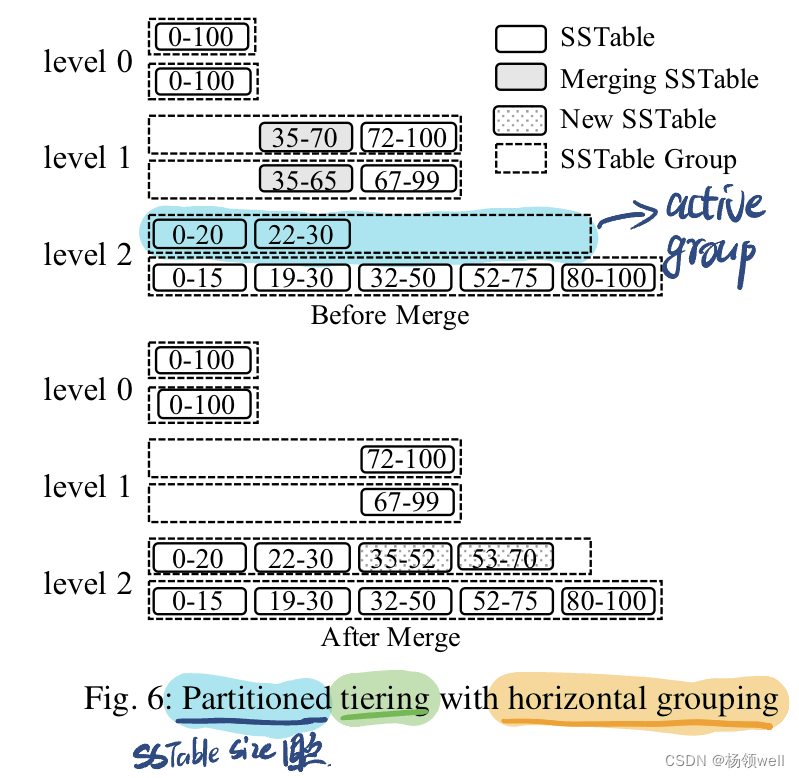
partitioned tiering merge policy: vertical grouping V.S. horizontal grouping
tiering merge policy 将每层的数据分成不同的 Group 进行处理。将重合 Index 的 SSTable 拆分到同一个 Group 的策略称为 vertical grouping policy;将不重合 Index 的 SSTable 拆分到同一个 Group 的策略称为 horizontal grouping policy。
partitioned tiering with vertical grouping
- 每一层的 SSTable 被拆分为 Index 互相重叠的 Group。
- Merge 操作:Fig.5 中, 0-31(L1), 0-30(L1) 中的 Index 在 0-15(可能) 部分 merge 为 0-13(L2) 所在 Group 的一个 SSTable,即 0-12(L2);其 Index 在 16-34(可能) 部分 merge 到 16-32(L2) 所在 Group 的一个 SSTable,即 17-31(L2)。
- 查询操作: 在该策略下,每一层的查询操作需要查询该层 Index 覆盖的 Group 下的所有 SSTable 的情况。
- 在这种策略下,上一层相同 Group 的 SSTable 需要 Merge 到下一层 Index 重叠的 Group 内,SSTable 大小不再固定。

partitioned tiering with horizontal grouping
每一层大小固定的的 SSTable 被拆分为 Index 互不重叠的 Group。
每一层包含一个接受上一层合入进来的新 SSTable 的 Group,称之为 active group。
Merge 操作: 合并 L 层的某个 SSTable 时, 选择该层所有其他 group 中与其 Index 重叠的 SSTable,合并到 L+1 层 active group 中。 如 Fig.6, 选择该层其他 Group 与 35-70(L1) Index 重叠的 SSTable,即 35-65(L1)。将35-70(L1),35-65(L1) 合并到 L2 层的 active group 中,即 35-52(L2) 和 53-70(L2)。
Reference
图说论文《LSM-based Storage Techniques: A Survey》的更多相关文章
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 【RS】Deep Learning based Recommender System: A Survey and New Perspectives - 基于深度学习的推荐系统:调查与新视角
[论文标题]Deep Learning based Recommender System: A Survey and New Perspectives ( ACM Computing Surveys ...
- 论文笔记: Deep Learning based Recommender System: A Survey and New Perspectives
(聊两句,突然记起来以前一个学长说的看论文要能够把论文的亮点挖掘出来,合理的进行概括23333) 传统的推荐系统方法获取的user-item关系并不能获取其中非线性以及非平凡的信息,获取非线性以及非平 ...
- 论文笔记: Matrix Factorization Techniques For Recommender Systems
Recommender system strategies 通过例子简单介绍了一下 collaborative filtering 以及latent model,这两个方法在之前的博客里面介绍过,不累 ...
- 【万字长文】使用 LSM Tree 思想实现一个 KV 数据库
目录 设计思路 何为 LSM-Treee 参考资料 整体结构 内存表 WAL SSTable 的结构 SSTable 元素和索引的结构 SSTable Tree 内存中的 SSTable 数据查找过程 ...
- 浅析Hadoop文件格式
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势.不过,MPP数据库社区也一直批评Hadoop由于文件格式并非为特定目的而建,因此序列化和反序 ...
- hadoop 原理: 浅析Hadoop文件格式
Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度为优势.不过,MPP数据库社区也一直批评Hadoop由于文件格式并非 为特定目的而建,因此序列化和反 ...
- 《Object Storage on CRAQ: High-throughput chain replication for read-mostly workloads》论文总结
CRAQ 论文总结 说明:本文为论文 <Object Storage on CRAQ: High-throughput chain replication for read-mostly wor ...
- PayPal高级工程总监:读完这100篇论文 就能成大数据高手(附论文下载)
100 open source Big Data architecture papers for data professionals. 读完这100篇论文 就能成大数据高手 作者 白宁超 2016年 ...
- 近年Recsys论文
2015年~2017年SIGIR,SIGKDD,ICML三大会议的Recsys论文: [转载请注明出处:https://www.cnblogs.com/shenxiaolin/p/8321722.ht ...
随机推荐
- 小米路由器局域网设备ping不通
问题 手机和电脑在同一个局域网内,都连接上小米路由器,我发现电脑部署的服务局域网设备都访问不到,甚至ping不到,排除了防火墙问题,最终发现是路由器一个设置导致的. 解决 将原来的混合加密,更换为强加 ...
- <七>理解多态
理解多态 多种多样的形态(静态多态,动态多态) 静态多态(编译时期) 1:函数重载 bool comparet(int ,int); bool compare(double,double); comp ...
- ArcGIS QGIS学习二:图层如何只显示需要的部分几何面数据(附最新坐标边界下载全国省市区县乡镇)
目录 前言 准备SHP数据 ArcMap 的筛选 QGIS 的筛选 如何编写查询条件 前言 当我们用GIS软件打开一个SHP文件的时候,会显示出里面全部的几何图形,假如我只想要其中的一部分数据显示出来 ...
- 云小课|云小课教您如何选择Redis实例类型
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:购买Redis实例 ...
- java面试题-线程
简述线程.程序.进程的基本概念.以及他们之间关系是什么? 系统运行程序到停止就是一个进程创建到消亡的过程,而线程则是进程的更小单位 线程有哪些基本状态? 初始,运行中,等待,阻塞,超时,终止1 关注公 ...
- python中文件操作相关基础知识
python中文件操作相关基础知识 文件的概念 1,文件的概念? 文件就是操作系统暴露给用户操作硬盘的快捷方式 , 当我们双击一个文件进行打开时,其实就是把硬盘中的数据加载到了内存中,然后展示给我们 ...
- node版本管理工具fnm踩坑
我建议是直接不要用fnm,还是老老实实用nvm吧 fnm下下来电脑防火墙会报毒(用github上推荐的cargo install fnm方式下载,并非第三方安装) Trojan.Generic.HgE ...
- 关于盒子动态高度与transition的问题
今天遇到个小问题 大概要实现类似手风琴的效果 本来设计是定死的高度,直接 height:0; - > height:xxxpx;但之后要改成动态变化的高度,手风琴展开后是个列表,并且列表每行高度 ...
- C#实现文件导入与导出
无论是文件的导入与导出都需要引入IO库,引入方法如下: using System.IO; 通过以下代码可以实现将文件导入到数组中 string path;//定义一个路径 OpenFileDialog ...
- LeetCode HOT 100:下一个排列
题目:31. 下一个排列 题目描述: 本题是给你一个整数数组,返回该数组的下一个线性顺序排列. 举个例子:给你一个[1, 2, 3]的数组,他的线性排列顺序从小到大依次为[1, 3, 2],[2, 1 ...