《Object Storage on CRAQ: High-throughput chain replication for read-mostly workloads》论文总结
CRAQ 论文总结
说明:本文为论文 《Object Storage on CRAQ: High-throughput chain replication for read-mostly workloads》 的个人理解,难免有理解不到位之处,欢迎交流与指正 。
论文地址:CRAQ Paper
0. 简介
Chain Replication with Apportioned Queries (CRAQ) 是一种对链式复制的改进,它通过在所有对象副本上分配负载,在保持强一致性的同时极大地提高了读吞吐量。
本文主要对链式复制、CRAQ 原理以及 CRAQ 的一致性模型做出总结。
1. 对象存储
在 基于对象 的存储中,数据作为整个单元呈现给应用程序。
对象存储支持两种基本原语:
read或query操作返回存储在对象名称下的数据块write或update操作更改单个对象的状态
对象存储更适合于平面名称空间,例如键值数据库,而不是层次目录结构。对象存储简化了支持整个对象修改的过程,通常,它们只需要考虑对特定对象的修改顺序,而不是整个存储系统。为每个对象提供一致性保证成本要低得多。
2. 一致性模型
本文涉及到的两种一致性模型为:
- 强一致性:系统保证对一个对象的读写操作都以顺序执行,并且对于一个对象的读操作总是会观察到最新被写入的值。
- 最终一致性:在系统中,对一个对象的写入仍是按顺序在所有节点上应用的,但对不同节点的最终一致性读取可能会在一段时间内(即,在写操作应用于所有节点之前)返回过时的数据。但是,一旦所有副本都接收到写入操作,则读操作将不会返回比最新提交的写操作更早的版本。事实上,如果一个 client 维护与特定节点的会话,那么它也会看到单调的读一致性。
3. 链式复制
链式复制 (Chain Replication、CR) 是一种跨多个节点复制数据的方法:
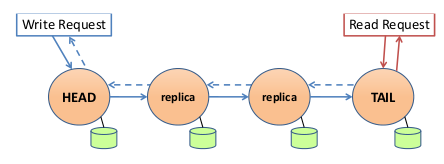
- 节点形成一个长度为 C 的链
- 链的头部节点处理来自客户端的所有写操作
- 当一个节点接收到写操作时,它将传播到链中的每一个节点
- 一旦写入到达尾部节点,它就被应用于链中的所有副本,并且被认为是提交的
- 当尾节点提交写操作时,会向客户端发送一个回复
- 尾部节点处理所有读操作,因此只有提交的值才能由读操作返回
链式复制实现了 强一致性:由于所有的读操作都是在尾部进行的,而所有写操作都在尾部提交,所以链尾可以简单地对所有操作应用一个总的顺序。
链式复制的简单拓扑使得写操作比提供强一致性的其他协议消耗更小。如在 Raft 中,leader 需要将每次写操作都发送给所有的 follower ,但是 CRAQ 中,head 只需要将每一次写操作发送一次;并且 Raft 中 leader 需要处理读写操作,而 CRAQ 中的 head 只需要处理写操作。
链式复制的 故障恢复:
- 当头节点出故障时:后续节点取代它成为头节点,没有丢失的已提交写操作
- 当尾节点出故障时:前一个节点取代它成为尾节点,没有丢失的写操作
- 当中间节点故障时:从链中去掉,前一个节点需要重新发送最近的写操作
局限性:对一个对象的所有读取必须都要转到同一个节点,尾节点的负载很大。
4. CRAQ
4.1 CRAQ原理
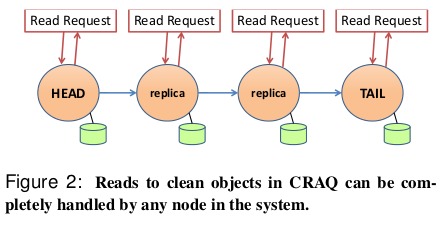
CRAQ 是链式复制的一种改进,它允许链中的任何节点执行读操作:
CRAQ 每个节点可以存储一个对象的多个版本,每个版本都包含一个单调递增的版本号和一个附加属性( 标识
clean还是dirty)当节点接收到对象的新版本时(通过沿向下传播的写操作),该节点将此最新版本附加到该对象的列表中
- 如果节点不是尾节点,则将版本标记为
dirty,并向后续节点传递写操作 - 如果节点是尾节点,则将版本标记为
clean,此时写操作是已提交的。然后,尾节点在链中往回发送ACK来通知其他节点提交
- 如果节点不是尾节点,则将版本标记为
当对象版本的
ACK到达节点时,该节点会将对象版本标记为clean。然后,该节点可以删除该对象的所有先前版本当节点收到对象的读请求时:
- 如果请求的对象的最新已知版本是干净的,则节点将返回此值
- 否则,节点将与尾节点联系,询问尾节点上该对象的最后提交版本号,然后,节点返回该对象的此版本

4.2 CRAQ性能提升
CRAQ 相对于 CR 的吞吐量改进发生在两种不同情况下:
- 读密集型工作负载:读操作可以在所有节点上执行,因此吞吐量与链长度呈线性比例关系
- 写密集型工作负载:大量写操作的工作负载中,更容易读取到
dirty数据,因此对尾节点的查询请求比较多。但是对尾节点查询的工作负载远低于所有读请求都由尾节点来执行的工作负载,因此 CRAQ 吞吐量高于 CR。
4.3 CRAQ的一致性模型
对于读操作, CRAQ 支持三种一致性模型:
- 强一致性:4.1 中描述的读操作可以使每次读取都读到最新写入的数据,因此提供了强一致性
- 最终一致性:允许节点返回未提交的新数据,即允许 client 可从不同的节点读到不一致的对象版本。但是对于一个 client 来说,由于它与节点建立会话,所以它的读操作是保证单调一致性的。
- 带有最大不一致边界的最终一致性:允许节点返回未提交的新数据,但是有不一致性的限制,这个限制可以基于版本,也可以基于时间。如允许返回一段时间内新写入但未提交的数据。
4.4 split-brain 问题
若两个相邻节点之间的网络连接断开,后面的节点会想去成为头节点,这样就会产生两个头节点。
CRAQ 本身并不会解决这样的问题,所以需要外部的分布式协调服务来解决这一问题,如使用 Zookeeper 。由 Zookeeper 来决定链的组成,决定哪个节点是头、尾,并监控哪个节点出了故障。当发生网络故障时,由 Zookeeper 来决定链的新组成,而不是基于各节点对于网络情况的自身感知。
《Object Storage on CRAQ: High-throughput chain replication for read-mostly workloads》论文总结的更多相关文章
- 《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》论文总结
Aurora总结 说明:本文为论文 <Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relation ...
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases
INTRODUCTION In modern distributed cloud services, resilience and scalability are increasingly ach ...
- Google Spanner vs Amazon Aurora: Who’ll Get the Enterprise?
https://www.clustrix.com/bettersql/spanner-vs-aurora/ Google Spanner versus Amazon Aurora In July 20 ...
- Amazon Aurora解读(SIGMOD 2017)
Amazon在SIGMOD 2017发表了论文<Amazon Aurora: DesignConsiderations for High Throughput Cloud-Native Rela ...
- 利用 AWS DMS 在线迁移 MongoDB 到 Amazon Aurora
将数据从一种数据库迁移到另一种数据库通常都非常具有挑战性,特别是考虑到数据一致性.应用停机时间.以及源和目标数据库在设计上的差异性等因素.这个过程中,运维人员通常都希望借助于专门的数据迁移(复制)工具 ...
- (转)Amazon Aurora MySQL 数据库配置最佳实践
转自:https://zhuanlan.zhihu.com/p/165047153 Amazon Aurora MySQL 数据库配置最佳实践 AWS云计算 已认证的官方帐号 1 人赞同了该文章 ...
- Game: Map Design Considerations 游戏地图设计指南
依据前文伏击战场景手稿, 用Tile Studio "草草"制作出该场景的地图: 生成的C源码: #ifndef _open_war_1Gfx_c #define _open_wa ...
- 一篇文章带你看懂AWS re:Invent 2018大会,揭秘Amazon Aurora
本文由云+社区发表 | 本文作者: 刘峰,腾讯云NewSQL数据库产品负责人.曾职于联想研究院,Teradata北京研发中心,从事数据库相关工作8年.2017年加入腾讯数据库产品中心,担任NewSQL ...
- 'Cloud Native': What It Means, Why It Matters
When HP announced July 28 that it was acquiring ActiveState's PaaS business, senior vice president B ...
- On cloud, be cloud native
本来不想起一个英文名,但是想来想去都没能想出一个简洁地表述该意思的中文释义,所以就用了一个英文名称,望见谅. Cloud Native是一个刚刚由VMware所提出一年左右的名词.其表示在设计并实现一 ...
随机推荐
- css3中的skew(skewX,skewY)用法
这是html代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> < ...
- 【快手初面】要求3个线程按顺序循环执行,如循环打印A,B,C
[背景]这个题目是当时远程面试时,手写的题目.自己比较惭愧,当时写的并不好,面试完就又好好的完善了下. 一.题意分析 3个线程要按顺序执行,就要通过线程通信去控制这3个线程的执行顺序. 而线程通信的方 ...
- Linux系统管理——Linux简介
UNIX与Linux发展史 UNIX发展历史 1.1965年,美国麻省理工学院(MIT),通用电气公司(GE)及AT&T的贝尔实验室联合开发Multics工程计划,其目标是开发一种交互式的具有 ...
- android中getWidth()和getMeasuredWidth()之间的区别
先给出一个结论:getMeasuredWidth()获取的是view原始的大小,也就是这个view在XML文件中配置或者是代码中设置的大小.getWidth()获取的是这个view最终显示的大小,这个 ...
- .Net Core微服务入门全纪录(五)——Ocelot-API网关(下)
前言 上一篇[.Net Core微服务入门全纪录(四)--Ocelot-API网关(上)]已经完成了Ocelot网关的基本搭建,实现了服务入口的统一.当然,这只是API网关的一个最基本功能,它的进阶功 ...
- ABP (.Net Core 3.1版本) 使用MySQL数据库迁移启动模板项目(1)
最近要搭建新项目,因为还没有用过.net core,所以想用.net core的环境搭建新项目,因为不熟悉.net core的架构,所以就下载了abp项目先了解一下. 因为自己太菜了,下载了模板项目, ...
- SpringMVC面试专题
SpringMVC面试专题 1. 简单的谈一下SpringMVC的工作流程? 流程 1.用户发送请求至前端控制器DispatcherServlet 2.DispatcherServlet收到请求调用H ...
- python变量拷贝
写python代码时候,如:A = 0,B = A,B = 1, 有时候会发现A变成了1,那么怎么办呢? 以下是伪代码: import copy ... X_ = copy.copy(X) ... 这 ...
- SQL语句中where 1=1的意义
我们在看别人项目的时候,很多时候看到这样的SQL语句: select * from user where 1=1 其中这个where1=1是有特殊意义的,包含以下两种情境:动态SQL拼接和查询表结构. ...
- 理解与使用Javascript中的回调函数 -2
在javascript中回调函数非常重要,它们几乎无处不在.像其他更加传统的编程语言都有回调函数概念,但是非常奇怪的是,完完整整谈论回调函数的在线教程比较少,倒是有一堆关于call()和apply() ...