Redis 缓存击穿(失效)、缓存穿透、缓存雪崩怎么解决?
原始数据存储在 DB 中(如 MySQL、Hbase 等),但 DB 的读写性能低、延迟高。
比如 MySQL 在 4 核 8G 上的 TPS = 5000,QPS = 10000 左右,读写平均耗时 10~100 ms。
用 Redis 作为缓存系统正好可以弥补 DB 的不足,「码哥」在自己的 MacBook Pro 2019 上执行 Redis 性能测试如下:
$ redis-benchmark -t set,get -n 100000 -q
SET: 107758.62 requests per second, p50=0.239 msec
GET: 108813.92 requests per second, p50=0.239 msec
TPS 和 QPS 达到 10 万,于是乎我们就引入缓存架构,在数据库中存储原始数据,同时在缓存总存储一份。
当请求进来的时候,先从缓存中去数据,如果有则直接返回缓存中的数据。
如果缓存中没数据,就去数据库中读取数据并写到缓存中,再返回结果。
这样就天衣无缝了么?缓存的设计不当,将会导致严重后果,本文将介绍缓存使用中常见的三个问题和解决方案:
- 缓存击穿(失效);
- 缓存穿透;
- 缓存雪崩。
缓存击穿(失效)
高并发流量,访问的这个数据是热点数据,请求的数据在 DB 中存在,但是 Redis 存的那一份已经过期,后端需要从 DB 从加载数据并写到 Redis。
关键字:单一热点数据、高并发、数据失效
但是由于高并发,可能会把 DB 压垮,导致服务不可用。如下图所示:
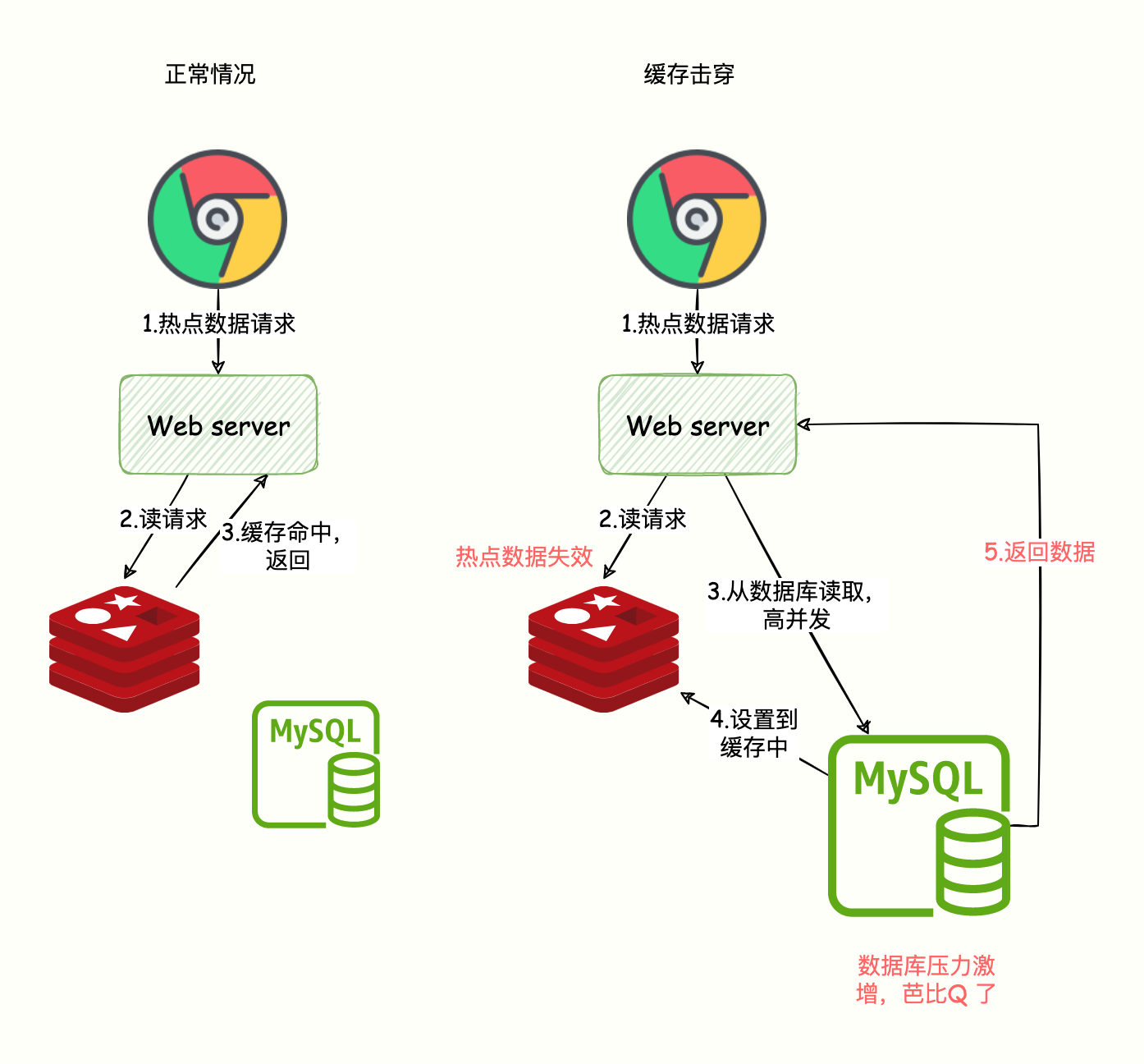
解决方案
过期时间 + 随机值
对于热点数据,我们不设置过期时间,这样就可以把请求都放在缓存中处理,充分把 Redis 高吞吐量性能利用起来。
或者过期时间再加一个随机值。
设计缓存的过期时间时,使用公式:过期时间=baes 时间+随机时间。
即相同业务数据写缓存时,在基础过期时间之上,再加一个随机的过期时间,让数据在未来一段时间内慢慢过期,避免瞬时全部过期,对 DB 造成过大压力
预热
预先把热门数据提前存入 Redis 中,并设热门数据的过期时间超大值。
使用锁
当发现缓存失效的时候,不是立即从数据库加载数据。
而是先获取分布式锁,获取锁成功才执行数据库查询和写数据到缓存的操作,获取锁失败,则说明当前有线程在执行数据库查询操作,当前线程睡眠一段时间在重试。
这样只让一个请求去数据库读取数据。
伪代码如下:
public Object getData(String id) {
String desc = redis.get(id);
// 缓存为空,过期了
if (desc == null) {
// 互斥锁,只有一个请求可以成功
if (redis(lockName)) {
try
// 从数据库取出数据
desc = getFromDB(id);
// 写到 Redis
redis.set(id, desc, 60 * 60 * 24);
} catch (Exception ex) {
LogHelper.error(ex);
} finally {
// 确保最后删除,释放锁
redis.del(lockName);
return desc;
}
} else {
// 否则睡眠200ms,接着获取锁
Thread.sleep(200);
return getData(id);
}
}
}
缓存穿透
缓存穿透:意味着有特殊请求在查询一个不存在的数据,即不数据存在 Redis 也不存在于数据库。
导致每次请求都会穿透到数据库,缓存成了摆设,对数据库产生很大压力从而影响正常服务。
如图所示:
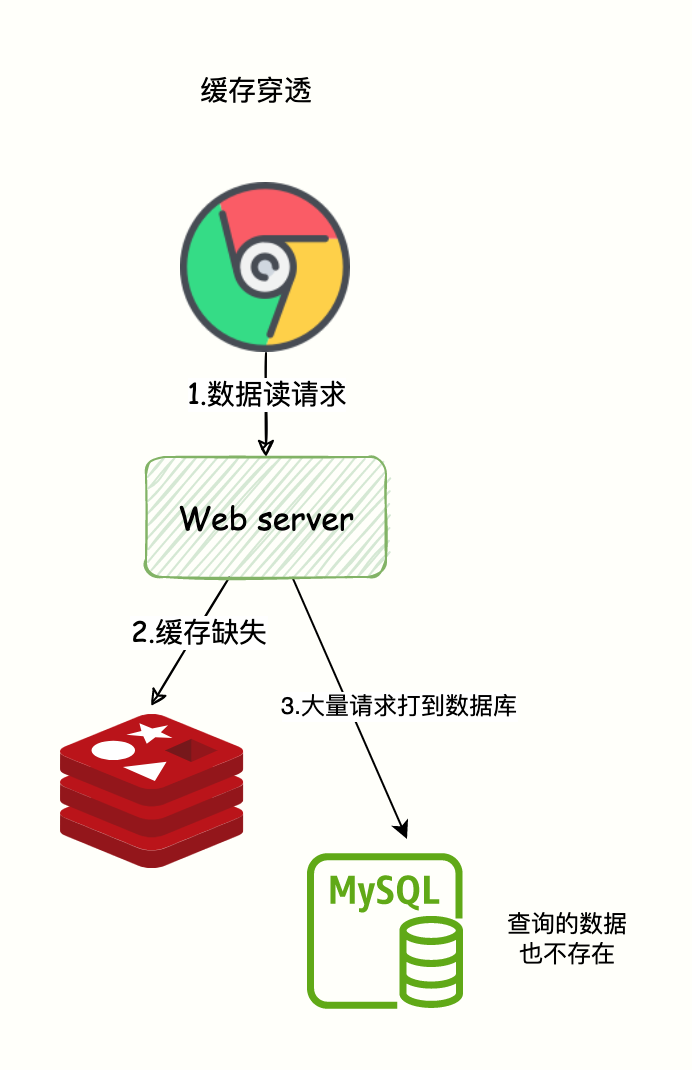
解决方案
- 缓存空值:当请求的数据不存在 Redis 也不存在数据库的时候,设置一个缺省值(比如:None)。当后续再次进行查询则直接返回空值或者缺省值。
- 布隆过滤器:在数据写入数据库的同时将这个 ID 同步到到布隆过滤器中,当请求的 id 不存在布隆过滤器中则说明该请求查询的数据一定没有在数据库中保存,就不要去数据库查询了。
BloomFilter 要缓存全量的 key,这就要求全量的 key 数量不大,10 亿 条数据以内最佳,因为 10 亿 条数据大概要占用 1.2GB 的内存。
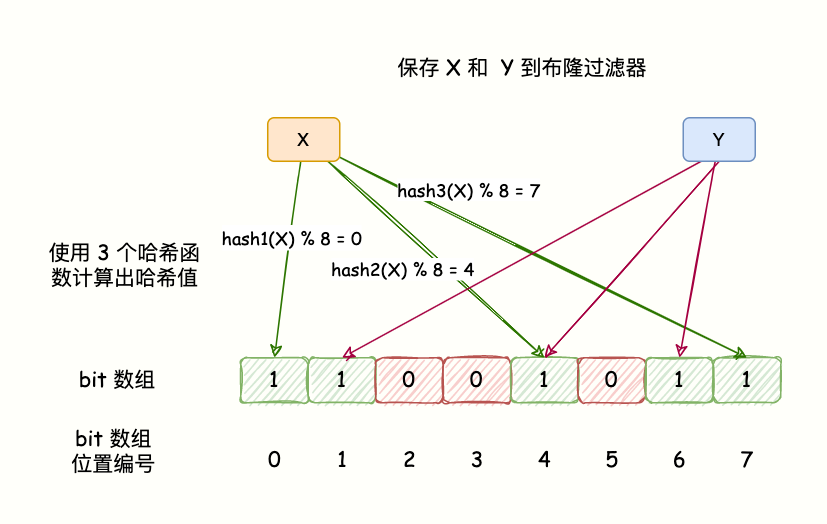
说下布隆过滤器的原理吧
BloomFilter 的算法是,首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
如下图所示:
哈希函数会出现碰撞,所以布隆过滤器会存在误判。
这里的误判率是指,BloomFilter 判断某个 key 存在,但它实际不存在的概率,因为它存的是 key 的 Hash 值,而非 key 的值。
所以有概率存在这样的 key,它们内容不同,但多次 Hash 后的 Hash 值都相同。
对于 BloomFilter 判断不存在的 key ,则是 100% 不存在的,反证法,如果这个 key 存在,那它每次 Hash 后对应的 Hash 值位置肯定是 1,而不会是 0。布隆过滤器判断存在不一定真的存在。
缓存雪崩
缓存雪崩指的是大量的请求无法在 Redis 缓存系统中处理,请求全部打到数据库,导致数据库压力激增,甚至宕机。
出现该原因主要有两种:
- 大量热点数据同时过期,导致大量请求需要查询数据库并写到缓存;
- Redis 故障宕机,缓存系统异常。
缓存大量数据同时过期
数据保存在缓存系统并设置了过期时间,但是由于在同时一刻,大量数据同时过期。
系统就把请求全部打到数据库获取数据,并发量大的话就会导致数据库压力激增。
缓存雪崩是发生在大量数据同时失效的场景,而缓存击穿(失效)是在某个热点数据失效的场景,这是他们最大的区别。
如下图:
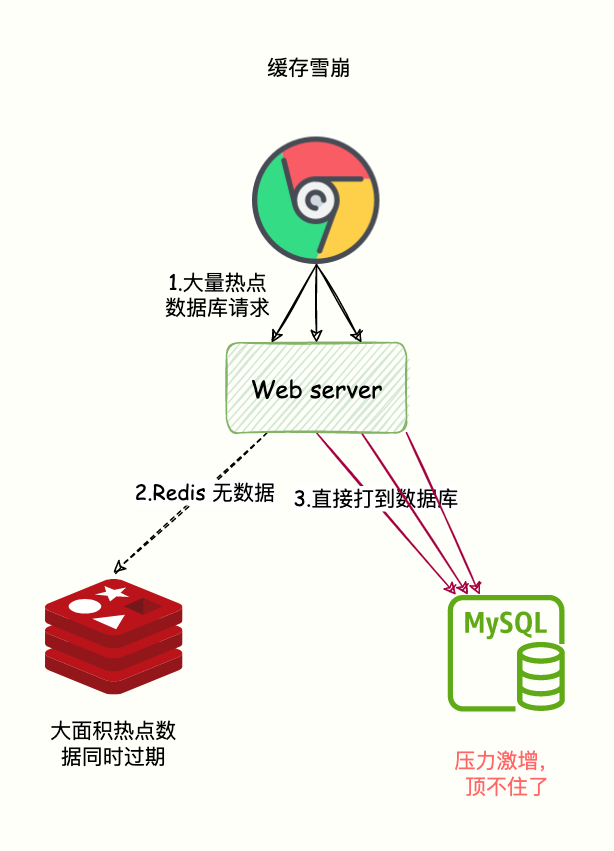
解决方案
过期时间添加随机值
要避免给大量的数据设置一样的过期时间,过期时间 = baes 时间+ 随机时间(较小的随机数,比如随机增加 1~5 分钟)。
这样一来,就不会导致同一时刻热点数据全部失效,同时过期时间差别也不会太大,既保证了相近时间失效,又能满足业务需求。
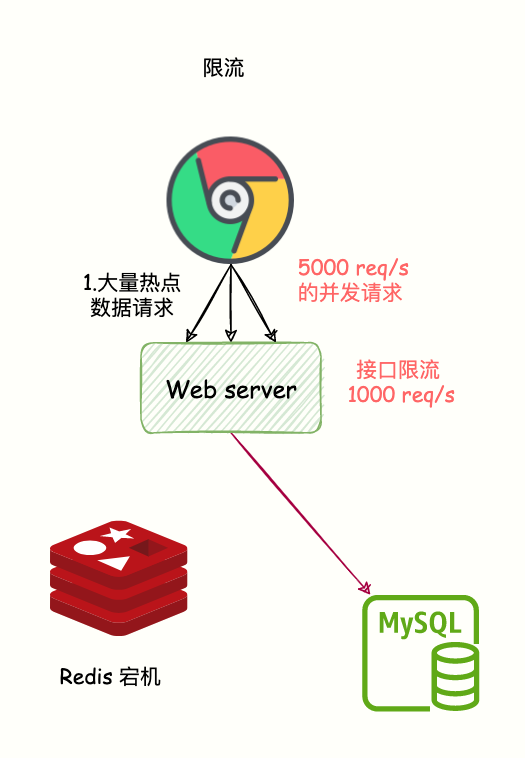
接口限流
当访问的不是核心数据的时候,在查询的方法上加上接口限流保护。比如设置 10000 req/s。
如果访问的是核心数据接口,缓存不存在允许从数据库中查询并设置到缓存中。
这样的话,只有部分请求会发送到数据库,减少了压力。
限流,就是指,我们在业务系统的请求入口前端控制每秒进入系统的请求数,避免过多的请求被发送到数据库。
如下图所示:
Redis 故障宕机
一个 Redis 实例能支撑 10 万的 QPS,而一个数据库实例只有 1000 QPS。
一旦 Redis 宕机,会导致大量请求打到数据库,从而发生缓存雪崩。
解决方案
对于缓存系统故障导致的缓存雪崩的解决方案有两种:
- 服务熔断和接口限流;
- 构建高可用缓存集群系统。
服务熔断和限流
在业务系统中,针对高并发的使用服务熔断来有损提供服务从而保证系统的可用性。
服务熔断就是当从缓存获取数据发现异常,则直接返回错误数据给前端,防止所有流量打到数据库导致宕机。
服务熔断和限流属于在发生了缓存雪崩,如何降低雪崩对数据库造成的影响的方案。
构建高可用的缓存集群
所以,缓存系统一定要构建一套 Redis 高可用集群,比如 《Redis 哨兵集群》或者 《Redis Cluster 集群》,如果 Redis 的主节点故障宕机了,从节点还可以切换成为主节点,继续提供缓存服务,避免了由于缓存实例宕机而导致的缓存雪崩问题。
总结
- 缓存穿透指的是数据库本就没有这个数据,请求直奔数据库,缓存系统形同虚设。
- 缓存击穿(失效)指的是数据库有数据,缓存本应该也有数据,但是缓存过期了,Redis 这层流量防护屏障被击穿了,请求直奔数据库。
- 缓存雪崩指的是大量的热点数据无法在 Redis 缓存中处理(大面积热点数据缓存失效、Redis 宕机),流量全部打到数据库,导致数据库极大压力。
参考资料
https://segmentfault.com/a/1190000039688578
https://cloud.tencent.com/developer/article/1824584
https://learn.lianglianglee.com/
Redis 缓存击穿(失效)、缓存穿透、缓存雪崩怎么解决?的更多相关文章
- Redis缓存穿透、缓存击穿以及缓存雪崩
作为一个内存数据库,redis也总是免不了有各种各样的问题,这篇文章主要是针对其中三个问题进行讲解:缓存穿透.缓存击穿和缓存雪崩.并给出一些解决方案.这三个问题是基本问题也是面试常问问题. 这篇文章我 ...
- Redis 缓存穿透、缓存击穿、缓存雪崩的解决方案
一.缓存雪崩 缓存雪崩表示:指缓存同一时间大面积失效或缓存重启又或者第一次启用缓存的情况下,导致请求跳过缓存直接请求数据库,造成数据库短时间内承受大量请求而崩掉. 解决方案: 方案一 缓存数据的过期时 ...
- 一天五道Java面试题----第九天(简述MySQL中索引类型对数据库的性能的影响--------->缓存雪崩、缓存穿透、缓存击穿)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1.简述MySQL中索引类型对数据库的性能的影响 2.RDB和AOF机制 3.Redis的过期键的删除策略 4.Redis ...
- 缓存穿透、雪崩、热点与Redis
(拼多多问:Redis雪崩解决办法) 导读:互联网系统中不可避免要大量用到缓存,在缓存的使用过程中,架构师需要注意哪些问题?本文以 Redis 为例,详细探讨了最关键的 3 个问题. 一.缓存穿透预防 ...
- 【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)
原文地址:https://blog.csdn.net/fouy_yun/article/details/81075432 前面的文章介绍了缓存的分类和使用的场景.通常情况下,缓存是加速系统响应的一种途 ...
- 使用singleflight防止缓存击穿(Java)
缓存击穿 在使用缓存时,我们往往是先根据key从缓存中取数据,如果拿不到就去数据源加载数据,写入缓存.但是在某些高并发的情况下,可能会出现缓存击穿的问题,比如一个存在的key,在缓存过期的一刻,同时有 ...
- Redis缓存穿透、缓存雪崩和缓存击穿理解
1.缓存穿透(不存在的商品访问数据造成压力) 缓存穿透,是指查询一个数据库一定不存在的数据.正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并 ...
- redis缓存雪崩,缓存穿透,缓存击穿的解决方法
一.缓存雪崩 缓存雪崩表示在某一时间段,缓存集中失效,导致请求全部走数据库,有可能搞垮数据库,使整个服务瘫痪. 使缓存集中失效的原因: 1.redis服务器挂掉了. 2.对缓存数据设置了相同的过期时间 ...
- Redis 缓存穿透,缓存击穿,缓存雪崩的解决方案分析
设计一个缓存系统,不得不要考虑的问题就是:缓存穿透.缓存击穿与失效时的雪崩效应. 一.什么样的数据适合缓存? 分析一个数据是否适合缓存,我们要从访问频率.读写比例.数据一致性等要求去分析. 二.什么 ...
随机推荐
- ArcMap操作随记(8)
1.构建两点之间连线 [构造视线] 2.编辑相邻多边形(边界等) [拓扑]工具条→[共享要素] 3.点要素空间分配 [创建泰森多边形]→[裁剪] 4.面要素空间分配 [要素转折点]→[创建泰森多边形] ...
- git 回滚方式
git push 命用于从将本地的分支版本上传到远程并合并. 命令格式如下: git push <远程主机名> <本地分支名>:<远程分支名> 如果本地分支名与远程 ...
- CVE-2014-3120 (命令执行漏洞)
环境配置 vulhub环境搭建 https://blog.csdn.net/qq_36374896/article/details/84102101 启动docker环境 cd vulhub-mast ...
- Java并发编程虚假唤醒问题(生产者和消费者关系)
何为虚假唤醒: 当一个条件满足时,很多线程都被唤醒了,但是只有其中部分是有用的唤醒,其它的唤醒都是无用功:比如买货:如果商品本来没有货物,突然进了一件商品,这是所有的线程都被唤醒了,但是只能一个人买, ...
- grafana初级入门
grafana初级入门 预备知识 Metrics.Tracing和Logging的区别 监控.链路追踪及日志作为实时监测系统运行状况,这三个领域都有对应的工具和解决方案. Metrics 监控指标的定 ...
- win10 doskey宏命令定义,类似于Linux的alias别名命令
doskey 命令别名=命令 例如:doskey echo2 = echo $1 这里的$1是占位符. 如果想删除,直接赋予空值即可:例如:doskey echo2= 总的来说把 https://do ...
- 请说说你对Struts2的拦截器的理解?
Struts2拦截器是在访问某个Action或Action的某个方法,字段之前或之后实施拦截,并且Struts2拦截器是可插拔的,拦截器是AOP的一种实现. 拦截器栈(Interceptor Stac ...
- Springboot添加静态资源映射addResourceHandlers,可实现url访问
@Configuration //public class WebMvcConfiger extends WebMvcConfigurerAdapter { public class WebMvcCo ...
- 为什么线程通信的方法 wait(), notify()和 notifyAll()被定 义在 Object 类里?
Java 的每个对象中都有一个锁(monitor,也可以成为监视器) 并且 wait(),notify() 等方法用于等待对象的锁或者通知其他线程对象的监视器可用.在 Java 的线程中 并没有可供任 ...
- SpringBoot使用JdbcTemplate批量保存
@Autowired DataSourceProperties dataSourceProperties; @Autowired ApplicationContext applicationConte ...