【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)
原文地址:https://blog.csdn.net/fouy_yun/article/details/81075432
前面的文章介绍了缓存的分类和使用的场景。通常情况下,缓存是加速系统响应的一种途径,通常情况下只有系统的部分数据。当请求了缓存中没有的数据时,这时候就会回源到DB里面。此时如果黑客故意对上面数据发起大量请求,则DB有可能会挂掉,这就是缓存击穿。当然缓存挂掉的话,正常的用户请求也有可能造成缓存击穿的效果。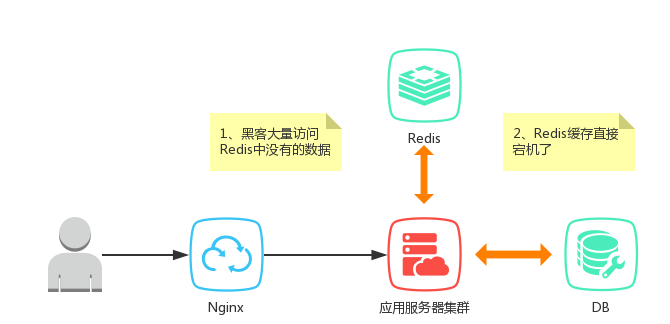
缓存中无值(未宕机)
互斥锁
我们最先想到的应该是加锁获取缓存。也就是当获取的value值为空时(这里的空表示缓存过期),先加锁,然后从数据库加载并放入缓存,最后释放锁。如果其他线程获取锁失败,则睡眠一段时间后重试。下面使用Redis的setnx来实现分布式锁,如下所示:
String get(String key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//其他线程休息50毫秒后重试
Thread.sleep(50);
get(key);
}
}
}

缓存永不过期
缓存永不过期的意思是:真正的缓存过期时间不有Redis控制,而是由程序代码控制。当获取数据时发现数据超时时,就需要发起一个异步请求去加载数据。这种策略的有点就是不会产生死锁等现象,但是有可能会造成缓存不一致的现象,但是笔者看来一般情况下都是可以适用的。
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
threadPool.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
缓存宕机
上面说到的场景是缓存依旧有效的,当Redis挂掉时,这个时候如何来应对大量的回源请求呢?先来说一种简单的方式:白名单。
白名单
白名单顾名思义就是:在缓存宕机之前的一段时间里,会将请求的数据在系统中的有无,记录在一个Map中。当缓存宕机后,首先在Map中判断是否含有数据,有则回源DB,没有的话就直接返回结果。
这种方式实现起来比较简单(Demo就不提供了),但是占用的内存空间比较庞大。如一个value是10字节,那么要存储大小为1亿的Map时,其所需的内存大小大约是:10 * 2 * 10e8 = 2G(假设Map的利用率为50%)。由此可见其对于一种类型的数据判断就需要一个 2G 的Map去操作,这种方式就不可行了。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:O(n), O(log n), O(n/k)。
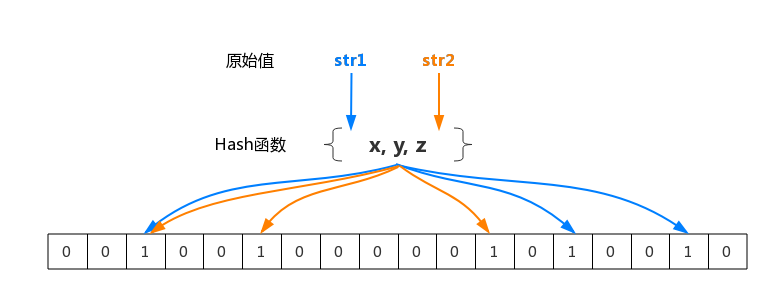
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
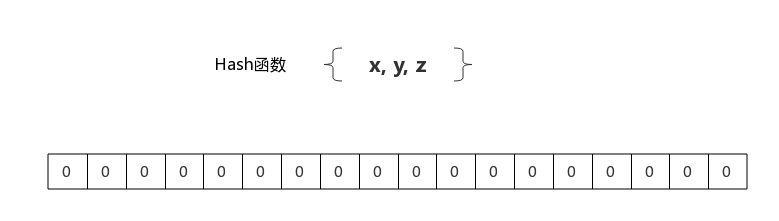
代码实现
在实际应用当中,我们不需要自己去实现BloomFilter。可以使用Guava提供的相关类库即可。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
判断一个元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
运行结果如下:
命中了
程序运行时间: 441616纳秒
自定义错误率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
运行结果如下:
误判的数量:94
对于缓存宕机的场景,使用白名单或者布隆过滤器都有可能会造成一定程度的误判。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能覆盖到所有DB中的数据,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用白名单/布隆过滤器作为应急的方式,这种情况也是可以接受的。
【面试突击】-缓存击穿(布隆过滤器 Bloom Filter)的更多相关文章
- [转载]布隆过滤器(Bloom Filter)
[转载]布隆过滤器(Bloom Filter) 这部分学习资料来源:https://www.youtube.com/watch?v=v7AzUcZ4XA4 Filter判断不在,那就是肯定不在:Fil ...
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
- 布隆过滤器 Bloom Filter 2
date: 2020-04-01 17:00:00 updated: 2020-04-01 17:00:00 Bloom Filter 布隆过滤器 之前的一版笔记 点此跳转 1. 什么是布隆过滤器 本 ...
- 布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器? 先来看几个比较常见的例子 字处理软件中,需要检查一个英语单词是否拼写正确 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上 在网络爬虫里,一个网址是否被访问过 yahoo, ...
- 布隆过滤器(Bloom Filter)-学习笔记-Java版代码(挖坑ing)
布隆过滤器解决"面试题: 如何建立一个十亿级别的哈希表,限制内存空间" "如何快速查询一个10亿大小的集合中的元素是否存在" 如题 布隆过滤器确实很神奇, 简单 ...
- 探索C#之布隆过滤器(Bloom filter)
阅读目录: 背景介绍 算法原理 误判率 BF改进 总结 背景介绍 Bloom filter(后面简称BF)是Bloom在1970年提出的二进制向量数据结构.通俗来说就是在大数据集合下高效判断某个成员是 ...
随机推荐
- asp.netCore3.0区域和路由配置变化
一.MVC 服务注册 ASP.NET Core 3.0 添加了用于注册内部的 MVC 方案的新选项Startup.ConfigureServices.三个新的顶级扩展方法与 MVC 方案上IServi ...
- tinylib
tinylib.h /* -------------------------------------------------------------------------------- oooo ` ...
- TP 控制器和模型里面order 写法不同
控制器: Db::table('think_user')->where('status=1')->order('id desc')->limit(5)->select(); ...
- Kafka安装教程(详细过程)
安装前期准备: 1,准备三个节点(根据自己需求决定) 2,三个节点上安装好zookeeper(也可以使用kafka自带的zookeeper) 3,关闭防火墙 chkconfig iptables o ...
- Linux安装fcitx输入法(命令安装)
Linux安装fcitx输入法(命令安装) 打开终端安装输入法 sudo apt-get install im-switch libapt-pkg-perl fcitx fcitx-table-w ...
- Google软件测试之道笔记与总结
[本文出自天外归云的博客园] 以下内容除了笔记还有总结,有个人理解的成分在内. 第一章笔记与总结 1. 开发人员也承担了质量的重任,质量从来就不仅仅是一些测试人员的问题.头衔有测试字样的人的任务是让那 ...
- ireport5.6.0分组显示
一,ireport中分组 二,java调用实现分组 一,ireport中分组: 1,新建模板文件,纸张随意,名称随意,路径随意 2,连接要分组的数据源 3,添加测试表和数据 CREATE TABLE ...
- (十)redis源码解读
一.redis工作机制 redis是 单线程,所有命令(set,get等)都会加入到队列中,然后一个个执行. 二.为什么redis速度快? 1.基于内存 2.redis协议resp 简单.可读.效率高 ...
- phpspreadsheet 中文文档(七)技巧和诀窍
2019年10月11日14:08:35 以下页面为您提供了一些使用广泛的PhpSpreadsheet食谱.请注意,这些文件没有提供有关特定PhpSpreadsheet API函数的完整文档,而只是一个 ...
- aix如何将history输出所有命令导出到文本文件
more .sh_history cat .sh_history > mylogfile.txt