淘宝商品信息定向爬虫.py(亲测有效)


import requests
import re def getHTMLText(url):
try:
kv = {
'cookie': '', #要换成自己网页的cookie
'user-agent':'Mozilla/5.0' # 请求头;指定访问浏览器为Mozilla5.0版本的浏览器
}
r = requests.get(url,timeout=30,headers=kv)
r.encoding = r.apparent_encoding
return r.text
except:
return "" def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1]) # eval函数去掉最外层的单引号,双引号
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("") def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1])) def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList) main()
查找自己cookie的步骤如下:
(1)进入淘宝页面
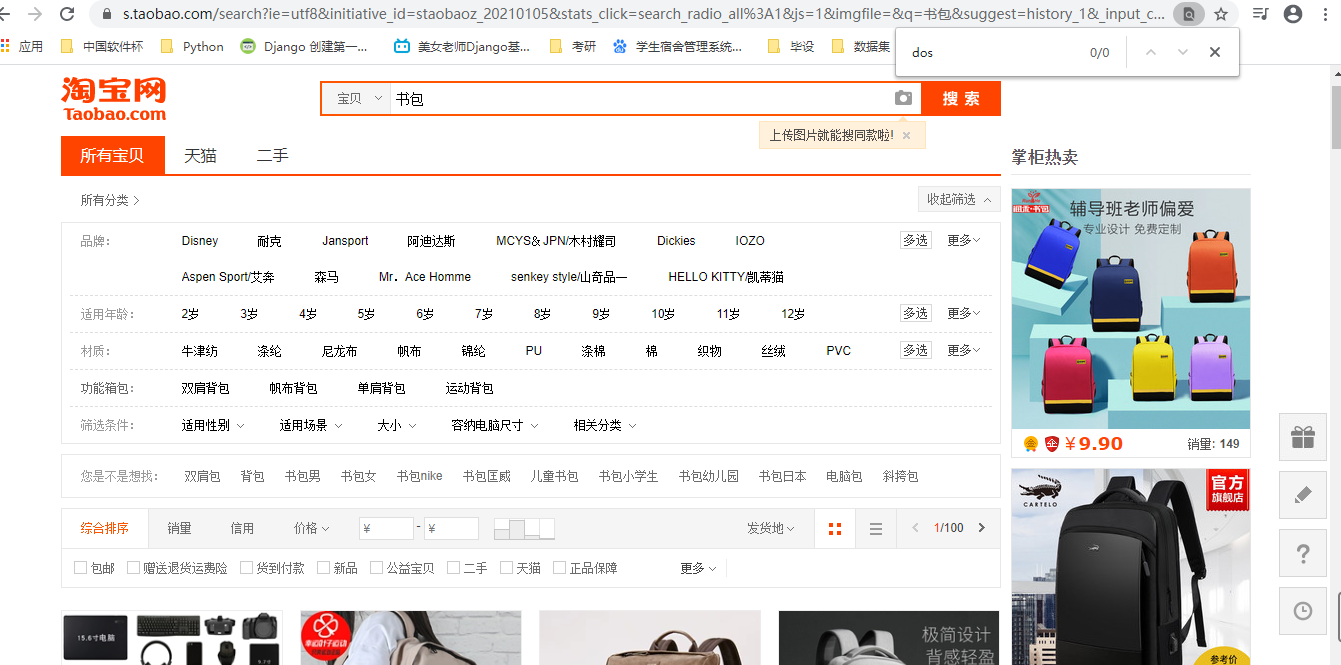
(2)按下F12,刷新页面,点击最上面的NetWork,找到下面文件
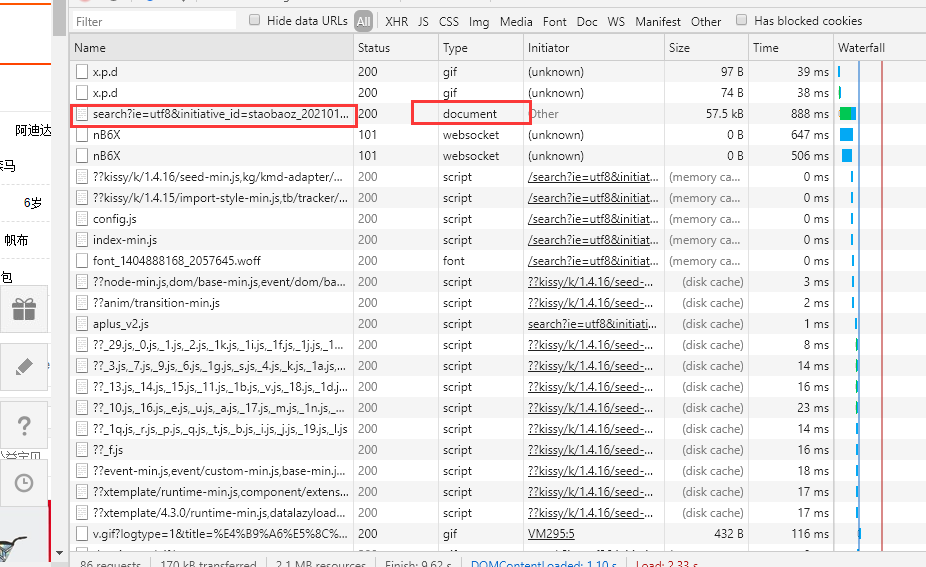
(3)找到RequestHeaders,找到里面的Cookie复制即可
淘宝商品信息定向爬虫.py(亲测有效)的更多相关文章
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- python 获取淘宝商品信息
python cookie 获取淘宝商品信息 # //get_goods_from_taobao import requests import re import xlsxwriter cok='' ...
- <day003>登录+爬取淘宝商品信息+字典用json存储
任务1:利用cookie可以免去登录的烦恼(验证码) ''' 只需要有登录后的cookie,就可以绕过验证码 登录后的cookie可以通过Selenium用第三方(微博)进行登录,不需要进行淘宝的滑动 ...
- 爬取淘宝商品信息,放到html页面展示
爬取淘宝商品信息 import pymysql import requests import re def getHTMLText(url): kv = {'cookie':'thw=cn; hng= ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- 淘宝开放平台php-sdk测试 获取淘宝商品信息(转)
今天想使用淘宝开放平台的API获取商品详情,可是以前一直没使用过,看起来有点高深莫测,后然看开发入门,一步一步,还真有点感觉了,然后看示例,还真行了,记下来以后参考.其中遇到问题,后然解决了.因为我已 ...
- selenium+pyquery爬取淘宝商品信息
import re from selenium import webdriver from selenium.common.exceptions import TimeoutException fro ...
- selenium+phantomjs+pyquery 爬取淘宝商品信息
from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium ...
随机推荐
- CSRF跨站点请求伪造(Cross Site Request Forgery)攻击
CSRF跨站点请求伪造(Cross Site Request Forgery)和XSS攻击一样,有巨大的危害性,就是攻击者盗用了用户的身份,以用户的身份发送恶意请求,但是对服务器来说这个请求是合理的, ...
- Idea提交文件时,添加不需要提交的文件至.gitignore文件中
1.在Idea中,依次打开File ---->Setting ---> Editor --->File Types 2.在当前编辑栏下方找到Ignore files and fold ...
- 在mysql中正常查询的句子,在C#中出错,原因是定义了变量。
在C#中 查询一样. 运行报错 Fatal error encountered during command execution." 命令执行过程中碰到的致命错误." MySqlE ...
- C#MSDN简体中文 最后一版本 2007年的
我在学习C# 需要 先看 MSDN文档,英文看的很吃力,就找了好久 MSDN简体中文版本的: 因为微软已经关闭网站(MSDN中文的链接),我找到的就是 磁力链接的: 我分享出来 ,有需要的 自行下载 ...
- Unity 导出设置iOS 项目
别人的代码 xcode打包部分设置的脚本如下 public class XcodeSetting : MonoBehaviour { private static List<Menu> m ...
- SQL SERVER 导入EXCEL表 报错 未在本地计算机上注册“Microsoft.ACE.OLEDB.12.0”提供程序
1 已经正确安装了 accessdatabaseengine 2 使用 Microsoft SQL Server Management Studio 里面的数据库 右键-->导入数据 解决方案 ...
- 网页返回unicode源码 python解码详细步骤
刚入门python! 记录一下网页返回源码,中文部分被unicode编码,python如何处理 1.先提取编码后的数据(如果不提取正篇源码直接unicode解码,解码方法无法识别) 这个步骤属于逻辑问 ...
- Hihocoder 1067
最近公共祖先二 离线算法 /**/ #include <cstdio> #include <cstring> #include <cmath> #include & ...
- CH573 CH582 CH579蓝牙从机(peripheral)例程讲解六(蓝牙设置白名单)
蓝牙从机设置白名单,可以只扫描应答(白名单中列出的)设备,只允许(白名单中列出的)设备连接. 蓝牙主机设置白名单,可以只扫描.连接特定的蓝牙设备(白名单中列出的). 一.蓝牙从机白名单设置有关的函数介 ...
- autossh 使用
Table of Contents 1. centos7下配置为服务 2. 命令式使用 2.1. 映射远程主机防火墙之后的端口到本机 2.2. 映射本机端口到远程主机 centos7下配置为服务 编辑 ...